







文章目录
企业问答知识库是什么?
定位:AI文档阅读分析工具
- 大模型企业问答知识库定位为企业的智能客户服务或内部支持工具。
- 它旨在替代或辅助传统的客户服务方式,如电话、邮件支持,以减少人力成本并提高响应速度。
形式:聊天互动
实现方式:利用向量库(存储向量片段的地方)和大模型技术,精准地从复杂文档提取并分析信息,将准确的答案返给用户。
价值: - 提供全天的即时问答服务,提高客户满意度和忠诚度。
- 减少对人工客户支持的需求,降低运营成本。
- 通过分析用户问题来获取洞察,帮助企业改进产品和服务。
- 提供统一的问答体验,确保信息的准确性和一致性。
场景:
- 客户服务:用户可以通过知识库获取产品信息、服务状态、常见问题解答等。
- 内部支持:企业员工可以使用知识库来获取公司政策、IT支持、操作指南等信息。
- 销售支持:提供产品规格、定价信息、促销活动等,帮助销售团队提高效率。
- 培训和教育:为新员工提供培训资料,或为用户提供产品使用教程。
为什么要做企业知识库?
从传统客服问答系统与AI企业知识库系统问答做对比

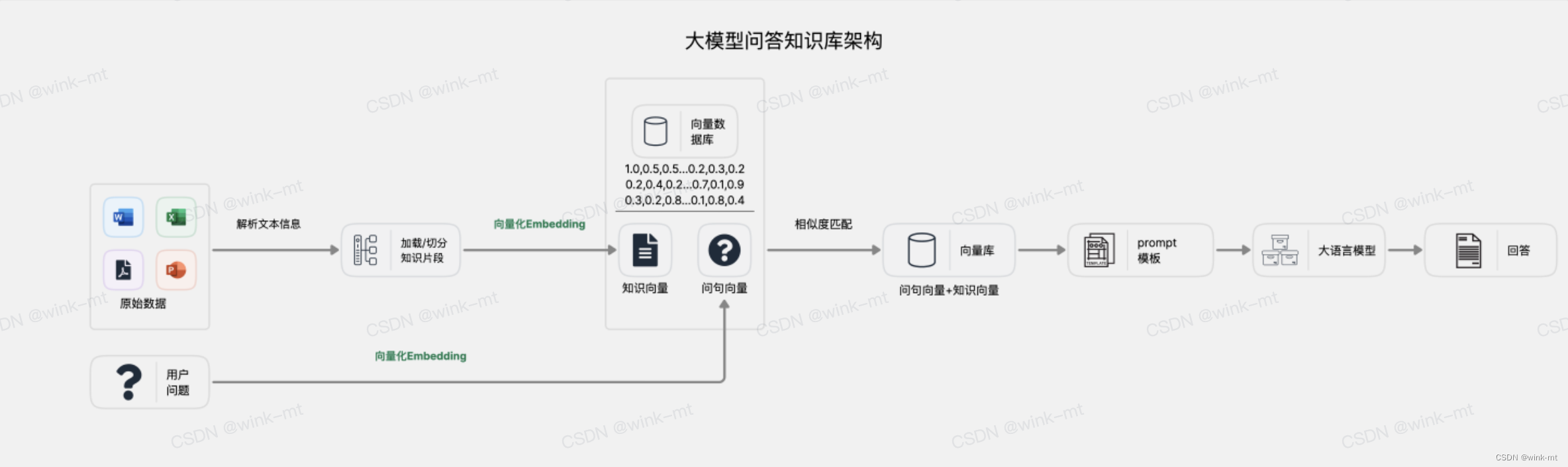
大模型问答知识库架构
词嵌入Embedding是什么?
词嵌入(Word Embedding)是一种将词汇表中的 每个词映射到高维空间中的稠密向量的技术。这些向量在某种程度上能够捕捉到词汇的语义和上下文信息,使得语义上相似的词在向量空间中彼此接近。词嵌入是自然语言处理(NLP)中的一项重要技术,它为机器学习模型提供了更加丰富和细腻的词义表示,从而在许多NLP任务中取得了显著的性能提升。
词嵌入的主要特点和优势包括:
- 维度降低:词嵌入将词汇映射到低维空间中,从而降低了数据的复杂性,同时保留了词汇的主要语义特征。
- 语义表示:词嵌入能够捕捉词汇的语义信息,使得语义上相似的词在向量空间中距离较近。
- 上下文感知:通过上下文中的词来学习词嵌入,可以捕捉到词汇的上下文信息,例如,一个词在不同的上下文中可能会有不同的嵌入向量。
- 泛化能力:词嵌入模型可以识别出未在训练数据中出现过的词(即未知词),这些词通常会根据其上下文信息被赋予相似的嵌入向量。
- 计算效率:与传统的基于计数的模型(如词袋模型)相比,词嵌入模型在计算上更加高效。
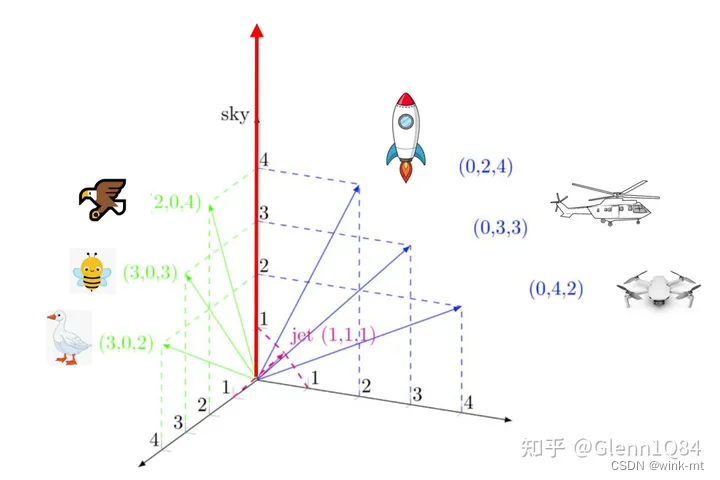
词嵌入定义
将词/字符转换为有意义且可计算的数值。
Embedding的本质是信息的聚合和解耦,也就是信息的再表达。
如上图所示:有两组词{蜜蜂,饿,鹰},{直升机,无人机,火箭},用具有意义的数值(具有词义)来表示他们。

