








使用梯度下降训练线性模型
文章目录
1 实验内容
**课程内容回顾:**在理论课程中,我们回顾了机器学习的基本概念,模型的评估和选择,线性模
型和广义线性模型的概念和相关的梯度下降的优化方法。
**要求:**不使用Tensorfolow、Pytorch 或者scikit-learn 等机器学习框架,仅使用Numpy,Scipy 和
Matplotlib 等Python 常用科学计算和可视化库,使用梯度下降训练线性模型,实现(两类)正态
分布数据的分类。
2 实验原理
线性分类——最小二乘法
一般来说,线性回归都可以通过最小二乘法求出其方程,可以计算出对于y=bx+a的直线。
一般地,影响y的因素往往不止一个,假设有x1,x2,…,xk,k个因素,通常可考虑如下的线性关系式:

logistic回归
logistic回归是一种广义线性回归(generalized linear model),因此与多重线性回归分析有很多相同之处。它们的模型形式基本上相同,都具有 $ wx+b $ ,其中w和b是待求参数,其区别在于他们的因变量不同,多重线性回归直接将w‘x+b作为因变量,即 $ y =wx+b $ ,而logistic回归则通过函数L将 w x + b wx+b wx+b 对应一个隐状态 p = L ( w x + b ) p =L(wx+b) p=L(wx+b) ,然后根据p 与1-p的大小决定因变量的值。如果L是logistic函数,就是logistic回归。
3 具体实现
数据生成与可视化:
使用Numpy生成两类正态分布 N ( ± μ , I d ) , d = 2 , μ = [ 1 ; − 1 ] N(±μ, Id),d = 2,μ = [1; − 1] N(±μ,Id),d=2,μ=[1;−1],数据总数目m = 500。
这里可以使用多种方法:
- 由
numpy.random.multivariate_normal(mean, cov[, size, check_valid, tol]).直接生成。 - 先由
np.random.randn()生成一维的正态分布,再转化为2维正态。
代码如下所示:
import numpy as np
from numpy.linalg import cholesky
import matplotlib.pyplot as plt
import pandas as pd
sampleNo = 250
mu = np.array([1, -1])
mu2 = np.array([-1, 1])
Sigma = np.array([[1, 0], [0, 1]])
s1 = np.random.multivariate_normal(mu, Sigma, sampleNo)
s1 = np.random.multivariate_normal(mu2, Sigma, sampleNo)
# R = cholesky(Sigma).T
# va, vc = np.linalg.eig(Sigma)
# R2 = (np.diag(va) ** 0.5) @ vc.T
# s1 = np.random.randn(sampleNo, 2) @ R + mu
# s2 = np.random.randn(sampleNo, 2) @ R + mu2
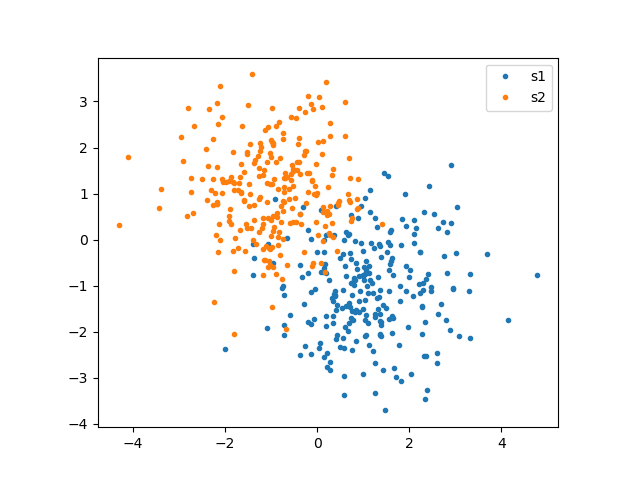
生成数据后,我们使用matplotlib对数据可视化如下:
plt.plot(*s1.T, '.', label='s1')
plt.plot(*s2.T, '.', label='s2')
plt.axis('scaled')
plt.legend()
plt.show()
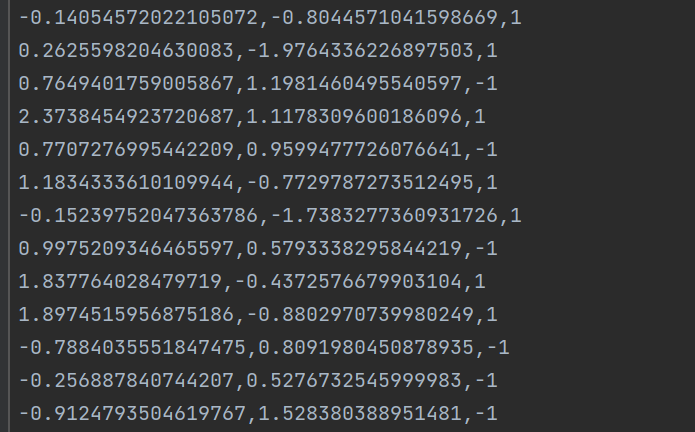
最后,我们为两类数据打上Label,再打乱后存入csv文件。
data1 = pd.DataFrame(s1)
data1['label'] = 1
data2 = pd.DataFrame(s2)
data2['label'] = -1
data = pd.concat([data1, data2])
data0 = data.sample(frac=1)
data0.to_csv('data0.csv', header=False, index=False)
数据读取与处理:
从csv文件中读取数据,按照8:2的比例划分训练集与测试集,并对数据添加常数1,构造常数项。
def init_data(a = 0.8):
data = np.loadtxt('data0.csv', delimiter=',')
index_m = round(data.shape[0]*a)
traindata = data[:index_m]
testdata = data[index_m:]
train_x, train_y = data_p(traindata)
test_x, test_y = data_p(testdata)
return train_x, train_y, test_x, test_y
def data_p(dataIn):
dataMatIn = dataIn[:, 0:-1]
classLabels = dataIn[:, -1]
dataMatIn = np.insert(dataMatIn, 0, 1, axis=1) #特征数据集,添加1是构造常数项x0
return dataMatIn, classLabels
法一:利用最小二乘求解线性分类
代码为:
def Leastsquare(train_x, train_y):
# 最小二乘法
H = train_x
H0 = np.array(H)
# H1为H的转置矩阵
H1 = np.array(H0).T
H2 = H1 @ H0
# 求逆矩阵
H3 = np.linalg.inv(H2)
