







▍目录
一、简介
-
风控信用评分卡简介
-
Scorecardpy库简介
二、目标定义与数据准备
-
目标定义
-
数据准备
三、安装scorecardpy包
四、数据检查
五、数据筛选
六、数据划分
七、变量分箱
-
卡方分箱
-
手动调整分箱
八、建立模型
-
相关性分析
-
多重共线性检验VIF
-
KS和AUC
-
评分映射
-
PSI稳定性指标
九、关键指标说明
-
WOE值
-
IV值
-
逻辑回归
-
KS值
-
PSI
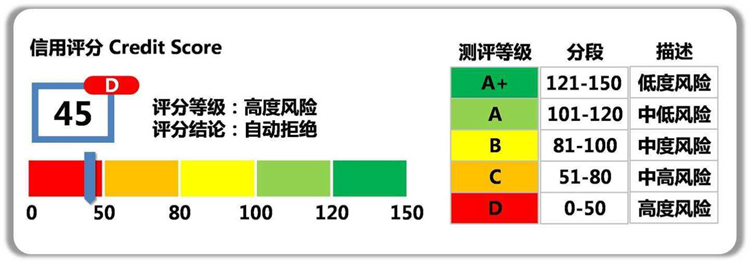
▍风控信用评分卡简介
通过运用数据挖掘算法,信贷风控系统可以像个"预言家"一样准确地预测借款人的还款表现。它通过分析借款人的个人信息、历史还款记录、职业稳定性等多个因素,为金融机构提供一个科学且可靠的参考,以决定是否放贷。
有了信贷风控系统的帮助,金融机构能更好地掌握风险,防范不良贷款的风险,同时也能更快速地为借款人提供贷款服务。这种高效率的金融服务不仅促进了经济发展,也方便了人们的生活。
总而言之,信贷风控在互联网时代发挥着至关重要的作用。基于大数据和数据挖掘算法,它成为金融业务决策的智慧之选,为金融机构和借款人提供了更可靠、更高效的信贷服务。

▍评分卡ABC卡应用场景介绍
业界通常的做法是基于挖掘多维度的特征建立一套可解释及效果稳定的规则及风控模型对每笔订单/用户/行为做出判断决策。
申请评分卡A卡在贷前阶段起着非常重要的作用。借助A卡模型,银行或金融机构能够根据申请人的个人信息和历史数据,对其进行风险评估。这种评估能够帮助金融机构判断借款人是否具备偿还贷款的能力和意愿。通过综合评分,A卡模型能够为贷款决策提供科学依据,从而减少不良贷款的风险。
此外,还有贷中行为评分卡B卡和催收评分卡C卡等模型。B卡模型用于对贷款期间借款人的行为进行评估,帮助监控贷款的风险状况。C卡模型则专注于催收阶段,用于评估借款人的还款意愿和能力,以便制定相应的催收策略。
除了上述评分卡模型,还有反欺诈模型等其他模型。反欺诈模型是为了应对欺诈行为而设计,它利用各种数据分析技术来识别和预防欺诈行为,保护金融机构和借款人的利益。
A卡申请评分模型主要在于预测申请时(申请信用卡、申请贷款)对申请人进行量化评估。
B卡行为评分模型在于预测贷中时点(获得贷款、信用卡的使用期间)未来一定时间内逾期的概率。
C卡催收评分模型在于预测已经逾期并进入催收阶段后未来一定时间内还款的概率。

一个预测能力强的特征,对于模型和规则都是特别重要的。比如申请评分卡--A卡,主要可以归到以下3方面特征:
-
1、信贷历史类:信贷交易次数及额度、收入负债比、查询征信次数、信贷历史长度、新开信贷账户数、额度使用率、逾期次数及额度、信贷产品类型、被追偿信息。用来预测还款能力及意愿的信息
-
2、基本信息及交易记录类:年龄、婚姻状况、学历、工作类型、年薪、工资收入、存款股票、车房资产情况、公积金及缴税、非信贷交易流水等记录(这类主要是从还款能力上面综合考量的。还可以结合多方核验资料的真伪以及共用像手机号、身份证号等团伙欺诈信息,用来鉴别欺诈风险)
-
3、公共负面记录类:例如破产负债、民事判决、行政处罚、法院强制执行、涉赌涉诈黑名单、公安不良等(这类特征不一定能拿得到数据,且通常缺失度比较高,对模型贡献一般,更多的是从还款意愿/欺诈维度的考虑)
▍Scorecardpy库简介
-常用的评分卡建模Python包有Toad和scorecardpy,二者相比,scorecardpy更加轻量且依赖较少,可以满足大多数场景下的建模
-scorecardpy是由谢士晨博士开发,目标是通过提供一些常见任务的功能,使信用风险评分模型的开发更加轻松有效
-scorecardpy的github地址:https://github.com/ShichenXie/scorecardpy
-该包针对模型中的关键步骤提供了现成的函数,如:
