









一 专业名词
1 分支断定

2 一致性和同一性

3 常见名词汇总

4 加速比

二 GPU架构构述
GPU就是将cpu的数据存储单元去掉,也就是保留执行单元,GPU就是多个执行单元
1 GPU设计思路,指令流共享,同时执行,数据切分成小块


2 GPU设计思路,单指令多数据处理


分支如何工作,只有一个大脑,8个流输入的是同一段代码,有的是t,有的是f,执行t的时候,f只能等待

停滞的解决方法:用别的独立的工作,来填满空余时间,延迟掩藏
停滞是指等待的过程,数据还没来,前面还没算完

二
1 CPU 和GPU交互


2 GPU线程模型
开发者定义的是线程,以及每个block里面放多少线程






3 CUDA编程








假设只要1个block,block是二维的,i,j对应二维索引


cudaMalloc() 在设备端分配 golbal memory
cudaFree() 释放存储空间
GPU指针分配

数据拷贝函数


Cuda算法框架,通用
第1步:为数据分配GPU空间,将数据从cpu上拷贝到GPU上,同时为输出数据分配内存空间
第2步:在GPU启动并行
第3步:将数据拷贝回CPU,释放GPU上的占用内存

矩阵相乘算法

在GPU启动并行计算矩阵,不需要锁,因为用不到别的部分的数据

假设只使用一个block

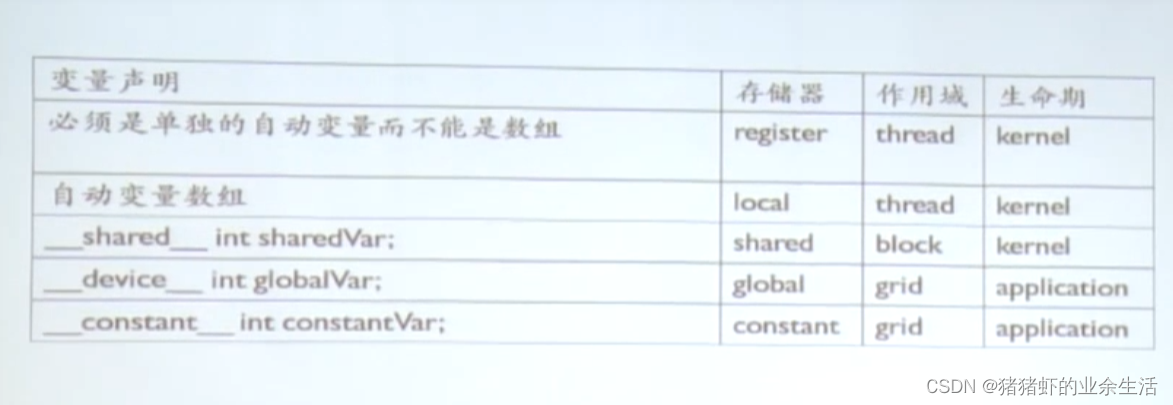
函数声明
主要有三种函数,3个函数声明可以用于同时定义同一个变量

线程同步,一般是局部同步,也就是块内同步,全局同步开销太大
且线程同步之间的任务要时间接近,可以提高效率

如果是采用了以下的这种调用情况,会导致程序逻辑错误

线程调度:软件调用的核数可能会大于实际的硬件核数
调度量不代表执行量,调度过程会存在一些等待的部分

Warp
1个warp是32个线程,block内的线程再次进行分组执行,因为资源有限,一个warp内的数据是默认同步的
一个时间一个block内只有一个warp在执行
一个block只能分配在同一个SM上
变量声明


















 842
842











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









