







1. 什么是NER任务
NER即命名实体识别任务,主要目的是识别出一个句子中的实体词,以及其对应的实体类型。比如下面的例子中,就是不同场景下的NER任务。在不同场景中,需要识别的实体类型也是不同的。
NER任务的基本解决方法当成一个序列分类任务,一般采用BIO、BIOES等标注预测方法,BIO标注方法,就是给句子中的每一个单词都标注一个标签,这个标签由两部分组成:一部分是该单词所属实体的位置,其中B表示该单词是实体的第一个单词,I表示该单词是实体的中间单词,O表示不是实体;另一部分是该单词对应的实体类型,例如在上面的News类型NER任务中,就需要预测单词属于location还是person。因此,最终每个单词都被标注为BIO+实体类型的形式,这是一个文本序列分类任务。
一、简介
在UIE出来以前,小样本NER主要针对的是英文数据集,目前主流的小样本NER方法大多是基于prompt,在英文上效果好的方法,在中文上不一定适用,其主要原因可能是:
-
中文长实体相对英文较多,英文是按word进行切割,很多实体就是一个词;边界相对来说更清晰;
-
生成方法对于长实体来说更加困难。但是随着UIE的出现,中文小样本NER 的效果得到了突破。
二、主流小样本NER方法
2.1、EntLM
EntLM该方法核心思想:抛弃模板,把NER作为语言模型任务,实体的位置预测为label word,非实体位置预测为原来的词,该方法速度较快。模型结果图如图2-1所示:
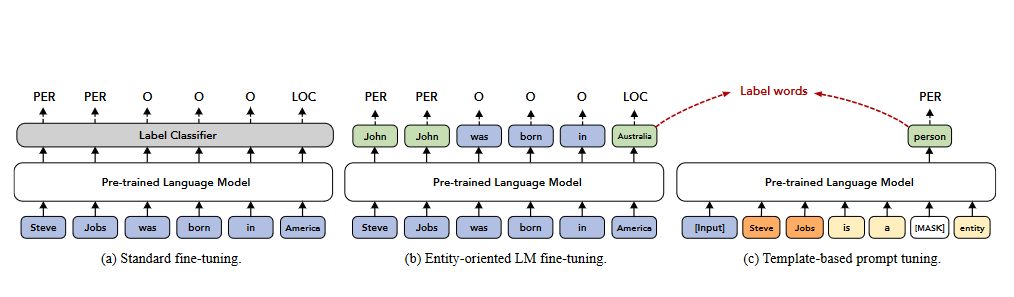
图2-1 EntLM模型
论文重点在于如何构造label word:在中文数据上本实验做法与论文稍有区别,但整体沿用论文思想:下面介绍了基于中文数据的标签词构造过程;
-
采用领域数据构造实体词典;
-
基于实体词典和已有的实体识别模型对中文数据(100 000)进行远程监督,构造伪标签数据;
-
采用预训练的语言模型对计算LM的输出,取实体部分概率较高的top3个词;
-
根据伪标签数据和LM的输出结果,计算词频;由于可能出现在很多类中都出现的高频标签词,因此需要去除冲突,该做法沿用论文思想;
-
使用均值向量作为类别的原型,选择top6高频词的进行求平均得到均值向量;
-
详细介绍如下:
















 496
496











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