-
数据划分(split_df)
-
过滤变量(var_filter())
-
决策树分箱(woebin, woebin_plot, woebin_adj, woebin_ply)
-
评分转换(scorecard, scorecard_ply)
-
模型评估(perf_eva, perf_psi)
▍目标定义与数据准备
1.好坏样本定义:
风控模型的预测目标一般是指判断某个客户是否为坏,一般通过滚动率分析定义坏,如M2或M3 (M:Month on Book 账龄,M2即逾期60以上或M3即逾期90天以上)。
2.时间窗口确定:
在运用的过程中,不能简单地将坏客户定为1,好客户定义为0。需要结合时间点与业务指标进行综合判断。
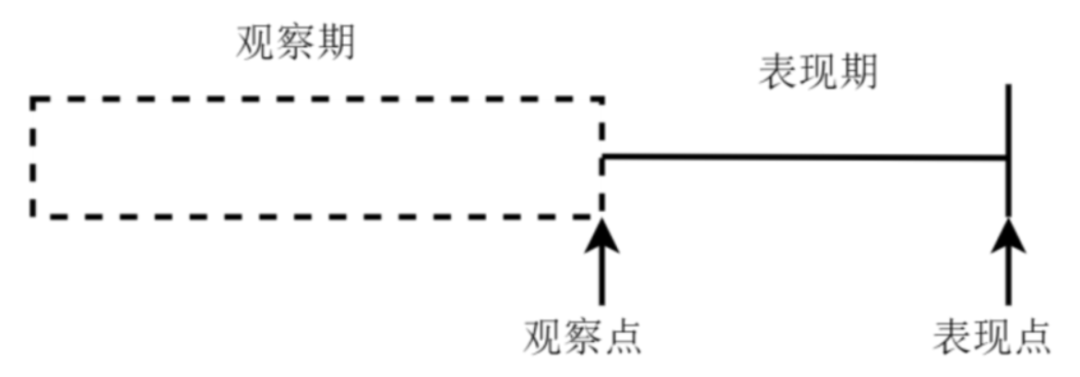
3.观察点/观察期:
观察点:该点并不是一个具体的时间点,而是一个时间段,在该时间段的客户样本将作为建模的历史数据
观察期:此阶段主要用以生成用户特征的时间区间,不宜过长也不宜过短。若区间过长可能导致大批样本无法进入模型;过短可能会导致无法生成足够多有效的时间切片变量
4.表现点/表现期:
表现期:用以定义用户好坏的时间段,一般是6个月到1年左右,不宜过短,以保证样本群体分类的稳定性,使客户的风险充分表露出来
表现点:截止到此时间点的客户被分类成“好客户”和“坏客户”
5.数据:
使用scorecardpy自带的German Credit数据集,字段如下:
status of existing checking account 现有支票帐户状况
duration in month 还了多久贷款了/债务时间
3.credit history 信贷历史
purpose 贷款目的
credit amount 贷款剩余金额
6.savings account and bonds 存款账户
present employment since 截止到现在的就职年限
installment rate in percentage of disposable income 分期付款占可支配收入的百分比
personal status and sex 性别
other debtors or guarantors 担保人
a present residence since 居住地
property 资产
age in years 贷款时的年纪
other installment plans 分期付款计划
housing 无房/租房/自有房
number of existing credits at this bank 已有的银行卡数量
job 工作
number of people being liable to provide maintenance for 可还款人数
telephone 电话
foreign worker 是否为外籍员工
creditability 信用好坏
▍数据安装与检查
pip install scorecardpy
1.检查缺失值,看缺失值占比情况判断删除还是保留
2.删掉对建模没有意义的行列,例如tel
3.查看数据信息格式:数据是由int64,category,object类型的数据组成,category类型的数据具有局限性,此处转化为object
# -*- coding:utf-8 -*-
import scorecardpy as sc
import pandas as pd
import numpy as np
#scorecardpy自带数据
dat = sc.germancredit()
#查看数据行列
print("数据行列",dat.shape)
print("随机抽取5行数据\n",dat.sample(5))
#统计每个变量的缺失占比情况
result1 = (dat.isnull().sum()/dat.shape[0]).map(lambda x:"{:.2%}".format(x))
