







这是总结的一个组会报告,小白参考了一些大神的图片和文字,非常感谢~
图像语义分割
普通的图像分割,通常意味着传统语义分割,这个时期的图像分割,由于计算机计算能力有限,早期只能处理一些灰度图,后来才能处理rgb图,这个时期的分割主要是通过提取图片的低级特征,然后进行分割.这个阶段一般是非监督学习,分割出来的结果并没有语义的标注,换句话说,分割出来的东西并不知道是什么。
随后,随着计算能力的提高,人们开始考虑图像的语义分割,这里的语义目前是低级语义,主要指分割出来的物体的类别,这个阶段人们考虑使用机器学习的方法进行图像语义分割。
随着FCN的出现,深度学习正式进入图像语义分割领域,这里的语义仍主要指分割出来的物体的类别,从分割结果可以清楚的知道分割出来的是什么物体,比如猫、狗等等。
常用的数据集:
Pascal VOC 2012:有 20 类目标,这些目标包括人类、机动车类以及其他类,可用于目标类别或背景的分割
Cityscapes:50 个城市的城市场景语义理解数据集
Pascal Context:有 400 多类的室内和室外场景
Stanford Background Dataset:至少有一个前景物体的一组户外场景。
评价标准:
1.执行时间
2.内存占用
3.精确度
MIoU,均交并比:计算两个集合的交集和并集之比,这两个集合为真实值和预测值
论文一:
Fully Convolutional Networks for Semantic Segmentation
发表在:IEEE Transactions on Pattern Analysis and Machine Intelligence
IEEE模式分析与机器智能汇刊
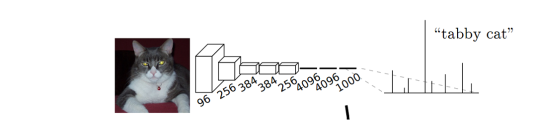
通常CNN网络在卷积层之后会接上若干个全连接层, 将卷积层产生的特征图映射成一个固定长度的特征向量。以AlexNet为代表的经典CNN结构适合于图像级的分类和回归任务,因为它们最后都得到整个输入图像的一个概率向量,比如AlexNet的ImageNet模型输出一个1000维的向量表示输入图像属于每一类的概率。
示例:猫的图片输入到AlexNet, 得到一个长为1000的输出向量, 表示输入图像属于每一类的概率, 其中在“tabby cat”这一类统计概率最高, 用来做分类任务
缺点:
cnn的每一个卷积层,都包含了 [卷积 + 池化] 处理,这就是大家熟知的下采样,但这样处理之后的结果是:图像的像素信息变小了,因此cnn不能输出像素级别的图像。
cnn接收的图片必须是同一尺寸的。
作者的创新点:
1)不含全连接层的全卷积网络。可适应任意尺寸输入。
2)增大数据尺寸的反卷积层。能够输出精细的结果。
3)结合不同深度层结果的跳级(skip)结构。同时确保鲁棒性和精确性。
1)简单来说,FCN与CNN的区域在把于CNN最后的全连接层换成卷积层,输出的是一张已经Label好的图片。
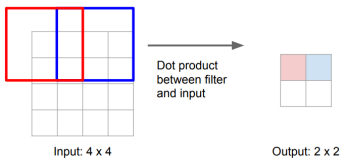
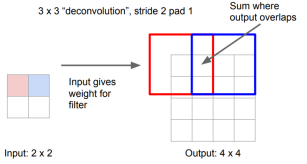
