









Paper Reading:IsoBN
IsoBN: Fine-Tuning BERT with Isotropic Batch Normalization

任翔组工作. AAAI21. Github(Null). Paper.
1. Intuition
BERT embedding存在各向异性的问题,主要表现为1. 高标准差 2. 不同维度间的高相关性。不利于收敛速度和泛化能力。
解决思路:whitening & batch normalization (Ioffe and Szegedy, ICML 2015)
对PTM在不同数据集上的embedding中不同维度间的相关系数:

可视化分析:
- 相关系数矩阵基本为块对角矩阵。即是一个方阵的块矩阵,主对角的块是方阵,所有非对角的块是零矩阵。
- BERT更易形成大块的聚类,RoBERTa形成的聚类块更小。
PTM在不同数据集上embedding的标准差分布:

可视化分析:
- 不同模型在不同数据集标准差分布差异很大。
- RoBERTa标准差分布相对BERT更为平稳,变化范围较小。
2. 算法实现
2.1 Intuition
白化: h ^ = Σ − 1 2 ( h − μ ⋅ 1 T ) \widehat{\boldsymbol{h}}=\Sigma^{-\frac{1}{2}}\left(\boldsymbol{h}-\boldsymbol{\mu} \cdot \mathbf{1}^{T}\right) h =Σ−21(h−μ⋅1T), Σ \Sigma Σ是输入 h h h的协方差矩阵
批标准化: h ^ = Λ − 1 ( h − μ ⋅ 1 T ) \widehat{\boldsymbol{h}}=\Lambda^{-1}\left(\boldsymbol{h}-\boldsymbol{\mu} \cdot \mathbf{1}^{T}\right) h =Λ−1(h−μ⋅1T), Λ = d i a g ( σ 1 , ⋯ , σ d ) \Lambda=diag(\sigma_1,\cdots,\sigma_d) Λ=diag(σ1,⋯,σd)是输入 h h h每一位度的标准差。
括号前面的就是scaling parameter,其数值表征着放缩力度。

解决方法就是通过聚类将其转化为块对角线矩阵。作者认为,同一簇内维度的绝对相关系数接近1,而来自不同簇的维度几乎不相关。
而所谓的block-diagonal binary matrix 的scaling parameter肯定也是从聚类后的结果出发得到。
2.2 算法步骤