print(result1)
#other_debtors_or_guarantors 缺失值过多,在建模时失去效用故删除
#other_installment_plans 这一列缺失占比也较高也可以删除
dat["other_installment_plans"].value_counts()
#telephone 对建模没有太大意义故删除,但收集数据时也要确保其是否被填写以保证客户真实性及后续操作,此处不讨论。
#删除三项内容
dat = dat.drop(columns=["other_debtors_or_guarantors","other_installment_plans","telephone"])
#查看数据的信息
dat.info()Data columns (total 18 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 status_of_existing_checking_account 1000 non-null category 1 duration_in_month 1000 non-null int64 2 credit_history 1000 non-null category 3 purpose 1000 non-null object 4 credit_amount 1000 non-null int64 5 savings_account_and_bonds 1000 non-null category 6 present_employment_since 1000 non-null category 7 installment_rate_in_percentage_of_disposable_income 1000 non-null int64 8 personal_status_and_sex 1000 non-null category 9 present_residence_since 1000 non-null int64 10 property 1000 non-null category 11 age_in_years 1000 non-null int64 12 housing 1000 non-null category 13 number_of_existing_credits_at_this_bank 1000 non-null int64 14 job 1000 non-null category 15 number_of_people_being_liable_to_provide_maintenance_for 1000 non-null int64 16 foreign_worker 1000 non-null category 17 creditability 1000 non-null object
▍数据筛选
# 经过人工筛选后,利用sc.var_filter自动判断数据建模可用性 dt_s = sc.var_filter(dat,y="creditability",iv_limit=0.02)
print(dat.shape) #手动删除后数据
print(dt_s.shape) #过滤变量后数据
(1000, 18)
(1000, 12)▍数据划分
train,test = sc.split_df(dt=dt_s,y="creditability").values() #方法:随机抽样
#训练数据y的统计: train.creditability.value_counts()
▍变量卡方分箱
#scorecardpy默认使用决策树分箱,method=‘tree’
#这里使用卡方分箱,method=‘chimerge’
#返回的是一个字典数据,用pandas.concat()查看所有数据