Embedding为什么重要?
它可以表示单词或者语句的语义,把文字信息转化为计算机可理解的语义向量。任何神经网络真正的输入都是向量。
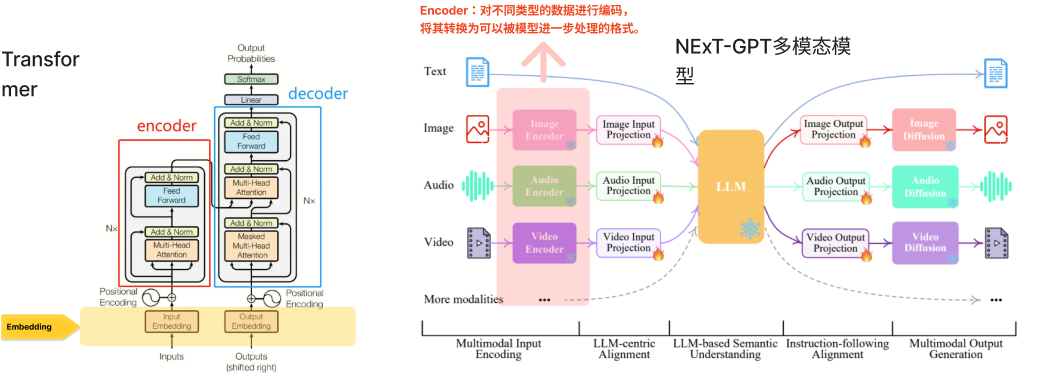
(上右图,NExT-GPT是一个任意到任意的多模态LLM,可以处理四种不同类型的输入和输出:文本、图像、视频和音频。这项研究是由新加坡国立大学的NExT++研究小组发起的。该显示了NExT-GPT模型的整体表示。特别值得指出的是,所谓多模态转换与大语言模型能力的结合,并不是简单地用prompt方式在彼此之间“搭桥”,而是 真正把多模态数据(向量)同语言数据结合起来,这个过程被真正拉通后,等于大模型可以不仅学习从而理解人的语言,还能把这种能力扩大到更多模态去,这种结合一旦成功,将会带来AI能力质的飞跃。)
多模态处理流程中的几个关键步骤,包括编码(将数据转换为模型可理解的格式)、对齐(将不同模态的数据映射到同一空间)、理解(模型对输入数据的语义理解)、语义指令执行,指LLM根据输入的语义信息执行任务。和生成(根据理解生成输出)。
Embedding在大模型中的价值
embedding向量包含语义信息,含义越相近的单词,embedding向量在空间中的位置也越相近。实值向量embedding可以通过从大量的数据中学习单词的语义和上下文信息,从而可以进行向量运算和在不同自然语言处理任务中共享和迁移。