- 首先input embedding h ∈ R n × d h\in\R^{n\times d} h∈Rn×d的维度进行聚类转化为 h ′ ∈ R n × m h^{\prime}\in\R^{n\times m} h′∈Rn×m.
- 计算 u B = 1 m ∑ i = 1 m h i u_B=\frac{1}{m}\sum_{i=1}^m h_i uB=m1∑i=1mhi, σ B = 1 m ∑ i = 1 m ( h i − μ B ) \sigma_B=\sqrt{\frac{1}{m}\sum_{i=1}^m(h_i-\mu_B)} σB=m1∑i=1m(hi−μB), ∑ B = 1 m ( h − μ B ) T ( h − μ B ) \sum_B=\frac{1}{m}(h-\mu_B)^T(h-\mu_B) ∑B=m1(h−μB)T(h−μB).
- 更新时求移动平均值 σ = σ + α ( σ B − σ ) \sigma=\sigma+\alpha(\sigma_B-\sigma) σ=σ+α(σB−σ), ∑ = ∑ + α ( ∑ B − ∑ ) \sum=\sum+\alpha(\sum_B-\sum) ∑=∑+α(∑B−∑)(每个batch都从上一个batch更新迭代。)
- 计算 ρ = ∑ / ( σ σ T ) \rho=\sum/(\sigma\sigma^T) ρ=∑/(σσT)
- 计算 ∣ G g ( i ) ∣ ⟶ ∼ γ i = ∑ j = 1 d ρ i j 2 \left|\mathcal{G}_{g(i)}\right| \stackrel{\sim}{\longrightarrow} \gamma_{i}=\sum_{j=1}^{d} \rho_{i j}^{2} ∣∣Gg(i)∣∣⟶∼γi=∑j=1dρij2 ( ρ \rho ρ是对称阵, ∑ ρ i = ∑ ρ j \sum \rho_i=\sum \rho_j ∑ρi=∑ρj)
- 计算 θ i = ( σ i ⋅ γ i + ϵ ) − β \theta_i=(\sigma_i\cdot\gamma_i+\epsilon)^{-\beta} θi=(σi⋅γi+ϵ)−β,进行白化操作。
- 计算 θ ˉ = ∑ i = 1 d σ i 2 ∑ i = 1 d σ i 2 θ i 2 ⋅ θ \bar{\theta}=\frac{\sum_{i=1}^d\sigma_i^2}{\sum_{i=1}^d\sigma_i^2\theta^2_i}\cdot\theta θˉ=∑i=1dσi2θi2∑i=1dσi2⋅θ,进行BN操作,得到最后的scaling para。(目的是使变换后embedding中的方差之和与原始embedding中的方差之和相同)
- h ^ = θ ˉ ⊙ h \hat{h}=\bar{\theta}\odot h h^=θˉ⊙h
出发点是将cluster内转化成unit-variance, 例如 d = 10 , G 1 : { 1 , 2 , 3 , 4 } , G 2 : { 5 , 6 , 7 } , G 3 : { 8 , 9 , 10 } d=10,G_1:\{1,2,3,4\},G_2:\{5,6,7\},G_3:\{8,9,10\} d=10,G1:{1,2,3,4},G2:{5,6,7},G3:{8,9,10}。
将簇类内部的矩阵中相似的维度转化为unit-variance.
h ^ ( i ) = 1 σ i ⋅ ∣ G g ( i ) ∣ ( h ( i ) − μ i ⋅ 1 T ) \widehat{\boldsymbol{h}}^{(i)}=\frac{1}{\sigma_{i} \cdot\left|\mathcal{G}_{g(i)}\right|}\left(\boldsymbol{h}^{(i)}-\mu_{i} \cdot \mathbf{1}^{T}\right) h (i)=σi⋅∣Gg(i)∣1(h(i)−μi⋅1T)
由于向量维度不能自然地分离到hard group divisions。通过例子可以发现,相似度高的clutster中的 γ \gamma γ值也基本相同。本例中假设 d = 4 , G 1 : { 1 , 2 } , G 2 : { 3 } , G 3 : { 4 } d=4,G_1:\{1,2\},G_2:\{3\},G_3:\{4\} d=4,G1:{1,2},G2:{3},G3:{4}。
ρ = ∣ 1 0.9 0.5 0.1 0.9 1 0.6 0 0.5 0.6 1 0.4 0.1 0 0.4 1 ∣ \rho=\left|\begin{array}{llll}1 & 0.9 & 0.5 & 0.1 \\ 0.9 & 1 & 0.6 & 0 \\ 0.5 & 0.6 & 1 & 0.4 \\ 0.1 & 0 & 0.4 & 1\end{array}\right| ρ=∣∣∣∣∣∣∣∣10.90.50.10.910.600.50.610.40.100.41∣∣∣∣∣∣∣∣
ρ 1 = 2.07 , ρ 2 = 2.17 , ρ 3 = 1.77 , ρ 4 = 1.17. \rho_1=2.07,\rho_2=2.17,\rho_3=1.77,\rho_4=1.17. ρ1=2.07,ρ2=2.17,ρ3=1.77,ρ4=1.17.
则通过步骤4简化为:
h ^ ( i ) = 1 σ i ⋅ γ i ( h ( i ) − μ i ⋅ 1 T ) \widehat{\boldsymbol{h}}^{(i)}=\frac{1}{\sigma_{i} \cdot \gamma_{i}}\left(\boldsymbol{h}^{(i)}-\mu_{i} \cdot \mathbf{1}^{T}\right) h (i)=σi⋅γi1(h(i)−μi⋅1T) (soft version)
γ i \gamma_i γi大,相关度高, 1 γ i \frac{1}{\gamma_i} γi1压缩力度大。
IsoBN接在最终的分类器前面。
3. 实验结果
3.1 数据集结果
IsoBN适用于文自然语言推断(文本蕴涵)、句子对匹配、文本分类等数据集。平均提升了0.8%-1%左右。