bins = sc.woebin(dt_s,y="creditability",method="chimerge")
bins_df = pd.concat(bins).reset_index().drop(columns="level_0")
#制作变量分布图,此处把筛选后的11个变量均制作变量分布图后再进一步筛选可用变量
import matplotlib.pyplot as plt
sc.woebin_plot(bins["duration_in_month"])
sc.woebin_plot(bins["installment_rate_in_percentage_of_disposable_income"])
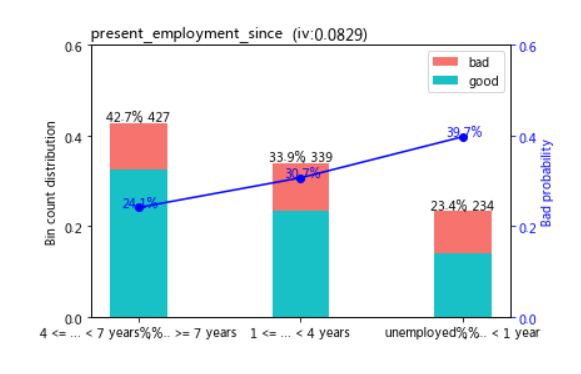
sc.woebin_plot(bins["present_employment_since"])
sc.woebin_plot(bins["savings_account_and_bonds"])
sc.woebin_plot(bins["purpose"])
sc.woebin_plot(bins["status_of_existing_checking_account"])
sc.woebin_plot(bins["credit_history"])
sc.woebin_plot(bins["housing"])
sc.woebin_plot(bins["property"])
# 此步骤需检查分箱的单调性、分箱数、IV值、每一箱是否合理等,再进行下一步的手动调整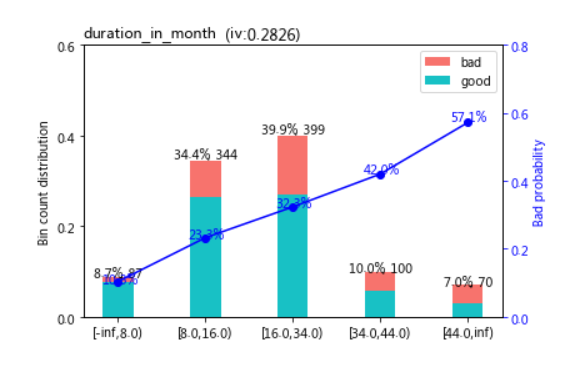
▍手动分箱
#分箱调整
#scorecardpy可以自定义分箱,也可以自动分箱。此处选择手动分箱。手动分箱根据业务经验)
# 手动分箱
break_adj = {
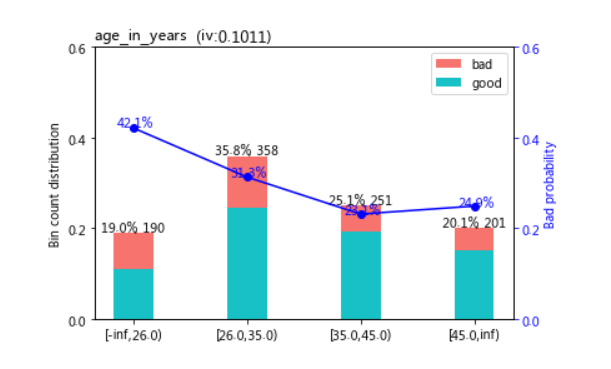
'age_in_years':[26,35,45],
'credit_amount':[750,3000,5500]
}
bins_adj = sc.woebin(dt_s,y="creditability",breaks_list=break_adj) #调整后数据
bins_adj_df = pd.concat(bins_adj).reset_index().drop(columns="level_0")
bins_adj_df[bins_adj_df.variable.isin(["age_in_years",'credit_amount'])]
sc.woebin_plot(bins_adj["age_in_years"])
sc.woebin_plot(bins_adj['credit_amount'])
▍建立模型
-风控信用评分模型的目标,是解决对好人坏人区分的二分类问题,且对解释性、计算速度与可追溯性上要求较高,所以业界普遍选用逻辑回归模型建立风控评分卡
-逻辑回归的优点:结构简单;计算快;可解释性强;分类结果是0-1之间的概率数字;
#逻辑回归,逻辑回归在金融建模中应用广泛
from sklearn.linear_model import LogisticRegression
y_train = train_woe.loc[:,"creditability"]
X_train =train_woe.loc[:,train_woe.columns!="creditability"]
y_test = test_woe.loc[:,"creditability"]
X_test = test_woe.loc[:,test_woe.columns!="creditability"]
