







作者:孔令宇,中国科学院大学直博在读。
个人主页:https://www.kppkkp.top
在工作 Vary 中,我们第一次提出了CLIP视觉词表在密集感知能力上的不足,并给出了一种简单有效的扩充词表方案。Vary发布后得到了不少朋友的关注(目前已1.2k+ star),但也有不少人因为资源受限运行不了。
考虑到目前开源得很好且性能出色的“小”VLM比较少,我们新发布了“年轻人的第一个多模大模型”——1.8B Vary-toy,并以最大的诚意欢迎各位高校和个人研究者们加入多模态大模型的研究中。当然也欢迎大佬们用它做出有意思的落地应用,把Vary-toy玩起来!
与Vary相比,Vary-toy除了小之外,我们还优化了新视觉词表。解决了原Vary只用新视觉词表做pdf ocr的网络容量浪费,以及吃不到SAM预训练优势的问题。与Vary-toy同时发布的还有更强的视觉词表网络,其不仅能做pdf-level ocr,还能做通用视觉目标检测。
Vary-toy在消费级显卡可训练、8G显存的老显卡可运行,依旧支持中英文!我们希望Vary-toy能当好一个结构简单、能力全面、性能可比的baseline的角色,因此这个“小”VLM几乎涵盖了目前LVLM主流研究中的所有能力:Document OCR、Visual Grounding、Image Caption、VQA…… 技术报告在这里:Small Language Model Meets with Reinforced Vision Vocabulary。
https://arxiv.org/abs/2401.12503

