









系列文章目录
记录自己对mmsegmentation的理解(即原文档的注释版),新手小白写的文档,不对的地方请指出,具体细节可以直接查看原文档mmSegmentation中文文档
- 训练&测试
- 基本概念
- 自定义组件
1、数据流
这里将介绍Runner管理的内部模块之间的数据流和数据格式约定
1.1 基础概念
Runner是各个模块之间的集成器,负责组织和调度所有模块,下面展示了基本的数据流(mmseg中初始设置的数据流,并没有修改TrainLoop、ValLoop、TestLoop、TrainStep等):
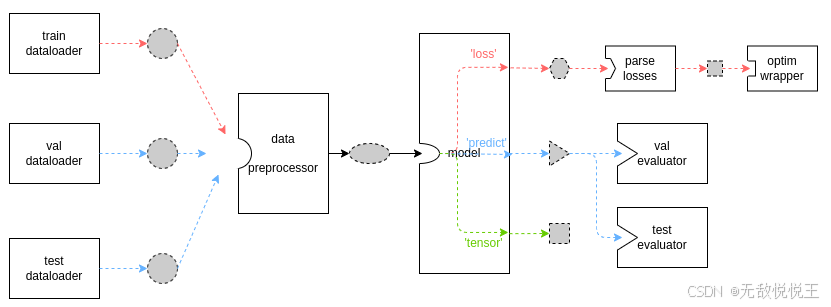
上图所示数据流仅适用于当用户没有自定义 Runner 中的 TrainLoop、ValLoop 和 TestLoop,并且没有在其自定义模型中覆写 train_step、val_step 和 test_step 方法时。红色线表示 train_step,在每次训练迭代中,数据加载器(dataloader)从存储中加载图像并传输到数据预处理器(data preprocessor),数据预处理器会将图像放到特定的设备上,并将数据堆叠到批处理中,之后模型接受批处理数据作为输入,最后将模型的输出发送给优化器(optimizer)。蓝色线表示 val_step 和 test_step。这两个过程的数据流除了模型输出与 train_step 不同外,其余均和 train_step 类似。由于在评估时模型参数会被冻结,因此模型的输出将被传递给 Evaluator。 来计算指标。
1.2 dataloader到preprocessor
DataLoader 从文件系统加载数据,原始数据通过数据准备流程后被发送给数据预处理器,这个与pytorch中的dataloader一致。
pipeline的流程如下:

MMSegmentation 在 PackSegInputs 中定义了默认数据格式, 它是 train_pipeline 和 test_pipeline 的最后一个组件,作用是将原始数据封装成model可以直接使用的格式。在没有任何修改的情况下,PackSegInputs 的返回值通常是一个包含 inputs 和 data_samples 的 dict。
PackSegInputs
1、类注册

1、注册机制:将类注册到MMSegmentation流水线中,允许在配置文件中通过dict(type=‘PackSegInputs’)调用
2、核心功能:作为数据预处理流水线的最后一步,将分散在results字典中的图像、标注和元数据封装为模型可直接处理的标准化格式(inputs和data_samples)。
2、初始化变量

3、输入图像处理(packed_results[‘inputs’])
首先判断输入的原始图像是否是灰色图,若是灰色图,则扩展维度。
再将H,W,C维度转为C,H,W,变成pytorch处理的格式
最后将图像转为tensor格式,并进行连续内存优化。

4、标签处理(packed_resluts[‘data_samples’])
PackSegInputs类将初始数据转换成model可以处理的数据类型,返回值为packed_results,这是一个字典变量,里面有两个关键值:inputs和data_samples。inputs是输入的原始图像,data_samples是标签数据。
data_sample = SegDataSample()
data_samples将SegDataSample()类实例化,SegDataSample 类通过Python的@property装饰器实现了对分割数据的封装管理。这些代码的作用是定义标准化的属性访问接口,确保数据类型的正确性和框架的扩展性。setter方法用于设置属性值,deleter方法用于删除属性值
class SegDataSample(BaseDataElement):
@property
#Python的@property允许将方法转换为“看似属性访问”的接口
#Getter方法,获取属性值
def gt_sem_seg(self) -> PixelData:
return self._gt_sem_seg
@gt_sem_seg.setter
#Setter方法,设置属性值
def gt_sem_seg(self, value: PixelData) -> None:
self.set_field(value, '_gt_sem_seg', dtype=PixelData)
@gt_sem_seg.deleter
#deleter方法,删除属性值
def gt_sem_seg(self) -> None:
del self._gt_sem_seg
.........
gt_sem_seg、pred_sem_seg和seg_logits是SegDataSample类中三个核心字段,分别承担不同的语义分割任务功能。
- gt_sem_seg:真实语义分割标注,存储图像中每个像素的真实类别标签,是模型训练时的监督信号。
- pred_sem_seg:模型预测的分割结果,通过argmax操作从seg_logits中提取。
- seg_logits:未归一化的模型输出,是模型最后一层未经过Softmax或Sigmoid归一化的原始输出,包含每个像素的类别置信度。其数值范围无限制,可用于灵活调整阈值或计算损失。
语义分割标注处理
if 'gt_seg_map' in results:
if len(results['gt_seg_map'].shape) == 2: # 二维标注处理
data = to_tensor(results['gt_seg_map'][None,...].astype(np.int64)) # 添加通道维度
else: # 异常维度处理
warnings.warn(...) # 警告非标准格式
data = to_tensor(results['gt_seg_map'].astype(np.int64)) # 强制类型转换
data_sample.gt_sem_seg = PixelData(**dict(data=data)) # 封装为像素数据结构
多任务数据处理-边缘检测标注