lr=LogisticRegression(penalty='l1',C=0.9,solver='saga',n_jobs=-1)
lr.fit(X_train,y_train)
LogisticRegression(C=0.9, n_jobs=-1, penalty='l1', solver='saga')[[0.7477907 0.77429024 0.03820958 0.33340333 0.42839855 0.33196916 1.18999712 0.51742719 0.62251866 0.6756973 0.98183774]]
▍相关性分析
1.相关性是进行回归分析的前提之一。如果自变量和因变量之间没有相关性,那么进行回归分析可能没有意义。相关性可以帮助我们判断自变量是否对因变量有一定的解释能力。
2数据相关性过大可能意味着存在共线性。共线性是指自变量之间存在高度相关性,使得回归模型的稳定性降低,参数估计变得不可靠。当自变量之间存在强烈的线性相关性时,我们可能需要考虑采取一些方法来处理共线性问题,例如进行特征选择或使用正则化方法。
3.相关分析可以用来了解变量之间的共变趋势,但并不能确定因果关系。相关性只表明两个变量之间存在某种关联程度,但不能明确指出是哪个变量影响了另一个变量。而回归分析可以基于假设对自变量与因变量之间的具体作用关系进行验证。通过回归分析,我们可以得出变量之间的具体方向性关系,以揭示自变量对因变量的影响程度。
▍多重共线性检验VIF
多重共线性是指在机器学习模型中存在强相关性或线性依赖关系的变量。当多个特征之间存在高度相关性时,就会出现多重共线性的情况。
在模型中,多重共线性可能会导致一些问题。首先,它会降低模型的稳定性,使得模型对输入数据中的小变化非常敏感。其次,共线性会使得模型系数估计不准确,使我们很难解释特征与目标之间的关系。此外,共线性还可能导致模型的解释性下降,因为我们很难确定哪些特征对模型预测的贡献最大。
为了解决多重共线性问题,我们可以采取以下措施:
1. 特征选择: 通过选择与目标变量相关性较高、与其他特征相关性较低的特征来减少共线性的影响。
2. 正则化: 使用正则化技术如L1正则化(Lasso)或L2正则化(Ridge)可以通过惩罚系数来减少共线性对模型的影响。
3. 主成分分析(PCA): 使用PCA技术可以将原始的高维特征转换为一组无关的低维特征,从而降低共线性的影响。
4. 增加样本量: 增加数据样本量可以减少多重共线性的影响,尤其是当样本量比较小时。
通过采取上述措施,我们可以在机器学习模型中更好地处理多重共线性问题,提高模型的性能和稳定性。
# VIF越高,多重共线性的影响越严重
# 在金融风险中我们使用经验法则:若VIF>4,则我们认为存在多重共线性
def checkVIF(df):
from statsmodels.stats.outliers_influence import variance_inflation_factor
name = df.columns
x = np.matrix(df)
VIF_list = [variance_inflation_factor(x,i) for i in range(x.shape[1])]
VIF = pd.DataFrame({'feature':name,"VIF":VIF_list})
max_VIF = max(VIF_list)
print(max_VIF)
return VIF
checkVIF(train_woe)#计算训练集的VIF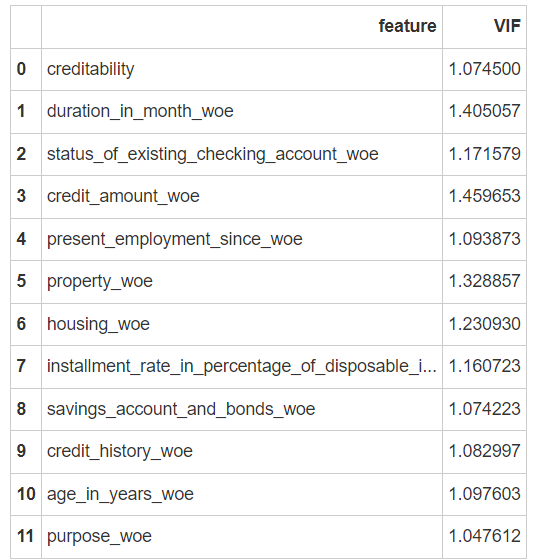
▍KS和AUC
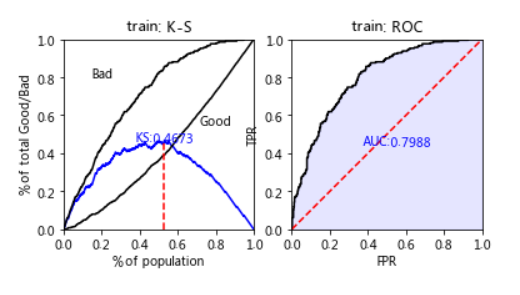
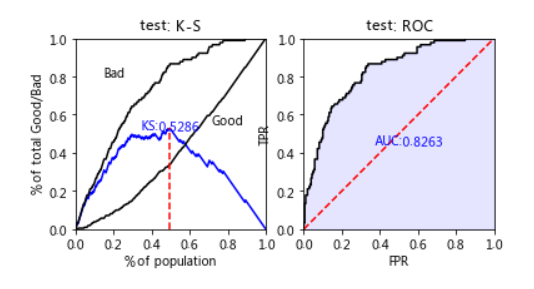
K-S曲线(Kolmogorov-Smirnov Curve):
-
为蓝色KS曲线上的最大值,KS值越大,模型区分能力越强