然而,这是Embedding之前的价值。在大语言模型时代,Embedding又有什么新的价值呢?
这要从类ChatGPT模型的缺陷说起。尽管它们能力强大,但目前依然存在以下几点问题:
- 训练数据不实时(如ChatGPT是基于2021年9月之前的数据训练),重新训练成本过高,不现实
- 输入文本长度有限制,通常限制在几千到数万个tokens之间
- 无法访问不能公开的文档
embeddingChatGPT这样的模型流行之后,大家发现有了新的价值,即解决大模型的输入限制。
为什么使用Embedding?
- Embedding的主要优势是能够将实体转换为计算机易于处理的数值形式,同时减少信息的维度和复杂度。
- 有助于提高处理效率,而且也使得不同实体之间的比较(如计算相似度)变得可行。
- embedding通常通过大量数据的训练而得到,能够捕捉到复杂的模式和深层次的关系,这是传统方法难以实现的
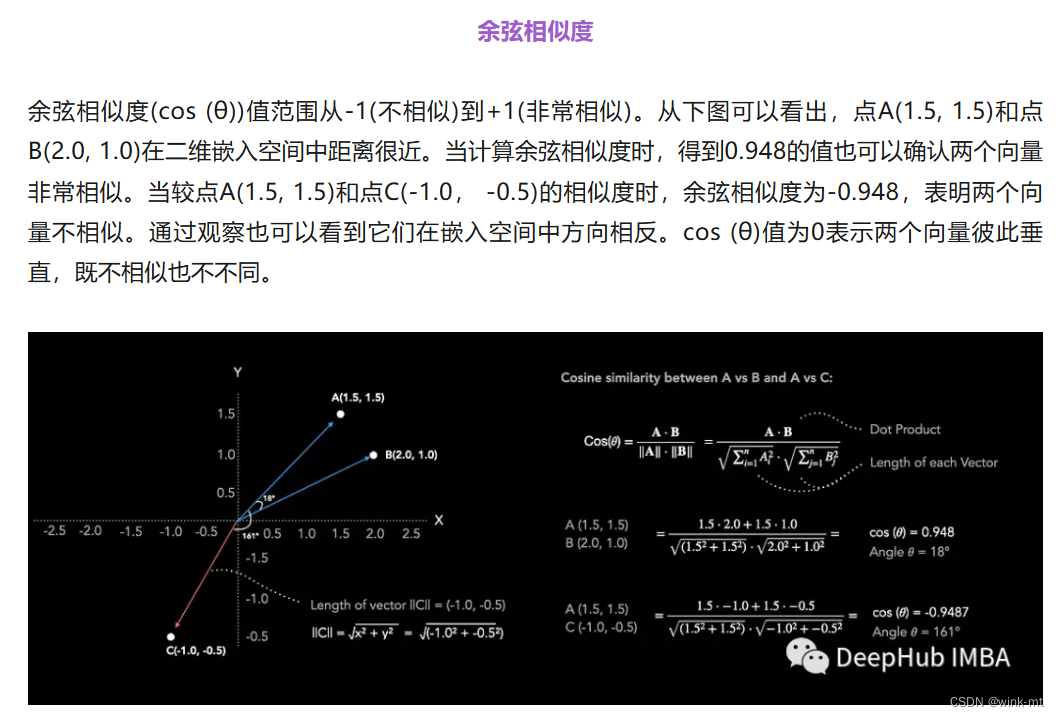
向量的相似度可以通过余弦相似度(Cosine Similarity): 余弦相似度是通过测量两个向量之间夹角的余弦值来评估它们的相似性。如果两个向量的方向相同,余弦相似度接近1;如果方向完全相反,余弦相似度接近-1。















 971
971

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