2)反卷积和卷积类似,都是相乘相加的运算。只不过后者是多对一,前者是一对多。
3)在通过如下图所示的conv7之后,输出尺寸很小,然后进行32×上采样以使输出的尺寸和输入尺寸相同。它被称为FCN-32。输出图很粗糙。

作者提出了skip结构,提高鲁棒性。
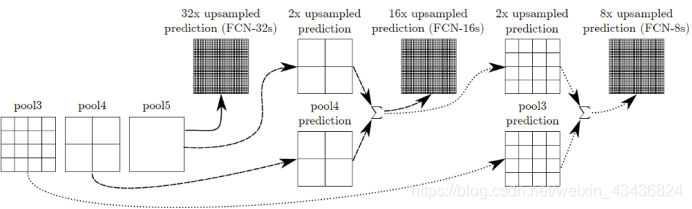
对原图像进行卷积conv1、pool1后原图像缩小为1/2;之后对图像进行第二次conv2、pool2后图像缩小为1/4;接着继续对图像进行第三次卷积操作conv3、pool3缩小为原图像的1/8,此时保留pool3的特征图;接着继续对图像进行第四次卷积操作conv4、pool4,缩小为原图像的1/16,保留pool4的特征图;最后对图像进行第五次卷积操作conv5、pool5,缩小为原图像的1/32。
现在我们有1/32尺寸的heatMap,1/16尺寸的featureMap和1/8尺寸的featureMap。1/32尺寸的featuremap进行上采样操作之后,因为这样操作还原的图片仅仅是conv5中的卷积核中的特征,限于精度问题不能够很好地还原图像当中的特征,因此在这里向前迭代。把conv4中的卷积核对上一次upsampling之后的图进行反卷积补充细节,最后把conv3中的卷积核对刚才upsampling之后的图像进行再次反卷积补充细节,最后就完成了整个图像的还原。
不同的结构产生的结果对比如下:
FCN的缺点也比较明显:一是得到的结果还是不够精细,对图像中的细节不敏感。二是对各个像素进行分类,没有充分考虑像素与像素之间的关系。
论文二:
SEMANTIC IMAGE SEGMENTATION WITH DEEP CONVOLUTIONAL NETS AND FULLY CONNECTED CRFS
收录在:ICLR 2015 (International Conference on Learning Representations)
作者的创新点:
1)提出了一种新的卷积方式,带孔的卷积:Atrous Convolution。
2)引入条件随机场,这样可以考虑像素和像素之间的关系。
1)结构图:
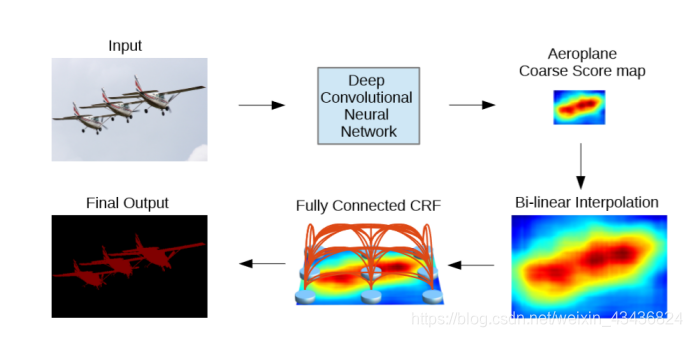
输入经过改进的DCNN(带空洞卷积和ASPP模块)得到粗略预测结果,即Aeroplane Coarse Score map
通过双线性插值扩大到原本大小,即Bi-linear Interpolation
再通过全连接的CRF细化预测结果,得到最终输出Final Output
2)带孔卷积:
标准卷积在特定场景如图像语义分割下存在一定的问题,比如通过池化操作降低计算量,同时增大感受野,再通过反卷积扩充图像到原始大小,这中间会丢失很多信息,特别是空间结构信息,另一个问题是小的物体信息无法复原重建出来。而在扩张卷积中,避免了使用池化操作的同时增大了感受野,不需要图像分辨率的压缩,保留了图像内部的数据结构,可以有比标准卷积更好的分割效果。
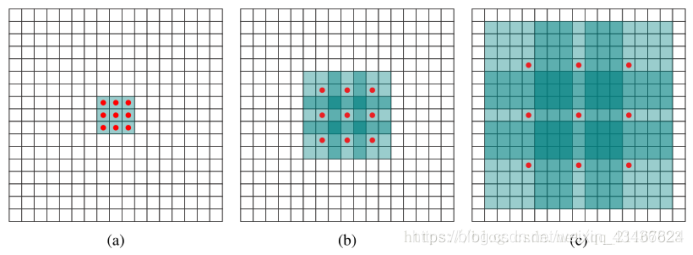