-
风控模型中的KS值一般在0.2~0.4之间
-
AUC(Area Under Curve):
-
ROC曲线下的面积,介于0.1和1之间,AUC越大模型性能越好
train_pred = lr.predict_proba(X_train)[:,1] test_pred = lr.predict_proba(X_test)[:,1] train_perf = sc.perf_eva(y_train,train_pred,title="train") test_perf = sc.perf_eva(y_test,test_pred,title="test")
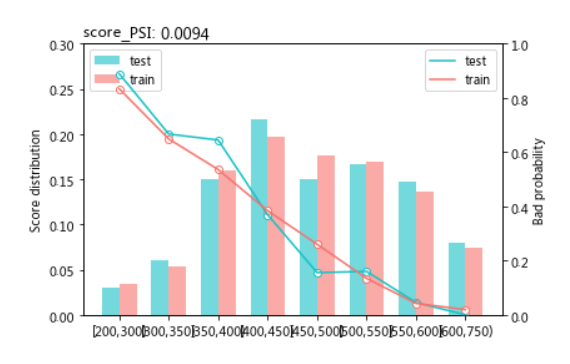
PSI稳定性指标
-
PSI越小,说明模型越稳定
-
通常PSI需小于0.1,则模型稳定性较好
sc.perf_psi(
score = {'train':train_score,'test':test_score},
label = {'train':y_train,'test':y_test}
)
▍关键指标说明
1.WOE值
| WOE(Weight of Evidence)证据权重的应用: 处理缺失值:当数据源没有100%覆盖时,那就会存在缺失值,此时可以把null单独作为一个分箱。这点在分数据源建模时非常有用,可以有效将覆盖率哪怕只有20%的数据源利用起来 处理异常值:当数据中存在离群点时,可以把其通过分箱离散化处理,从而提高变量的鲁棒性(抗干扰能力)。例如,age若出现200这种异常值,可分入“age > 60”这个分箱里,排除影响 业务解释性:我们习惯于线性判断变量的作用,当x越来越大,y就越来越大。但实际x与y之间经常存在着非线性关系,此时可经过WOE变换 |
2.IV值
| 判断标准: (1)IV<0.03:无预测能力 (2)0.03-0.09:低 (3)0.1-0.29:中 (4)0.3-0.49:高 (5)IV>=0.5:极高 一般可以选择IV值在0.1~0.49范围内的变量 |
3.逻辑回归
| 线性函数是最简单的方程 y = ax +b。通过一个权重a和一个常数项b,最终和变量x组合得到了预测值y。对于线性可分的变量中,我们会设定一个阈值来判断我们预测的样本数据哪一类。例如 我们得到一组y值【1,2,3,4,5,6,7,8,9】。此时我们通过设定阈值 = 5, 当y <= 5时,认定为0,y>5 时,认定为1,这样就做了一个简单的分类模型。 |
4.逻辑回归的拟合函数
| 逻辑回归的拟合函数是 sigmoid函数。(该函数也常用于神经网络的激活函数,除此之外还有tanh,relu,softmax等)。 函数公式中的 z 即为 ax + b。 这样,sigmoid函数就将跃阶函数转变为平滑的S形曲线,取值范围则被映射至【0,1】区间,方便我们通过该模型更好的做分类预测。 |
5.KS值
| KS(Kolmogorov-Smirnov)值衡量的是好坏样本累计分部之间的差值 好坏样本累计差异越大,KS指标越大,模型的风险区分能力越强 判断标准: (1)KS<0.2:不建议采用 (2)0.2-0.4:较好 (3)0.41-0.5:良好 (4)0.51-0.6:很强 (5)0.61-0.75:非常强 (6)KS>0.75:能力高但疑似有误 |
6.PSI
| PSI是计算模型预测出来的每个分数段内好坏客户的比例与实际样本好坏客户分布的差异性,差异越小越好 评判标准:一般认为 (1)PSI小于0.1:模型稳定性很高 (2)0.1-0.25:一般 (3)PSI大于0.25:模型稳定性差,建议重做 |














 5703
5703











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









