







 本文探讨了从One-Hot到预训练语言模型的词嵌入技术,包括N-gram模型、word2vec和BERT。重点介绍了BERT如何利用Transformer学到位置、注意力和语义信息,以及自回归和自编码语言模型的优缺点。
本文探讨了从One-Hot到预训练语言模型的词嵌入技术,包括N-gram模型、word2vec和BERT。重点介绍了BERT如何利用Transformer学到位置、注意力和语义信息,以及自回归和自编码语言模型的优缺点。
词向量(Word Vector)或称为词嵌入(Word Embedding)做的事情就是将词表中的单词映射为实数向量
1.One-Hot
无法反映文本的有序性
无法通过词向量来衡量相关词之间的距离关系
高维情形下将导致数据样本稀疏
解决了分类器不好处理属性数据的问题。
在一定程度上也起到了扩充特征的作用。
2.N-gram模型

用之前的n个文本来计算当前文本的条件概率,一个词的出现不依赖于其他任何词时,称为unigram;当一个词的出现依赖于上一个词时,我们称为bigram
Ngram仅仅解决了文本之间的转移概率的问题,并没有解决文本本身的表征问题。例如,假设我们在训练语料中看到了很多类似“the dog is walking in the bedroom”或是“the cat is running in the bedroom”这样的句子,那么,即使我们看不懂英文,也可以明白“cat”和“dog”(“walking”和“running”)之间是相似的。然而,Ngram模型能描述的只有running出现在“cat”和“dog”之后的概率都很高,但是无法表述“cat”与“dog”是这两个词是相似的
3.词袋-W2V-Bert
词袋模型到word2vec的改进主要集中于以下两点:
考虑了词与词之间的顺序,引入了上下文的信息
得到了词更加准确的表示,其表达的信息更为丰富
BERT利用更深的模型,以及海量的语料,得到的embedding表示,来做下游任务时的准确率是要比word2vec高不少的。给大量的NLP任务提供了一个泛化能力很强的预训练模型
Bert通过transformer学到位置信息、attention信息、语义信息,
4.预训练语言模型
自回归语言模型
通过给定文本的上文,对当前字进行预测,训练过程要求对数似然函数最大化
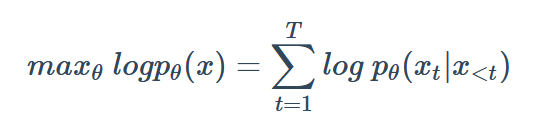
代表模型:ELMo/GPT1.0/GPT2.0/XLNet
优点:该模型对文本序列联合概率的密度估计进行建模,使得该模型更适用于一些生成类的NLP任务,因为这些任务在生成内容的时候就是从左到右的,这和自回归的模式天然匹配。
缺点:联合概率是按照文本序列从左至右进行计算的,因此无法得到包含上下文信息的双向特征表征;
自编码语言模型
BERT系列的模型为自编码语言模型,其通过随机mask掉一些单词,在训练过程中根据上下文对这些单词进行预测,使预测概率最大化
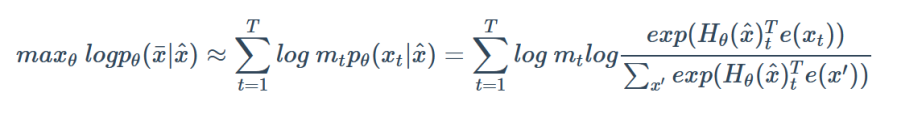
其本质为去噪自编码模型,加入的 [MASK] 即为噪声,模型对 [MASK] 进行预测即为去噪。
优点:能够利用上下文信息得到双向特征表示
缺点:其引入了独立性假设,即每个 [MASK] 之间是相互独立的,这使得该模型是对语言模型的联合概率的有偏估计;另外,由于预训练中 [MASK] 的存在,使得模型预训练阶段的数据与微调阶段的不匹配,使其难以直接用于生成任务。
上一篇:算法面试之transformer的Mask和并行性
下一篇:算法面试之Word2Vec
注:本专题大部分内容来自于总结,若有侵权请联系删除。



















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











