







聚类算法
K-均值算法
聚类是给定一组数据,将相似的分组。每一个组称为群集
相似性根据算法而变化 ,取决于数据点之间的距离,坐标等。

如每一圈就是一个群集。
-
首先有数据。然后确定群集的数量,这个算法 的特点就是要先确定群集的数量。
这次使用3个群集。
随机 设置三个点作为群集的中心点。

-
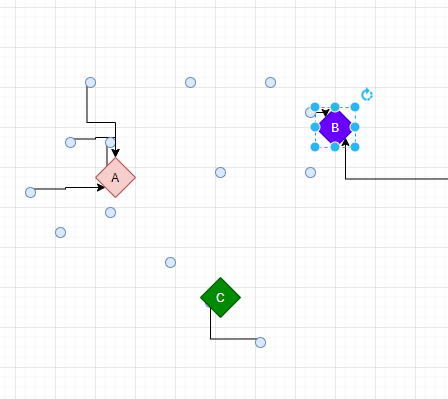
根据每个数据计算并确定最接近的集群的 中心点。
也就是循环第个数据点,计算离 A B C 哪个 点最近 。就归为哪个点的群集中。

直到所有数据分类。

-
计算每个圆圈的重心(每个集群数据的重心),并将集群的中心点(ABC)移动到那里。
-
重新计算 二步骤 ,哪些点离ABC近,分类。再进行移动
-
直到中心点收敛。收敛的意思就是无限接近于某一个值 。
-
数学证明过了,重复操作时,中心点将在某个地方收敛。
-
完成。
注意。:当我们选择 群集数量 为两个的时候。这个算法的效果可就没有那么的肉眼看到的好了。肉眼看起来有三个嘛。
解决办法有:预先分析办法。多次改变 集群数量来尝试K-means算法
列表搜索
线性搜索
就是 一个一个的比较 直到相等为止。没什么好解析的。名字这个高大上。
二分搜索
你心中想定一个范围(N-M)内一个数字,我说出一个数字,你只需要说你心中的数字比我说的大还是小,我最多(M-N-1)/2次可以说出你心中想的数字。
- 每次划分一半,判断大于还是小于还是等于,然后从剩下的一半找。
- 等于则完成 。 没什么好说的。















 9700
9700











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









