







B站 刘二大人老师的课程代码
PyTorch 深度学习实践
1.回顾
import torch
# 样本数据
x_data = [1.0, 2.0, 3.0] # 输入样本
y_data = [2.0, 4.0, 6.0] # 输出样本
w = torch.tensor([1.0]) #权重初始值
w.requires_grad = True #计算梯度,默认不计算
def forward(x):
return x * w
def loss(x, y): #构建计算图
y_pred = forward(x)
return (y_pred - y) ** 2
print("predict (before training)", 4, forward(4).item())
for epoch in range(100):
for x, y in zip(x_data, y_data):
l = loss(x, y) # l是一个张量,tensor主要是在建立计算图 forward, compute the loss
l.backward()
print('\tgrad:', x, y, w.grad.item())
w.data = w.data - 0.01 * w.grad.data # 权重更新时,注意grad也是一个tensor
w.grad.data.zero_() # after update, remember set the grad to zero
print('progress:', epoch, l.item()) # 取出loss使用l.item,不要直接使用l(l是tensor会构建计算图)
print("predict (after training)", 4, forward(4).item())
2. 构建线性模型 SGD
import torch
import numpy as np
import matplotlib.pyplot as plt
x_data=torch.tensor([[1.0],[2.0],[3.0]])
y_data=torch.tensor([[4.0],[5.0],[6.0]])
class LinearModel(torch.nn.Module):
def __init__(self):
super(LinearModel,self).__init__()
self.linear=torch.nn.Linear(1,1)
def forward(self,x):
y_pred=self.linear(x)
return y_pred
model=LinearModel() #可调用
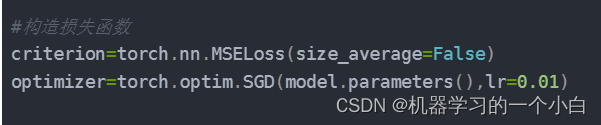
#构造损失函数
criterion=torch.nn.MSELoss(size_average=False)
optimizer=torch.optim.SGD(model.parameters(),lr=0.01)
#训练过程
epoch_list=[]
loss_list=[]
for epoch in range(100):
y_pred=model(x_data)
loss=criterion(y_pred,y_data)
print(epoch,loss)
epoch_list.append([epoch])
loss_list.append([loss.detach().numpy()])
optimizer.zero_grad()
loss.backward()
optimizer.step()
#打印权重
print('w=',model.linear.weight.item())
print('b=',model.linear.bias.item())
#测试模型
x_test=torch.tensor([[4.0]])
y_test=model(x_test)
print("y_pred=",y_test.data)
plt.plot(epoch_list,loss_list)
plt.xlabel('epoch')
plt.ylabel('loss')
plt.show()
可变参数
class Foobar:
def __init__(self):
pass
def __call__(self,*args,**kwargs):
print("Hello"+str(args[0]))
foobar=Foobar()
foobar(1,2,3)
def func(*args,x,y):
print(args)
func(1,2,4,3,x=3,y=5)
def func(*args,**kwargs):
print(args)
print(kwargs)
func(1,2,4,3,x=5,y=6)
3. 其他优化函数
在构造损失函数部分直接将优化函数改为需要的优化函数。
如果想用Adam,直接把SGD改为Adam
4. 练习
用三阶多项式拟合sin(x)
4.1 numpy实现
import numpy as np
import math
# 创建输入和输出数据
x=np.linspace(-math.pi,math.pi,2000)
y=np.sin(x)
#参数随机初始化
a=np.random.randn()
b=np.random.randn()
c=np.random.randn()
d=np.random.randn()
#学习率
learining_rate=1e-6
#正向迭代2000次
for t in range(2000):
#计算预测
y_pred=a+b*x+c*x**2+d*x**3
#计算损失
loss=((y_pred-y)**2).sum()
if t%100==99:
print(t,loss)
#反向传播
#计算参数的梯度
grad_y_pred=2*(y_pred-y)
grad_a=grad_y_pred.sum()
"""grad_b=(grad_y_pred*x).sum()
grad_c=(grad_y_pred*x**2).sum()
grad_d=(grad_y_pred*x**3).sum()"""
grad_b=grad_y_pred@x.T
grad_c=grad_y_pred@(x**2).T
grad_d=grad_y_pred@(x**3).T
#参数更新
a=a-learining_rate*grad_a
b=b-learining_rate*grad_b
c=c-learining_rate*grad_c
d=d-learining_rate*grad_d
#输出
print(f'result: y={a}+{b}x+{c}x^2+{d}x^3')
4.2 张量tensor实现
# -- coding: utf-8 --
import math
import numpy as np
dtype = torch.float
device = torch.device("cpu")
# device = torch.device("cuda:0") # Uncomment this to run on GPU
# 创建输入和输出数据
x = torch.linspace(-math.pi, math.pi, 2000, device=device, dtype=dtype)
y = torch.sin(x)
# 参数随机初始化
a = torch.randn((), device=device, dtype=dtype)
b = torch.randn((), device=device, dtype=dtype)
c = torch.randn((), device=device, dtype=dtype)
d = torch.randn((), device=device, dtype=dtype)
# 学习率
learning_rate = 1e-6
# 正向迭代2000次
for t in range(2000):
# 计算预测
y_pred = a + b * x + c * x ** 2 + d * x ** 3
# 计算损失
loss = ((y_pred - y) ** 2).pow(2).sum().item()
if t % 100 == 99:
print(t, loss)
# 反向传播
# 计算参数的梯度
grad_y_pred = 2 * (y_pred - y)
grad_a = grad_y_pred.sum()
grad_b = (grad_y_pred * x).sum()
grad_c = (grad_y_pred * x ** 2).sum()
grad_d = (grad_y_pred * x ** 3).sum()
""" grad_b=grad_y_pred@x.T
grad_c=grad_y_pred@(x**2).T
grad_d=grad_y_pred@(x**3).T"""
# 参数更新
a -= learning_rate * grad_a
b -= learning_rate * grad_b
c -= learning_rate * grad_c
d -= learning_rate * grad_d
# 输出
print(f'result: y={a.item()}+{b.item()}x+{c.item()}x^2+{d.item()}x^3')
4.3 自动更新梯度Autograd
# -- coding: utf-8 --
import math
import numpy as np
# 创建输入和输出数据
x = torch.linspace(-math.pi, math.pi, 2000, device=device, dtype=dtype)
y = torch.sin(x)
# 输出y是(x, x^2, x^3)的线性函数
p=torch.tensor([1,2,3])
xx=x.unsqueeze(-1).pow(p)
model=torch.nn.Sequential(torch.nn.Linear(3,1),torch.nn.Flatten(0,1))
loss_fn=torch.nn.MSELoss(reduction='sum')
# 学习率
learning_rate = 1e-6
# 正向迭代2000次
for t in range(2000):
# 计算预测
y_pred = model(xx)
# 计算损失
loss = loss_fn(y_pred,y)
if t % 100 == 99:
print(t, loss)
# 反向传播
# 计算参数的梯度
model.zero_grad()
loss.backward()
#参数更新
with torch.no_grad():
for param in model.parameters():
param-=learning_rate * param.grad
linear_layer=model[0]
# 输出
print(f'Result: y = {linear_layer.bias.item()} + {linear_layer.weight[:, 0].item()} x + {linear_layer.weight[:, 1].item()} x^2 + {linear_layer.weight[:, 2].item()} x^3')















 6863
6863











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









