







 本文详细解读了聚类中的三种关键算法:kkk均值聚类、学习向量量化LVQ和高斯混合模型,通过实例演示了它们的原理和计算过程,同时介绍了密度聚类的DBSCAN算法。层次聚类的AGNES则展示了自底向上的聚合策略。
本文详细解读了聚类中的三种关键算法:kkk均值聚类、学习向量量化LVQ和高斯混合模型,通过实例演示了它们的原理和计算过程,同时介绍了密度聚类的DBSCAN算法。层次聚类的AGNES则展示了自底向上的聚合策略。
1、聚类的定义
\qquad 聚类:是机器学习中的无监督学习,目标是通过对无标记训练样本的学习来解释数据的内在性质以及规律,为进一步的数据分析提供基础。
\qquad 聚类试图将数据集中的样本划分为若干个通常是不相交的子集,每个子集称为一个“簇”
2、常见聚类算法
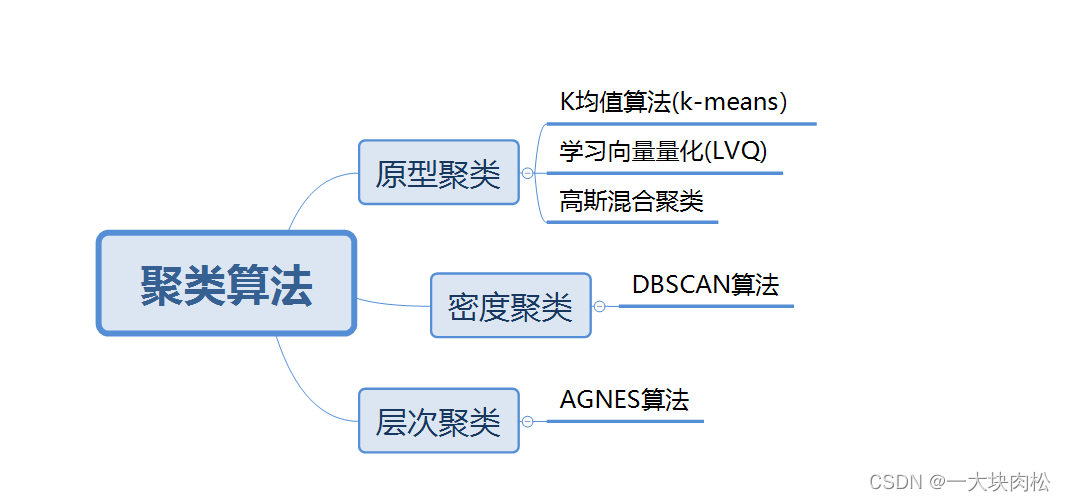
3、原型聚类
\qquad 原型聚类亦称为“基于原型的聚类”(prototype-based clustering),这一类算法假设聚类结构能通过一组原型刻画,在现实聚类中很常用。
\qquad 其统一的步骤为:
算法先对原型进行初始化,然后对原型进行迭代更新求解。
3.1 k k k均值聚类( k − m e a n s k-means k−means)算法
\qquad 给定样本集 D = ( x 1 , x 2 , . . . . . x m ) D=(x_1,x_2,.....x_m) D=(x1,x2,.....xm),共m个样本集,“ k k k均值”算法针对聚类所得簇划分 C = ( C 1 , C 2 , . . . . . . C k ) C=(C_1,C_2,......C_k) C=(C1,C2,......Ck),即需要将样本集中的所有样本根据规则,将其分别划分至合适的簇中,最小化平方误差:
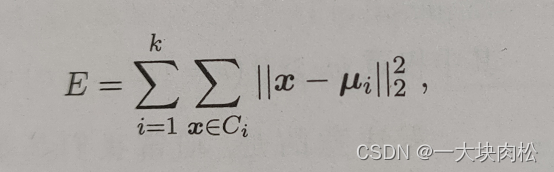
\qquad 最小化平方误差,找到它的最优解需要考察样本集 D D D中的所有可能的簇划分,这是一个NP难问题。因此, k k k均值算法采用了贪心策略,通过迭代优化来近似求解上式,算法的具体流程如下:
1.从样本集 D D D中随机选择 k k
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 36
36

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









