







We call this configuration RoBERTa for Robustly optimized BERT approach. Specifically, RoBERTa is trained with dynamic masking (Section 4.1), FULL-SENTENCES without NSP loss (Section 4.2), large mini-batches (Section 4.3) and a larger byte-level BPE (Section 4.4). ------RoBERTa论文原话
| BERT | RoBERTa | 备注 | |
|---|---|---|---|
| 全称 | Bidirectional Encoder Representations from Transformers | Robustly optimized BERT approach | |
| 预训练数据集 | a combination BOOKCORPUS plus English WIKIPEDIA (16G) | five English-language corpora of varying sizes and domains (160G) | |
| 预训练任务1 | MLM (masked language model, Masked LM) static mask | MLM dynamic mask | MLM: 随机掩盖输入句子中的一些token,目的是基于他的上下文预测被掩盖的词,最终是表示能够融合上下文的含义 |
| 预训练任务2 | NSP (next sentence prediction) with nsp loss | - | NSP: 预测句子B是否是句子A的下一句 |
| text embedding | WordPiece embeddings with a 30k token vocabulary | WordPiece embeddings with a 50k token vocabulary | |
| Optimizer | Adam ( β1 = 0.9,β2 = 0.999 ) | Adam ( β1 = 0.9,β2 = 0.98 ) | |
| activation function | GELU | GELU | |
| batch size | 256 | 8000 | RoBERTa 实验证明,大批量训练提高了MLM,以及最终任务的准确性。 大批量也更容易通过分布式数据并行训练并行化 |
| 应用于下游任务时的epoch | 2~4 | 2~10 | |
| *加粗的位置表示了两者的主要区别 |
BERT和RoBERTa的主要区别总结:
- MLM的动态mask(RoBERTa)和静态mask(BERT)
- 删除了NSP(RoBERTa)
BERT的MLM任务
初始动机:随机掩盖一个句子中的一些词,让模型预测掩盖部分的内容。
初始做法:用[MASK]随机替换一个句子中的15%的单词,让模型预测[MASK]部分对应的单词。
改进原因:微调任务中并不会出现[MASK]的标志,上述做法有违“预训练模型和微调模型基本一致”的目标。
最终做法:对于随机替换的15%的单词中,80%用[MASK]替换,10%保留为原来的单词,10%替换为该句子中的其他词。
好处:a)一定程度上缓解了初始做法导致的预训练模型和微调模型不一致的问题,减少了[MASK]的数量;b)10%保留为原来的词,10%替换为该句子的其他部分,使得模型并不知道输入对应位置的词汇是否为正确的词汇,这迫使模型更多地依赖上下文预测词汇,并赋予了模型纠错的能力。
缺点:在预处理阶段制作[MASK],导致[MASK]单一稳定。
BERT处理这种缺点:预训练共迭代40次,在这期间训练数据被重复处理了10次,每次都更换不同的mask方式,故相同的mask会重复训练4个epoch
RoBERTa对这个缺点的改进:每个epoch都会生成新的mask
对于RoBERTa删掉了NSP任务这件事?
在BERT中,包含两预训练任务:MLM预测被mask掉的位置对应的真实词;NSP预测给定的两个句子是否构成上下句。
原始的BERT假定NSP重要,并发现删掉NSP对一些任务的性能产生了下降的作用。之后,又有一些论文质疑了NSP的必要性。
RoBERTa的作者,为了探究NSP任务的必要性,用一些不同的任务替换NSP任务,探索性能的变化,其中:
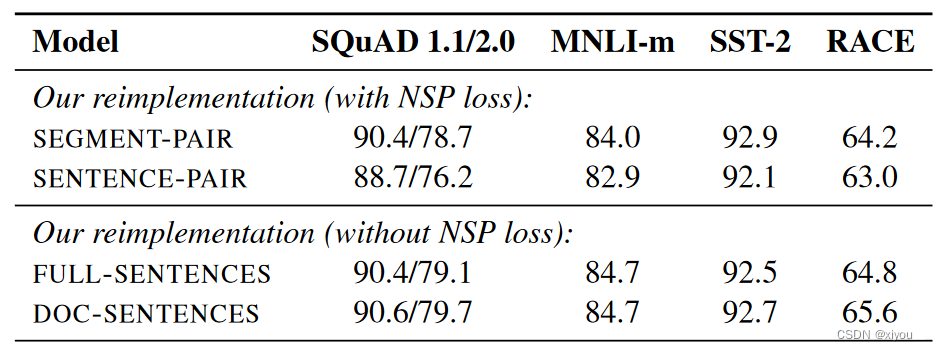
SEGMENT-PAIR+NSP:为原始BERT的NSP任务形式,输入的长度不超过512
SENTENCE-PAIR+NSP:
FULL-SENTENCES:每个输入采样自一个或多个文档的连续的句子,总长度至多512。输入可能是跨文档的,如果我们搜索到了文档的结尾,我们开始从下一个文档的句子采样,并且在不同的文档间用sep token隔开。不使用NSP loss.
DOC-SENTENCES:
上述“用不同任务替换NSP任务”指的是,对BERT的输入形式用其他不同方案替换NSP的两句拼接(50%的时候为上下句,50%的时候随机匹配)的方案,在替换方案中,只有SEGMENT-PAIR+NSP和SENTENCE-PAIR+NSP做了NSP任务,计算了NSP loss,FULL-SENTENCES和DOC-SENTENCES这两种方案只是设计了输入部分的文本构成,并没有做NSP任务。
最终,RoBERTa摒弃了NSP预训练任务。
该链接解答了对BERT的一些疑惑















 1109
1109











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