图a是普通的卷积,感受野是33,相当于没有扩充
图b是带孔卷积,感受野是77
图c是带孔卷积,感受野是1515
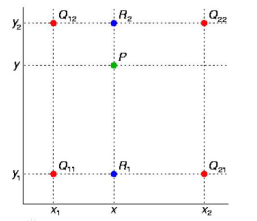
3)双线性插值:
假设原图像大小为mxn,目标图像为axb。那么两幅图像的边长比分别为:m/a和n/b,目标图像的第(i,j)个像素点(i行j列)可以通过边长比对应回源图像。其对应坐标为(im/a,j*n/b)。线性插值通过寻找距离这个对应坐标最近的四个像素点,来计算该点的值。
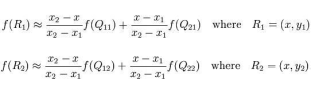
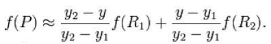
4)全连接条件随机场:
全连接条件随机场的能量函数如下:
E(x)=i∑θi(xi)+ij∑θij(xi,yj)
其中x是指派给像素的标签,把θi(xi)=-logP(xi)视为一元势能。P(xi)是DCNN计算出的像素的标签分配概率。
称为二元势能(成对势能),如果xi≠xj,u(xi,xj)=1,如果xi=xj,u(xi,xj)=0.可以理解为如果两个相似像素(例如相邻像素或像素具有相似颜色)采用不同标签时,才进行计算。
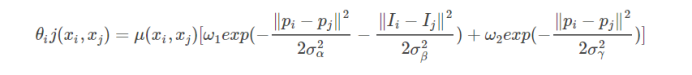
第一项称之为外观核,第二项称之为平滑核。超参数σα,σβ,σγ控制高斯核的权重。 其中第一个核与像素位置(用表示)和像素颜色强度(用表示)有关。这是一种双边滤波器。 双边滤波器具有保留边缘的特性。第二个核仅取决于像素位置的差异,这是一个高斯滤波器。
效果如下:

总结:
DeepLabv1是在VGG16的基础上做了修改:
VGG16的全连接层转为卷积
最后的两个池化层去掉了下采样
后续卷积层的卷积核改为了空洞卷积
论文三:
DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs
发表在:IEEE TPAMI
IEEE模式分析与机器智能汇刊
三个贡献和创新点:
Atrous CNN:准确调节分辨率,扩大感受野,降低计算量
ASPP:多尺度特征提取,得到全局和局部特征和语义
Fully Connected CRF:概率图模型,优化边缘效果
感受野,是指他特征图上一个点能看到的原图的区域,那么如果有多个感受野,相当于一种多尺度特征提取,出于这个思路,v2版本在v1的基础上增加了一个多感受野的这种结构叫做aspp。具体看图可以很直观的理解。
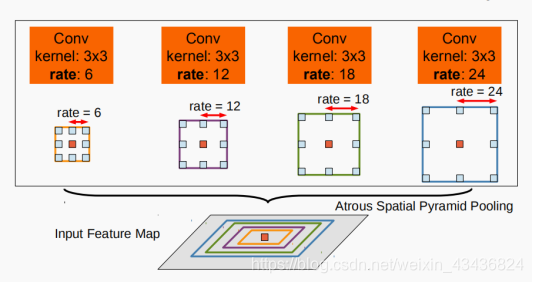
图中为四个不同r值的卷积,卷积核大小为3,膨胀速率分别为6,12,18,24,将特征图通过四个conv后,得到的结果在原特征图上进行了勾画,很显然,aspp可以捕捉到特征图中不同尺寸的信息,因此能很好的改善对不同尺寸的物体的分割效果。
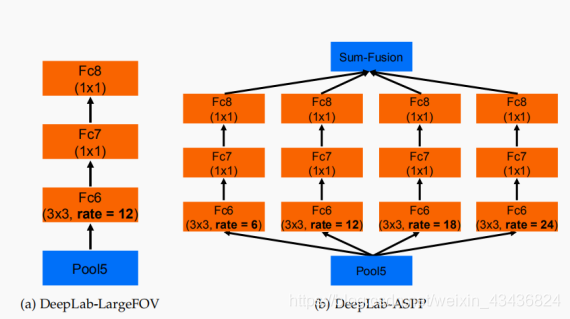
ASPP各个空洞卷积分支采样后结果最后融合到一起(通道相同,做像素加),得到最终预测结果.