如果我们的工作对你有所帮助,也希望能在Github为我们点上一个 Star!Github地址:
https://github.com/Ucas-HaoranWei/Vary-toy/tree/main
Demo地址(1080ti部署,卡的话刷新一下):
https://vary.xiaomy.net/
技术介绍
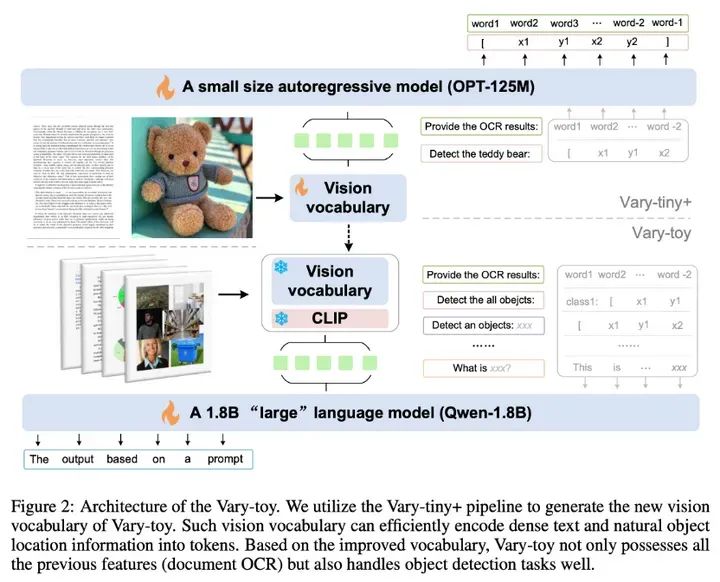
Vary-toy的模型结构和训练流程如上图所示,大体上继承了Vary,使用Vary-tiny+结构,pretrain出一个更好的视觉词表,然后将训好的视觉词表merge到最终结构进行multi-task training/SFT。
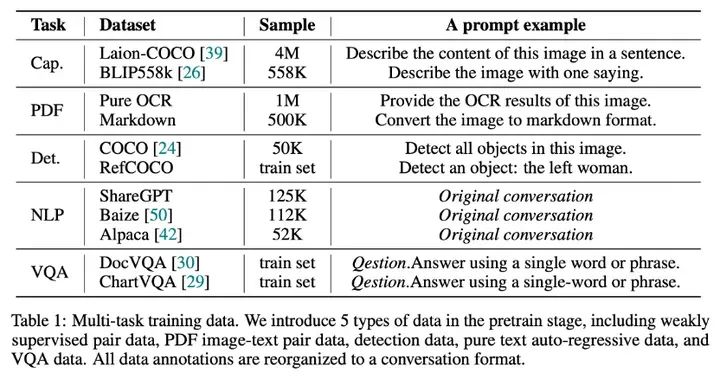
众所周知一个好的数据配比对于产生一个能力全面的VLM是很重要的。因此在pretrain阶段,我们使用了5种任务类型的数据构建对话,数据配比和示例prompt如下;而在SFT阶段,我们只使用了LLaVA-80K数据。
性能展示
Vary-toy在DocVQA、ChartQA、RefCOCO、MMVet四个benchmark的得分如下:
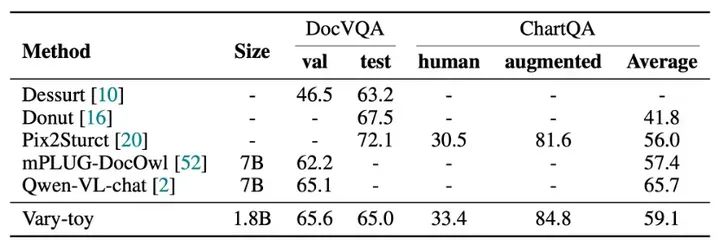
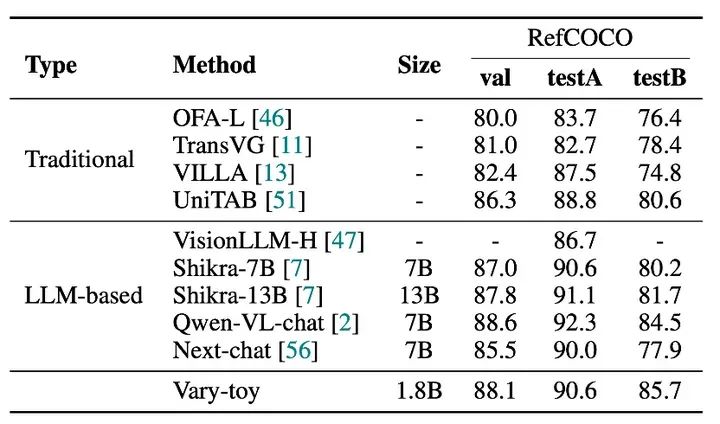
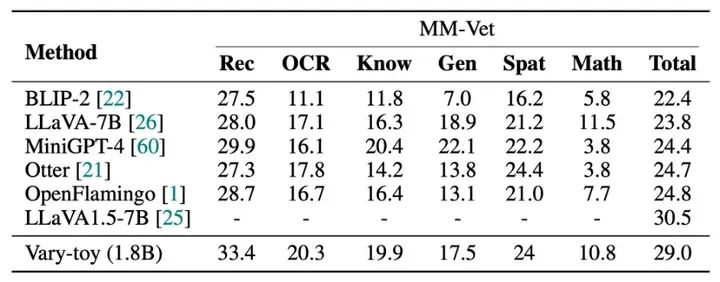
模型的性能基本on par 流行的7B模型。
一些可视化的例子如下,更多例子见demo[1]网页,

可以看到无论是从刷点上还是可视化效果上,不到2B的Vary-toy甚至能和一些知名7B模型碰一碰。
虽然我们略带自嘲地起名为“toy”,但是Vary-toy 可能比想象中更有应用潜力。基于Vary-toy我们也做了两个非常不错的应用,效果见:
https://github.com/Ucas-HaoranWei/Vary-family
无论你是初学者,做毕设,还是做深度研发,我相信Vary-toy都会是一个很好的选择。
引用链接
[1] : https://vary.xiaomy.net/
















 117
117

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











