







拍拍贷“魔镜风控系统”从平均400个数据维度评估用户当前的信用状态,给每个借款人打出当前状态的信用分,在此基础上再结合新发标的信息,打出对于每个标的6个月内逾期率的预测,为投资人供关键的决策依据。本次竞赛目标是根据用户历史行为数据来预测用户在未来6个月内是否会逾期还款的概率。

01
项目总体思路
本文将为您介绍我们在数据处理过程中所采用的方法,从数据清洗到特征工程再到特征选择,最终进行模型设计与分析。在数据清洗阶段,我们采用多维度处理缺失值、剔除离群点以及处理字符和空格等方法。随后,我们进行特征工程,包括构建地理位置信息特征、成交时间特征、类别特征编码、组合特征构建以及提取UpdateInfo和LogInfo表的特征。接着,我们使用xgboost进行特征选择,该过程会对特征进行排序以确定其重要性。考虑到数据存在类别不平衡现象,我们采用代价敏感学习和过采样两种方法进行处理,其中重点介绍过采样方法的应用。最后,我们选择了逻辑回归模型、数据挖掘比赛中的强力选手xgboost以及大规模svm方法进行模型设计与分析,并取得了令人满意的结果。此外,我们还探索了模型融合的方法。
1. 数据清洗
在征信领域,用户信息的完善程度对其信用评级有重要影响。一位信息完善程度为100%的用户相比信息完善程度只有50%的用户,更容易通过审核并获得借款。为了更好地处理这一问题,我们进行了多维度的缺失值分析和处理。我们首先按照属性统计了每列缺失值的数量,并进一步计算了各列的缺失比率。下图(图 1)展示了含有缺失值的属性及其相应的缺失比率。
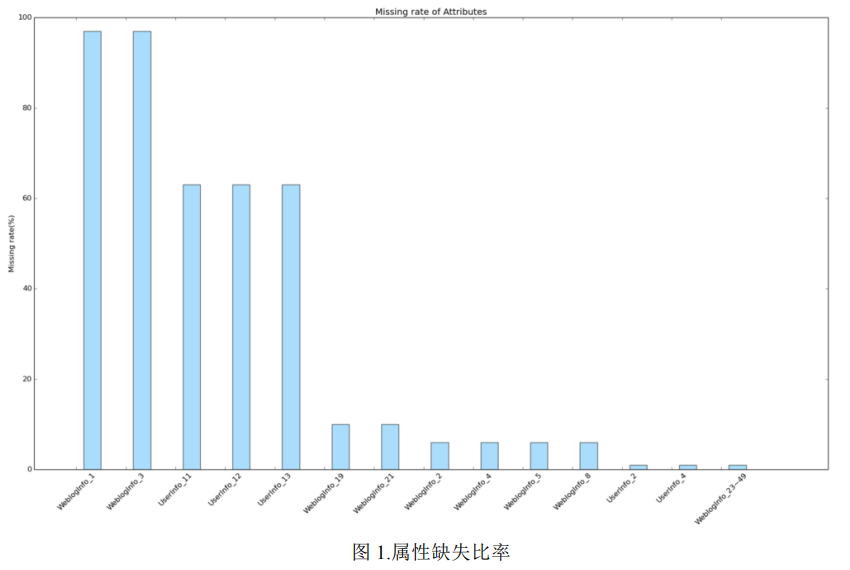
根据分析结果,发现WeblogInfo_1和WeblogInfo_3的缺失值比率高达97%,这两列属性基本上没有携带有用的信息,因此我们可以直接剔除它们。而UserInfo_11、UserInfo_12和UserInfo_13的缺失值比率为63%,这三列属性是类别型的,我们可以将缺失值用-1填充,将其视为另一种类别。至于其他缺失值比率较小的数值型属性,我们可以使用中值进行填充。
接下来,我们按照每个样本的属性缺失值个数进行统计,并将其从小到大排序。以序号为横坐标,缺失值个数为纵坐标,绘制了下图(图2)中
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 172
172

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









