









Paper reading: Fusing label Embedding into BERT: An Efficient Improvement for Text Classification

Paper Url,东京工业大学,Findings of ACL-IJCNLP 2021.
2.1 摘要
随着BERT等PTM越来越受到关注,人们做了大量的研究来进一步提升它们的能力,从增强实验程序到改进数学原理。在本文中,我们提出了一种简洁的利用标签嵌入技术方法来提高BERT在文本分类中的性能,同时保持几乎相同的计算代价。在六个文本分类benchmark datasets上的实验结果证明了该方法的有效性。
2.2 模型
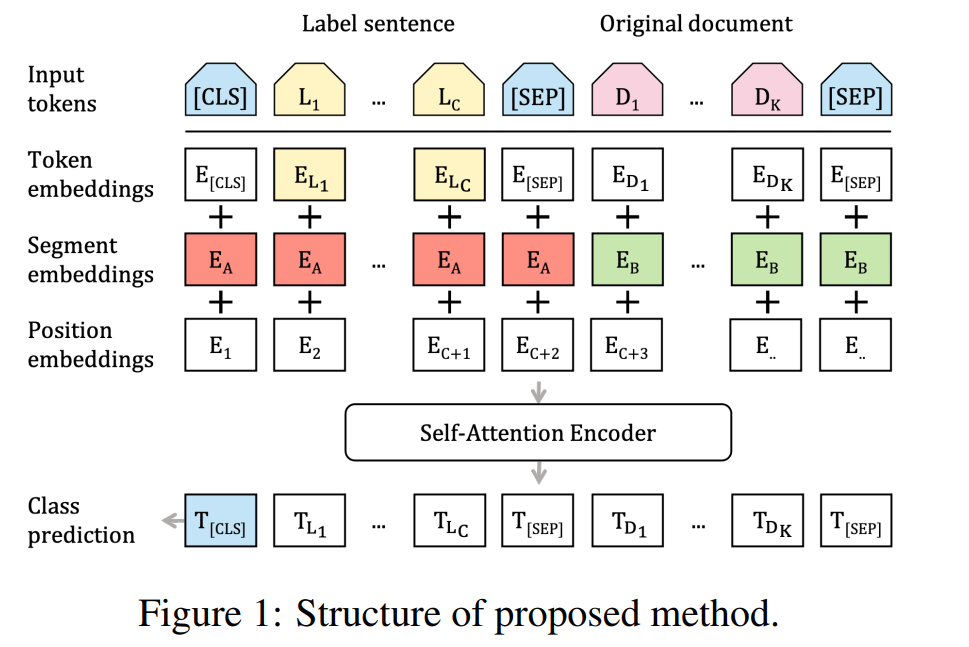
L j ∈ [ L 1 , ⋯ , L C ] L_j\in[L_1,\cdots,L_C] Lj∈[L1,⋯,LC]代表label的文本, D i ∈ [ D 1 , ⋯ , D K ] D_i\in[D_1,\cdots,D_K] Di∈[D1,⋯,DK]代表label的文本。
To be mention,如果一个
L
j
L_j
Lj中包含多个文本即’sub-words of a label’,比如agnews中的Sci\Tech标签,就输入了Science Technology的文本,则整体输入的label text就为world, sports, business, science technology。comma与否也是有区别的:

然后经过Token Embeddings 表示,将同一label下的sub-words都求平均。然后借鉴了句子匹配任务的思想,将sentence pair input通过segment embedding进行区分。后文实验中采用了该种称之为w/ [SEP],将没有用segment embedding单纯将label text和content text拼在一起的称之为w/o [SEP]。
后面同正常文本分类相同,通过整体[CLS] embedding接上tanh线性层进行分类,通过交叉熵损失训练。
最后通过TF-IDF拓展label类别的token种类:在训练集中同一类别下面都用BERT tokenizer分词后计算TF-IDF值选出最高的5个10个20个词扩充label name.
2.3 实验效果
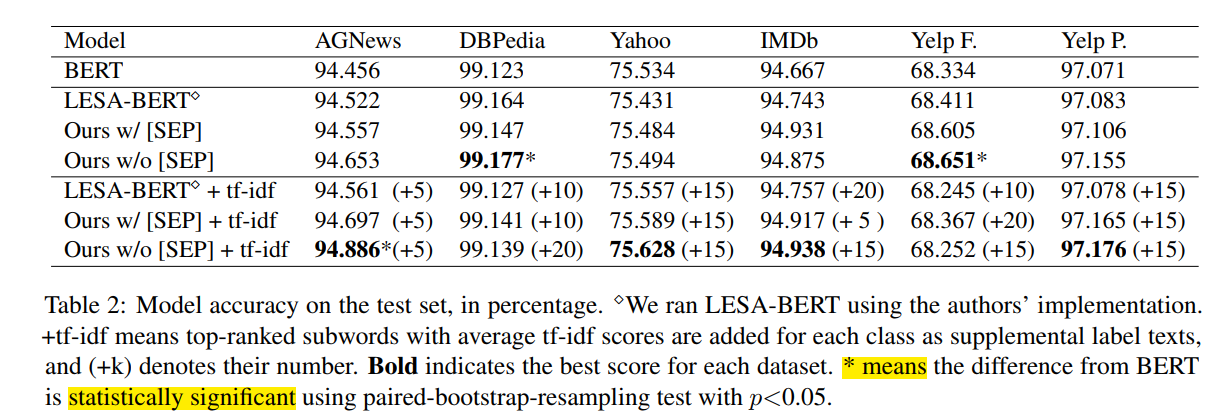
可以明显的看到不对句子pair input作区分w/o [SEP]取得了更好的效果。NSP任务在Bert pretrain阶段是用于预测下一个句子的。当我们将标签序列与输入文档连接时,[SEP]标记将非自然语言序列与自然语言句子组合在一起。这种差异可能导致了前训练和BERT微调之间的偏斜度,导致性能下降。

2.4 优缺点分析
- 优点:借鉴了MTLE句子匹配任务,将所有的label空间都feed给Encoder,让self-Attention去学content_text和label_text的相似性。
- 缺点:没考虑构建label和content相似性的similarity_input.















 5215
5215











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