3.2 各向同性测评
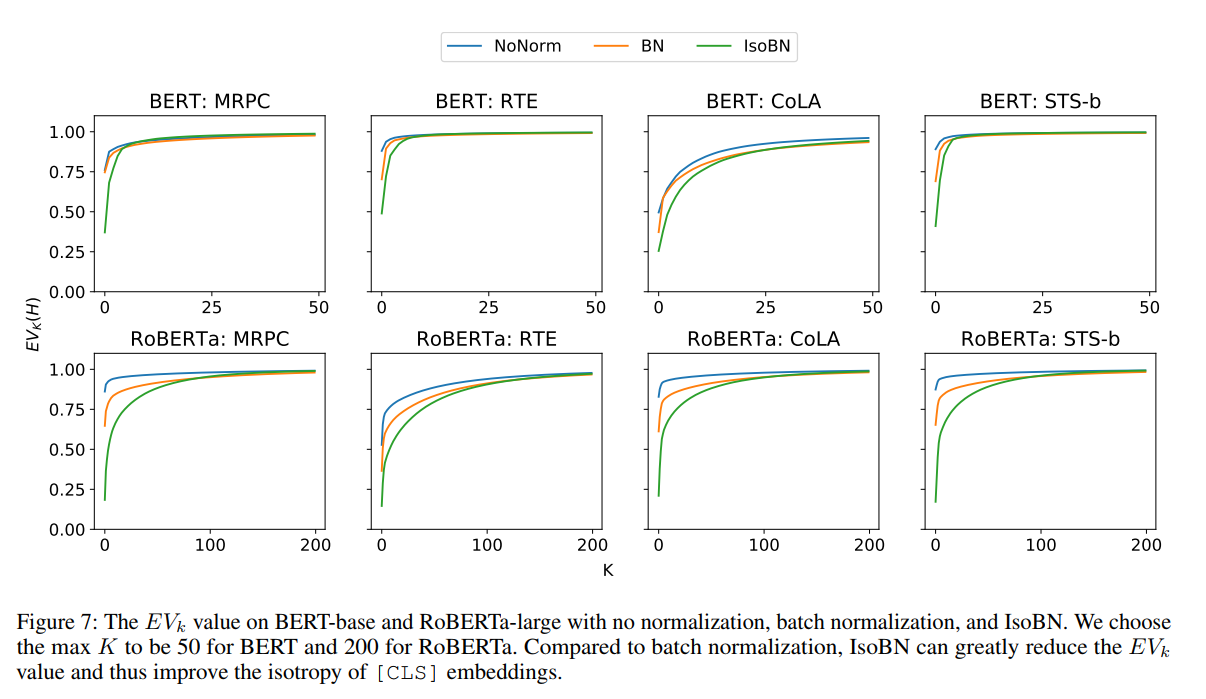
利用方差贡献率 E V k ( h ) = ∑ i = 1 k λ i 2 ∑ i = 1 d λ j 2 EV_k(h)=\frac{\sum_{i=1}^k\lambda^2_i}{\sum_{i=1}^d\lambda^2_j} EVk(h)=∑i=1dλj2∑i=1kλi2衡量了空间中不同方向的向量的方差差异。如果前几维 E V k EV_k EVk较小,说明向量标准差分布在各个方向上较为平缓,若 E V k EV_k EVk越大,向量空间将退化为一个狭窄的锥体。

在进行IsoBN之后的向量表示明显 E V k EV_k EVk都有了明显的下降,有效地消减了各向异性。















 703
703











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