多任务数据处理-深度估计标注

元数据整合
img_meta = {}
for key in self.meta_keys: # 遍历预设元数据字段
if key in results:
img_meta[key] = results[key] # 提取关键参数
data_sample.set_metainfo(img_meta) # 注入元信息
packed_results['data_samples'] = data_sample
return {
'inputs': torch.Tensor, # 图像张量(C,H,W)
'data_samples': SegDataSample # 含标注与元数据
}
1.3 preprocessor到model
虽然在上面的图中分开绘制了数据预处理器和模型,但数据预处理器是模型的一部分,数据预处理器的返回值是一个包含 inputs 和 data_samples 的字典,其中 inputs 是批处理图像的 4D 张量,data_samples 中添加了一些用于数据预处理的额外元信息。当传递给网络时,字典将被解包为两个值。 以下伪代码展示了数据预处理器的返回值和模型的输入值。
dict(
inputs=torch.Tensor,
data_samples=List[SegDataSample]
)
class Network(BaseSegmentor):
def forward(self, inputs: torch.Tensor, data_samples: List[SegDataSample], mode: str):
pass
1.4 model输出
前向传播有三种模式:训练、验证、推理。
- 训练阶段
- 数据流向:输入图像经过数据增强后,通过backbone提取特征,通过decode_head生成seg_logits(未归一化的类别置信度张量)
- 验证阶段
- 数据流向:禁用数据增强,模型生成pred_sem_seg(通过argmax操作后的分割掩膜)
- 评估机制:通过Evaluator计算mIoU(交并比)、Dice系数等指标
- 推理阶段
- 数据流向:与验证阶段类似,但无需加载真实标注
- 输出形态:生成纯预测结果的SegDataSample,用于可视化或导出应用(如自动驾驶障碍物分割)
与数据预处理器一致,损失函数也是模型的一部分,它是解码头的属性之一。在 MMSegmentation 中,decode_head 的 loss_by_feat 方法是用于计算损失的统一接口。注意:train_step 将损失传递进 OptimWrapper 以更新模型中的权重,更多信息请参阅 train_step。
loss_by_feat
1、函数定义和参数
def loss_by_feat(self, seg_logits: Tensor, batch_data_samples: SampleList) -> dict:
计算分割任务的损失,支持多损失函数组合与采样策略。seg_logits:解码头输出的未归一化logits(形状为(B, C, H, W)), batch_data_samples:包含标注和元信息的SegDataSample列表。
2、标签准备于尺寸对齐
seg_label = self._stack_batch_gt(batch_data_samples) # 将标注堆叠为(B, 1, H, W)
loss = dict()
seg_logits = resize( # 调整logits尺寸至标注大小
input=seg_logits,
size=seg_label.shape[2:],
mode='bilinear',
align_corners=self.align_corners)
_stack_batch_gt:将批次中的gt_sem_seg堆叠为张量,例如从[SegDataSample1, …]转换为(B, 1, H, W)。
3、像素权重计算
if self.sampler is not None: # 应用采样器(如OHEM或类别平衡)
seg_weight = self.sampler.sample(seg_logits, seg_label)
else:
seg_weight = None
seg_label = seg_label.squeeze(1) # 压缩为(B, H, W)
4、多损失函数计算
# 将loss_decode转换为列表(支持多损失组合)
if not isinstance(self.loss_decode, nn.ModuleList):
losses_decode = [self.loss_decode]
else:
losses_decode = self.loss_decode
# 遍历所有损失函数并累加结果
for loss_decode in losses_decode:
loss_name = loss_decode.loss_name # 如'loss_ce'、'loss_dice'
if loss_name not in loss:
loss[loss_name] = loss_decode(
seg_logits, seg_label,
weight=seg_weight,
ignore_index=self.ignore_index)
else:
loss[loss_name] += loss_decode(...)
#---------------------------------配置展示------------------------------
# 组合交叉熵与Dice损失
loss_decode = nn.ModuleList([
CrossEntropyLoss(loss_weight=1.0),
DiceLoss(loss_weight=0.5)
])
5、准确率计算
loss['acc_seg'] = accuracy( # 像素级准确率
seg_logits, seg_label,
ignore_index=self.ignore_index)
首先对seg_logits执行argmax获得预测类别。其次统计与seg_label匹配的像素数,排除ignore_index指定值。最后计算正确率:正确像素数 / 有效像素总数。

















 1822
1822

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









