







使用PyTorch构建训练模型的一般步骤:
①准备数据集
②使用相关类构建模型,用以计算预测值
③使用PyTorch的应用接口来构建损失函数和优化器
④编写循环迭代的训练过程——前向计算,反向传播和梯度更新,训练过程如下——
- 根据前向计算计算yhat
- 使用损失函数类计算损失函数值
- 进行反向传播,注意梯度清零
- 权重更新
PyTorch相关知识:
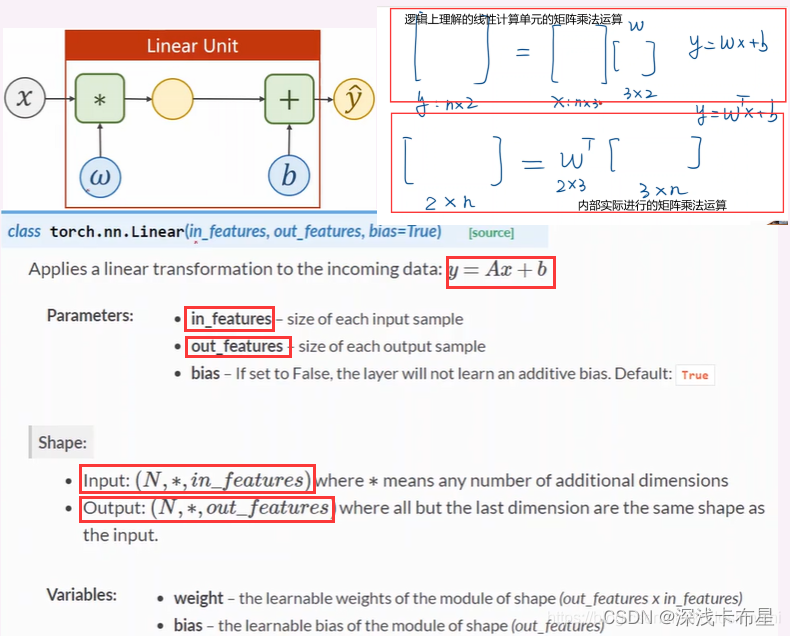
①nn.Linear类中对__call()__方法进行了实现,且其内部有对函数forward()的调用,故在定义模型时需要对forward()函数进行实现。
②nn.Linear类相当于是对线性计算单元的封装,里面包含两个张量类型的成员:权重和偏置项
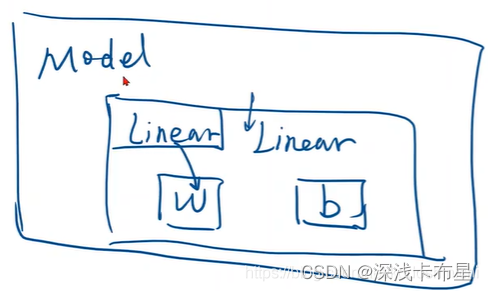
③代码中模型与类之间的关系:
实现步骤
1、准备数据
x_data = torch.tensor([[1.0],[2.0],[3.0]])
y_data = torch.tensor([[2.0],[4.0],[6.0]])
2、设计模型
class LinearModel(torch.nn.Module):
def __init__(self):
super(LinearModel,self).__init__()
self.linear = torch.nn.Linear(1,1)
def forward(self, x):
y_pred = self.linear(x)
return y_pred
model = LinearModel()
3、构造损失函数和优化器
criterion = torch.nn.MSELoss(reduction='sum')
optimizer = torch.optim.SGD(model.parameters(),lr=0.01)
4、训练过程
epoch_list = []
loss_list = []
w_list = []
b_list = []
for epoch in range(1000):
y_pred = model(x_data) # 计算预测值
loss = criterion(y_pred, y_data) # 计算损失
print(epoch,loss)
epoch_list.append(epoch)
loss_list.append(loss.data.item())
w_list.append(model.linear.weight.item())
b_list.append(model.linear.bias.item())
optimizer.zero_grad() # 梯度归零
loss.backward() # 反向传播
optimizer.step() # 更新
5、结果展示
展示最终的权重和偏置:
# 输出权重和偏置
print('w = ',model.linear.weight.item())
print('b = ',model.linear.bias.item())
结果为:
w = 1.9998501539230347
b = 0.0003405189490877092
参考链接:https://www.jb51.net/article/240145.htm
https://blog.csdn.net/kodoshinichi/article/details/114540275















 4869
4869











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









