







9.1 常用的聚类划分方式有哪些?列举代表算法。
答:
- 原型聚类:
代表算法:K-means、K-中心点、高斯混合聚类
- 密度聚类:
代表算法:DBSCAN、OPTICS、CURE
- 层次聚类:
代表算法:HAC、BIRCH、DIANA
9.2 Kmeans初始类簇中心点的如何选取?
答:
理论上初始中心点可以随机选取,但为了提高效率,并获得更好的结果,我们希望选取初始的聚类中心之间的相互距离要尽可能的远,因此我们可以:
- 选择彼此距离尽可能远的K个点 :
首先随机选择一个点作为第一个初始类簇中心点,然后选择距离该点最远的那个点作为第二个初始类簇中心点,然后再选择距离前两个点的最近距离最大的点作为第三个初始类簇的中心点,以此类推,直至选出K个初始类簇中心点。
- 使用层次聚类等方法初始聚类:
先对数据用层次聚类算法或者Canopy算法进行聚类,得到K个簇之后,从每个类簇中选择一个点,该点可以是该类簇的中心点,或者是距离类簇中心点最近的那个点。
9.3 传统的凝聚层次聚类过程每步合并两个簇。这样的方法能够正确地捕获数据点集的(嵌套的)簇结构吗?如果不能,解释如何对结果进行后处理,以得到簇结构更正确的视图。
答:
不能。
传统的凝聚层次聚类过程每步合并两个最相似的簇,直至只剩下一个簇才停止聚类。该聚类方法并不能产生嵌套的簇结构。
后处理:每次合并都记录父子簇之间的关系,采用树结构的方法来捕捉形成的层次结构,最后形成一个清晰的树状簇结构。
9.4使用下表中的相似度矩阵进行单链和全链层次聚类。绘制树状图显示结果。树状图应当清楚地显示合并的次序。
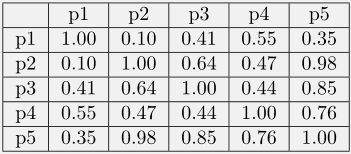
答:
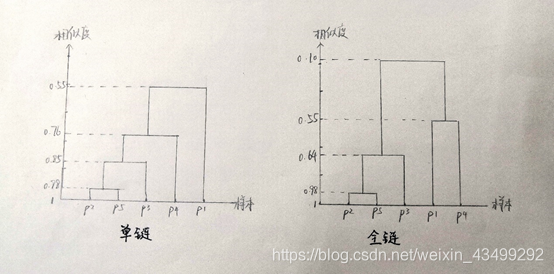
单链:该方法中两个簇的邻近度定义为两个不同簇中任意两点之间的最短距离。
两个簇之间的相似度计算公式为:
dist({m1,m2},{m3,m4})=min(dist(m1,m3),dist(m1,m4),dist(m2,m3),dist(m2,m4))
全链:该方法中两个簇的邻近度定义为两个不同簇中任意两点之间的最长距离。
两个簇之间的相似度计算公式为:
dist({m1,m2},{m3,m4})=max(dist(m1,m3),dist(m1,m4),dist(m2,m3),dist(m2,m4))
结果如下图所示:


















 7356
7356

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











