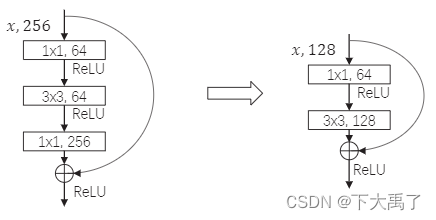
一、网络框架 1、 全新的网络结构:DarkNet-53 2、引入残差 ResNet模块的最后一层11256去掉,而且将倒数第二层3364直接改成33128 3、使用FPN架构实现多尺度检测:13 * 13, 26 * 26, 52 * 52 4、9个先验框,3种尺度下的3个框,对小目标更友好 5、类别预测:将原来用于单标签多分类的softmax层换成用于多标签多分类的逻辑回归层 6、损失函数中x,y,w,h是分别计算的,未统一考虑
























 843
843











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


 被折叠的 条评论
为什么被折叠?
到【灌水乐园】发言
被折叠的 条评论
为什么被折叠?
到【灌水乐园】发言






