






前几天更新了半监督、无监督、有监督、自监督学习的概念,顺手查到了soft teacher模型。下面介绍以下该模型。
论文地址:https://arxiv.org/pdf/2106.09018.pdf
伪标签和存在的问题
在半监督学习中,数据分为两部分,一部分数据是有标签的,另一部分数据是没有标注的。半监督目标检测的常见思路分两步走:
第一步,利用公开数据集提前训练一个目标检测模型A,该目标检测模型A性能强大。对于没有标签的数据,可以利用模型A得到这些数据对应的预测结果。这种预测结果称为伪标签(pseudo label)。之所以是“伪”,是因为该标签是深度学习模型预测的结果,而非人工标注。
第二步,有了伪标签的未标注数据也算是有标签了,利用伪标签配合数据参与训练目标检测模型。
这种方法听起来非常的巧妙,而且有一个特点:伪标签的好坏取决于目标检测模型A的性能,如果A检测出的效果不好,那么伪标签生成的就不好。很多时候会利用伪标签和数据重新训练模型A,这样就增加了半监督目标检测的时间耗费,使得整个过程更加的复杂多变。
soft teacher就解决了上述问题,它能做到:第一,生成高质量的伪标签;第二,模型是一个端到端的模型,整个过程简单。
整体流程
算法的整体流程如下:
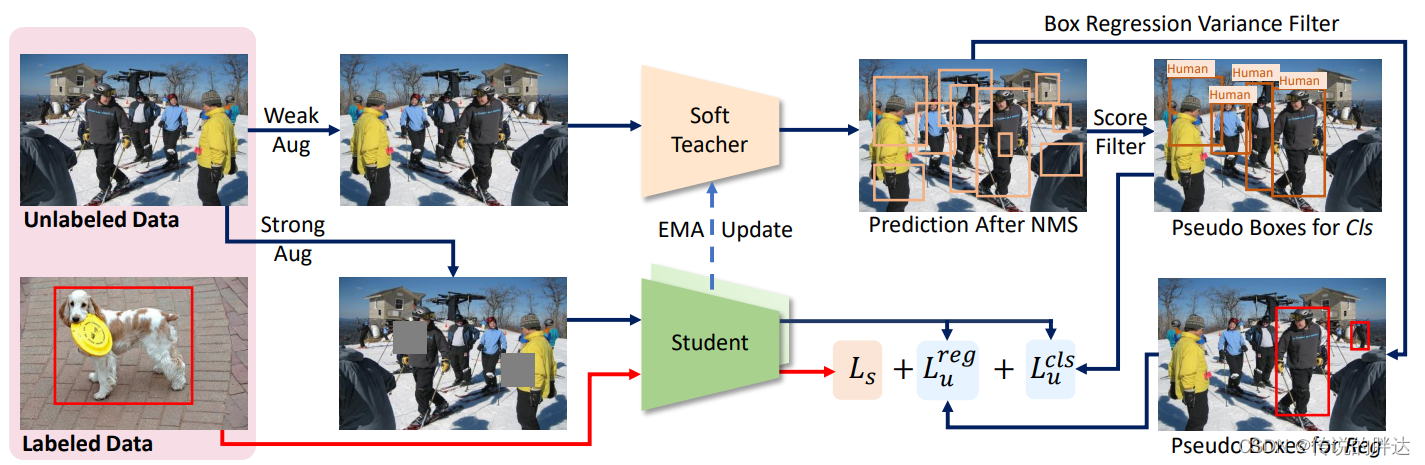
算法的整体流程如上图所示,可以看到,模型的整体结构分为soft_tercher网络和student网络。
输入数据是一个个的图像batch,每一个batch都包含有标签的图像和无标签的图像,有标签:无标签=1:4。teacher网络的主要任务是生成伪标签,为student提供损失计算的标签。需要注意的是,soft teacher本质上是不更新的,它的参数是根据student网络的参数变化进行更新,策略是EMA算法(这个不是重点,大家自行找资料参考)。soft teacher模型对有标签和无标签的图像分别进行不同的处理。首先是数据增强,对于有标签的图像要进行强数据增强(例如遮挡、对比度饱和度变换等),无标签的图像要进行弱数据增强(例如反转)。弱数据增强的图像要输入到teacher网络中,teacher网络会预测出目标类别和bbox位置,之后要进行筛选,根据置信度阈值筛选出合理的结果作为伪标签,然后伪标签参与训练student网络即可。
整体的流程非常简单但是很新颖,并且只是在处理流程方面做了改进,并没有改进模型的结构。
网络类型
teacher网络和student网络采用faster RCNN网络,faster Rcnn网络是一个两阶段的检测模型,通过实验可以看到只有这种两阶段模型更适合用在半监督中。
类别的筛选
经过teacher网络输出的结果需要进行筛选,通常会设置一个阈值。和我们想象中不同的是,阈值设置的非常高,为0.9。0.9的阈值会带来很大的问题:大量的前景都被当做背景给过滤掉了,导致预测的类别非常少,但是阈值不能设置的过低,因为teacher模型本身没有训练过程,在整体训练初期生成的伪标签质量很低,必须通过高阈值来筛选出最合理的结果。为了解决这个问题,这篇论文采用了加权训练的方式。对于分类损失函数构造并不只是关注模型最后的预测结果,还要关注RPN层,在RPN层中已经确定了前景,因此在分类的损失函数中确定背景的问题:

公式的整体分为两部分,前一部分表示前景的预测,后一部分表示背景的预测,可以看到,在背景预测的损失前面加入了一个w权重,该权重衡量背景属于前景的可能性。我们假设一个前景的预测得分为0.8,但是阈值是0.9,肯定会被过滤掉,但是w权重和预测得分关联性很大,因此权重会设计的比较大,这样可以保证这个被误删除的前景仍然可以发挥作用。权重的公式如下:
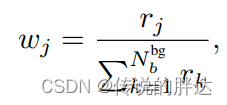
rj表示目标的预测得分。
box抖动
阈值太高会删除预测的类别结果,也同样会删除回归框。因此论文采取了新的回归框筛选方式(类别的阈值太高会删除前景,这个问题可以在损失函数中进行弥补,回归框筛选采用了新的方法,这不是弥补)。首先对预测出的回归框进行随机抖动,论文中规定是10次。假设原本有2个回归框,经过抖动就会得到20个回归框。在faster rcnn中,经过RPN网络筛选出的前景和原先的特征图会经过RCNN部分得到预测框的偏移量来修正预测框。20个回归框经过修正会得到20个结果,这里就是关键了,如果这两个目标是真实存在的前景,那经过修正后的20个回归框会有明显的两簇,也就是它们的方差小;如果这两个目标是背景,那经过修正后的20个回归框会有明显分散,它们的方差更大,通过方差筛选即可得到合适的回归框。
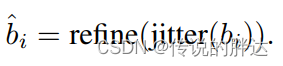
总体来说,这种算法极度依赖两阶段目标检测算法,很多人尝试过将teachrer网络和student网络替换成YOLO或者是DETR,但是效果超级差,所以这种半监督目标检测还有很长的路要走的.















 6759
6759











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