结果:
主要改动:
引入aspp
主网络从vgg16变成resnet
比deeplabv1好的地方:
速度上: 使用空洞卷积的Dense DCNN达到8fps,全连接的CRF需要0.5s
精准度:在测试的数据集上达到了更好的结果
论文四:
Rethinking Atrous Convolution for Semantic Image Segmentation
以前论文的问题:
内部数据结构丢失;空间层级化信息丢失。
小物体信息无法重建 (假设有四个pooling layer 则任何小于 2^4 = 16 pixel 的物体信息将理论上无法重建。)
创新点:
1)作者一个很重要的成果在于发现空洞卷积的rate并不是越大越好。
通常在ASPP中的rate都会非常大,把大尺度信息聚合起來,但作者通过实验发现随着rate的增加,卷积核中的有效权重会越來越少,不仅没有起到捕捉全局信息的作用,反而会坍塌成一个1*1的卷积,只有最中心的卷积核有个不等于0的值,其他的权重都为0。
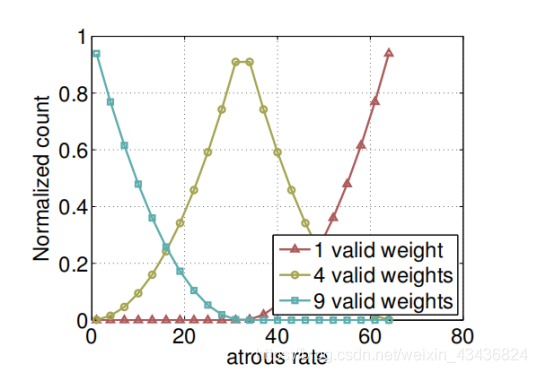
这意味着想要获取全局信息,使用大的rate并不是一个合适的办法,因此,作者在ASPP层又加入了一个全局平均池化(Global Average Pooling)让空洞卷积只负责较大尺度的信息聚合,全局信息交给GAP来收集,GAP位于模型的最后一层,将得到的图像级特征输入到具有256个过滤器的1×1卷积。最后经过双线形插值插值到原来的大小,与其他的特征图拼接起來。
全局平均池化:
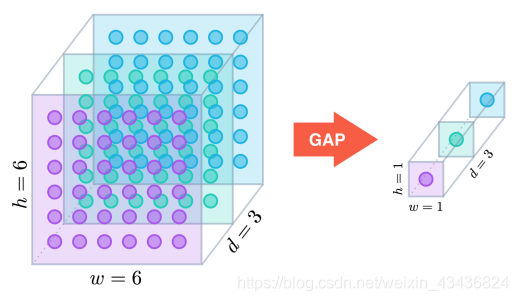
假设卷积层的最后输出是h×w×d的三维特征图,具体大小为6×6×3,经过GAP转换后,变成了大小为1×1×3的输出值也,就是每一层h×w会被平均化成一个值。
改进了ASPP模块:我们尝试以串行或并行的方式布局模块。
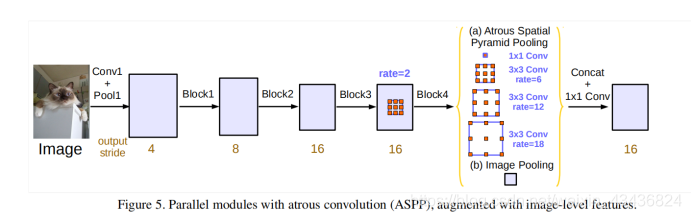
经过实验,并联比串联的效果稍好一些。
优点:
条件随机场被去除了,并且模型比较简洁易懂。
效果更好














 8736
8736











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









