







RAG(Retrieval-Augmented Generation,检索增强生成)由Facebook在2020年发表的论文
Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
语言模型存在幻觉
- 由于知识缺乏,没有实时增量信息
- 没有具体领域的拓展信息
RAG架构
RAG架构包含:参数记忆(预训练语言模型作为生成器)与非参数记忆(预训练文档检索器)两部分
非参数记忆部分包含两个子部分:
查询编码器(Query Encoder):其将问题进行向量化
文档索引(Document Index):通过另一个编码器将文档进行向量化,并构建文档向量索引
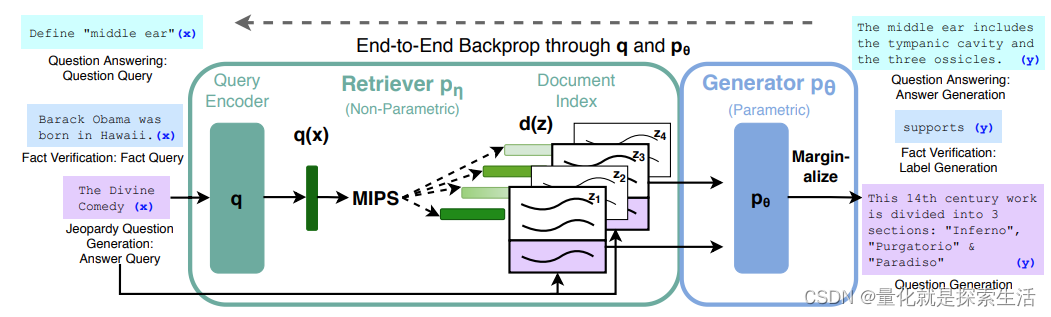
问题描述
对于一个查询序列 x x x,使用Maximum Inner Product Search (MIPS) 寻找最接近的 K K K个文本 z i z_i zi。为了得到最终结果 y y y,
检索器:
p
η
(
z
∣
x
)
p_{\eta}(z|x)
pη(z∣x)返回文本
z
z
z与查询
x
x
x的相似性
生成器:
p
θ
(
y
i
∣
x
,
z
.
y
1
:
i
−
1
)
p_{\theta}(y_i|x,z.y_{1:i-1})
pθ(yi∣x,z.y1:i−1),根据文本
z
z
z与查询
x
x
x以及前
i
−
1
i-1
i−1个token,生成下一个token
端到端的RAG模型旨在同时训练检索器和生成器
端到端模型
RAG-Sequence Model
p
RAG-Sequence
(
y
∣
x
)
≈
∑
z
∈
top
−
k
(
p
(
⋅
∣
x
)
)
p
η
(
z
∣
x
)
p
θ
(
y
∣
x
,
z
)
=
∑
z
∈
top
−
k
(
p
(
⋅
∣
x
)
)
p
η
(
z
∣
x
)
∏
i
N
p
θ
(
y
i
∣
x
,
z
,
y
1
:
i
−
1
)
p_{\text {RAG-Sequence }}(y \mid x) \approx \sum_{z \in \operatorname{top}-k(p(\cdot \mid x))} p_\eta(z \mid x) p_\theta(y \mid x, z)=\sum_{z \in \operatorname{top}-k(p(\cdot \mid x))} p_\eta(z \mid x) \prod_i^N p_\theta\left(y_i \mid x, z, y_{1: i-1}\right)
pRAG-Sequence (y∣x)≈z∈top−k(p(⋅∣x))∑pη(z∣x)pθ(y∣x,z)=z∈top−k(p(⋅∣x))∑pη(z∣x)i∏Npθ(yi∣x,z,y1:i−1)
这个模型使用相同的检索文档来预测目标序列中的所有词元 (token)。它在整个生成过程中依赖单个文档,以保持一致性。
RAG-Token Model
p
RAG-Token
(
y
∣
x
)
≈
∏
i
N
∑
z
∈
top
−
k
(
p
(
⋅
∣
x
)
)
p
η
(
z
∣
x
)
p
θ
(
y
i
∣
x
,
z
,
y
1
:
i
−
1
)
p_{\text {RAG-Token }}(y \mid x) \approx \prod_i^N \sum_{z \in \text { top }-k(p(\cdot \mid x))} p_\eta(z \mid x) p_\theta\left(y_i \mid x, z, y_{1: i-1}\right)
pRAG-Token (y∣x)≈i∏Nz∈ top −k(p(⋅∣x))∑pη(z∣x)pθ(yi∣x,z,y1:i−1)
在 RAG-Token 模型中,目标序列中的不同词元可以根据不同的文档进行预测。这提供了更大的灵活性,因为每个词元都可以从最相关的上下文中获益。
检索器
使用BERT——BASE模型向量化
d
(
z
)
=
B
E
R
T
d
(
z
)
,
q
(
x
)
=
B
E
R
T
q
(
x
)
d(z)=BERT_d(z),q(x)=BERT_q(x)
d(z)=BERTd(z),q(x)=BERTq(x)
p
η
(
z
∣
x
)
∝
exp
(
d
(
z
)
⊤
q
(
x
)
)
p_\eta(z \mid x) \propto \exp \left(\mathbf{d}(z)^{\top} \mathbf{q}(x)\right)
pη(z∣x)∝exp(d(z)⊤q(x))
通过最大内积搜索计算相似度
生成器
使用encoder-decoder架构的BART_large,400M
训练
同时训练(微调)检索器和生成器,对于选用哪一篇文本没有任何监督。
样本为输入输出对
目标位最小化负对数似然函数
m
i
n
i
m
i
z
e
(
∑
j
−
log
p
(
y
j
∣
x
j
)
)
minimize(\sum_j{-\text{log} \ {p(y_j|x_j)}})
minimize(j∑−log p(yj∣xj))
使用随机梯度下降和Adam优化器
为了减低训练负载,冻结文档检索器BERT_d,仅训练BERT_q 和 BART
解码过程
RAG-Token
由于模型是基于token逐次训练,得知每一步的概率。可以通过标准的beam search算法解码输出结果
Beam Search
对于贪心算法和全搜索算法的折中
贪心每一步选最大的一个
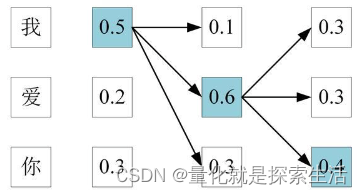
Beam Search每一步选最大的N个
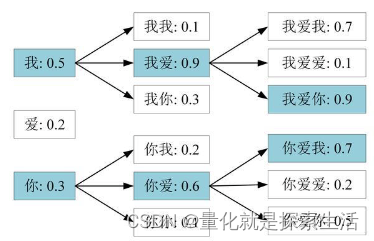
算法描述

RAG-Sequence
不对每个token做beam search,对每个documents beam search。及评估每句话(sequence)被每个documents生成的概率。
















 2797
2797











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