# 最终结果计算
W = H3 @ H1 @ train_y
# W = grad_descent(train_x, train_y)
return W
法二:利用线性分类+梯度下降:
代码:
def grad_descent_mse(dataMatIn, classLabels, maxCycle=500):
dataMatrix = np.mat(dataMatIn) # (m,n)
labelMat = np.mat(classLabels).transpose()
m, n = np.shape(dataMatrix)
weights = np.ones((n, 1)) # 初始化回归系数(n, 1)
alpha = 0.001 # 步长
# 最大循环次数默认为500
for i in range(maxCycle):
y_hat = dataMatrix * weights
weights = weights - alpha * dataMatrix.transpose()*(y_hat - labelMat).reshape(-1,1)
return weights
法三:利用逻辑回归+梯度下降:
随机梯度下降:
使用随机梯度下降与动态调整步长的随机梯度下降。
'''
sigmoid函数
'''
def sigmoid(inX):
return 1.0 / (1 + np.exp(-inX))
'''
随机梯度下降算法
'''
def stocGradAscent0(dataList, labelList):
dataArr = np.array(dataList) # 数据转化为矩阵
m, n = np.shape(dataArr)
alpha = 0.01
weights = np.ones(n)
for i in range(m):
h = sigmoid(np.sum(dataArr[i]*weights))
error = (h-labelList[i])
weights = weights-alpha*error*dataArr[i]
return weights
'''
改进的随机梯度下降算法
'''
def stocGradAscent1(dataList, labelList, numIter=150):
dataArr = np.array(dataList)
m,n = np.shape(dataArr)
weights = np.ones(n)
for j in range(numIter):
dataIndex = list(range(m))
for i in range(m):
alpha = 4/(1.0+j+i)+0.01 # 步长为动态变化
rand = int(np.random.uniform(0, len(dataIndex)))
choseIndex = dataIndex[rand]
h = sigmoid(np.sum(dataArr[choseIndex]*weights))
error = h-labelList[choseIndex]
weights = weights-alpha*error*dataArr[choseIndex]
del(dataIndex[rand])
return weights
利用逻辑回归模型分类:
该函数以回归系数和特征向量作为输入来计算对应的Sigmoid值,如果Sigmoid值大于0.5则函数返回1,反之返回-1。
def classifyVector(inX, weights):
prob = sigmoid(np.sum(inX * weights))
if prob > 0.5:
return 1
else:
return -1
计算分类精度:
def colicTest(trainWeights, testDataList, testLabelList):
rightCount = 0 # 判断错误的数量
testCount = len(testDataList)
for i in range(testCount):
if int(classifyVector(np.array(testDataList[i]), trainWeights))==int(testLabelList[i]):
rightCount += 1
acc = float(rightCount)/testCount
print("本次的精度为%f" % acc)
return acc
分类结果可视化:
使用matplotlib对分类边界与分类结果进行可视化:
def plotBestFIt(weights, dataMatIn, classLabels):
n = np.shape(dataMatIn)[0]
xcord1 = []
ycord1 = []
xcord2 = []
ycord2 = []
for i in range(n):
if classLabels[i] == 1:
xcord1.append(dataMatIn[i][1])
ycord1.append(dataMatIn[i][2])
else:
xcord2.append(dataMatIn[i][1])
ycord2.append(dataMatIn[i][2])
fig = plt.figure()
ax = fig.add_subplot(111)
ax.scatter(xcord1, ycord1,s=30, c='red', marker='s')
ax.scatter(xcord2, ycord2, s=30, c='green')
x = np.arange(-3, 3, 0.1)
y = (-weights[0, 0] - weights[1, 0] * x) / weights[2, 0] #matix
ax.plot(x, y)
plt.xlabel('X1')
plt.ylabel('X2')
plt.show()
4 结果比较
-
最小二乘法求解:
分类精度与求得W矩阵为:

在测试集上的结果可视化:
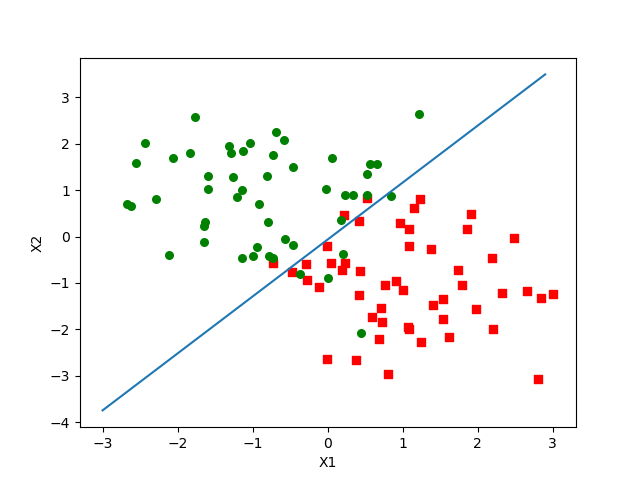
训练集上的分类结果为:
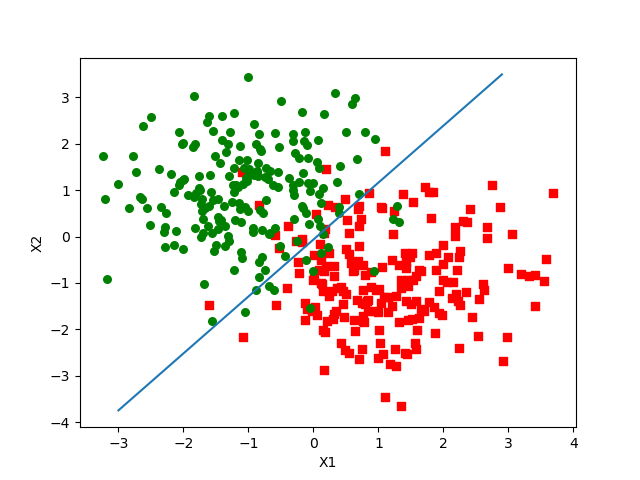
-
线性分类+梯度下降:
分类精度与求得W矩阵为:

在测试集上的结果为:
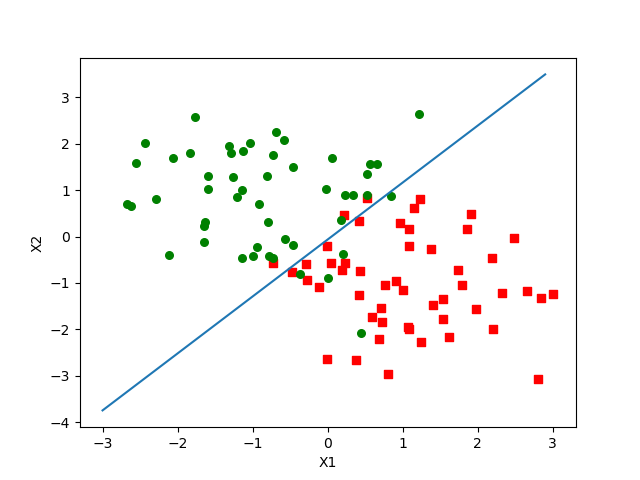
在训练集上的结果为:
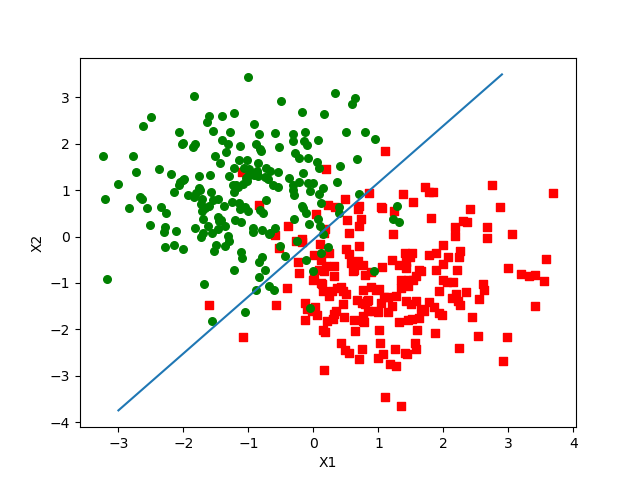
-
逻辑回归+梯度下降:
分类精度与求得W矩阵为:

这里我们也确实观察到了二元逻辑回归W的Norm会不断变大的现象!
在测试集上的结果为:
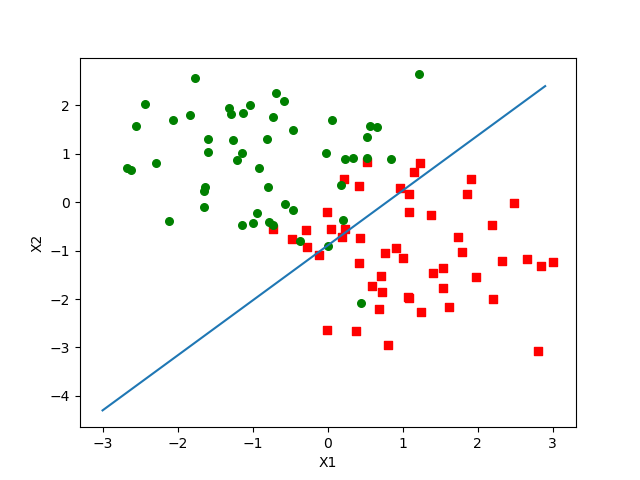
在训练集上的结果为:
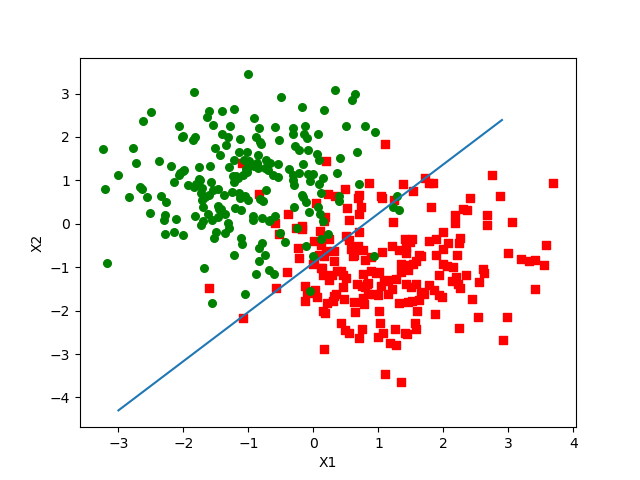
















 2529
2529











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











