




 该博客介绍了如何使用线性支持向量机(SVM)对垃圾邮件进行分类。首先,通过loadData()函数加载训练集(task3_train.mat)和测试集(task3_test.mat)的数据,展示数据的样本数和特征维度。接着,利用sklearn的svm库训练线性SVM模型,计算并在训练集上评估了模型的准确率。此外,还尝试了高斯核函数(RBF),并探讨了SVM参数C和核函数sigma对模型的影响。最后,讨论了支持向量机的参数选择和核函数选择的一般原则。
该博客介绍了如何使用线性支持向量机(SVM)对垃圾邮件进行分类。首先,通过loadData()函数加载训练集(task3_train.mat)和测试集(task3_test.mat)的数据,展示数据的样本数和特征维度。接着,利用sklearn的svm库训练线性SVM模型,计算并在训练集上评估了模型的准确率。此外,还尝试了高斯核函数(RBF),并探讨了SVM参数C和核函数sigma对模型的影响。最后,讨论了支持向量机的参数选择和核函数选择的一般原则。
代码地址
使用线性SVM实现对垃圾邮件分类
(1)问题描述:
编程实现一个垃圾邮件SVM线性分类器,分别在训练集和测试集上计算准确率。其中训练数据文件:task3_train.mat,要求导入数据时输出样本数和特征维度。测试数据文件:task3_test.mat,要求导入数据时输出样本数和特征维度,测试数据标签未给出。(程序运行时间10mins左右)
(2)实现过程:
-
分析数据:
利用给出loadData(),读取数据,并输出维度:
X, y = svmF.loadData('task3_train.mat') shape = np.shape(X) print('训练集样本数:%d,特征维度:%d' % (shape[0], shape[1])) ''' output: 训练集样本数:4000,特征维度:1899 '''观察输入如下图所示:
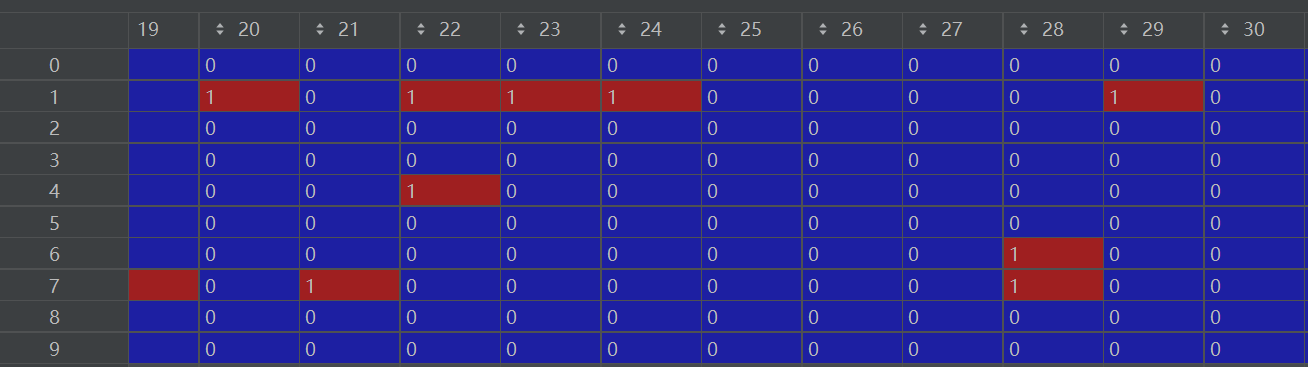
可知,这里是已经完成了邮件特征变量的提取的数据。
完成了邮件特征变量的提取之后, 可以利用4000个训练样本和1000个测试样本训练SVM算法, 每个原始的邮件将会被转化为一个 x ∈ R 1900 x \in R^{1900}
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1442
1442

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











