







GAN
-
什么是生成?
生成就是模型通过学习一些数据,然后生成类似的数据
-
GAN原理
GAN是如何生成图片?GAN有两个网络,一个是generator(生成图片的网络),还有一个是discriminator(判别网络)。
在我们训练过程当中,生成网络G的目标就是尽量生成真实的图片去"欺骗"网络D。
网络D的目标就是区分生成的图片与真实的图片。
这样就构成的一个"博弈过程"。
在最理想的情况下,G可以生成足以“以假乱真”的图片G(z)。对于D来说,它难以判定G生成的图片究竟是不是真实的,因此D(G(z)) = 0.5。

如图,首先有一个Generator v1,它生成一些很差的图片,然后有一个Discriminator v1
,它能准确的把生成的图片,和真实的图片分类。
换一句话说,这个Discriminator就相当于一个二分类器,对生成的图片输出0,对真实的图片输出1.
接着,开始训练出Generator v2,它能生成稍好一点的图片,能够让Discriminator v1认为这些生成的图片是真实的图片。然后会训练出 Discriminator v2,它能准确的识别出真实的图片,和 Generator v2 生成的图片。以此类推,会有三代,四代。。。n 代的 generator 和 discriminator,最后 discriminator 无法分辨生成的图片和真实图片,这个网络就拟合了。
-
GAN数学描述
根据paper Generative Adversarial Networks 中的公式

- 整个式子由两项构成。x表示真实图片,z表示输入G网络的噪声,而G(z)表示G网络生成的图片。
- D(x)表示D网络判断真实图片是否真实的概率(因为x就是真实的,所以对于D来说,这个值越接近1越好)。而D(G(z))是D网络判断G生成的图片的是否真实的概率。
- 真实图片集的分布Pdata(x),x 是一个真实图片,可以想象成一个向量,这个向量集合的分布就是 Pdata。
- G的目的:上面提到过,D(G(z))是D网络判断G生成的图片是否真实的概率,G应该希望自己生成的图片“越接近真实越好”。也就是说,G希望D(G(z))尽可能得大,这时V(D, G)会变小。因此我们看到式子的最前面的记号是min_G。
- D的目的:D的能力越强,D(x)应该越大,D(G(x))应该越小。这时V(D,G)会变大。因此式子对于D来说是求最大(max_D)
-
GAN训练
起初有一个 G0 和 D0,先训练 D0 找到
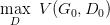
然后固定 D0 开始训练 G0, 训练的过程都可以使用 gradient descent,以此类推,训练 D1,G1,D2,G2,…
但是这里有个问题就是,你可能在 D0* 的位置取到了:
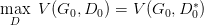
然后更新 G0 为 G1,可能:
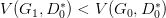
但是并不保证会出现一个新的点 D1* 使得
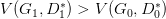
这样更新 G 就没达到它原来应该要的效果,如图:
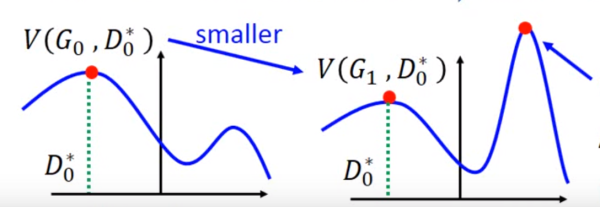
为避免上述情况,我们并不需要更新G太多。
我们还需要设定两个 loss function,一个是 D 的 loss,一个是 G 的 loss。
下图是完整的GAN训练流程:

如果本文对你有帮助,欢迎点赞、订阅以及star我的项目。
你的支持是我创作的最大动力!















 2802
2802











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









