







关键词:#树莓派小车 #opencv #神经网络 #自动驾驶 #python3
概要:设计一个可以自动驾驶的小车,能实时分析摄像头采集到的数据,完成左右转向的判断和执行,使其可以保持在车道上。
原理简述:先通过数据采集的python脚本,手动操控小车的同时用车载摄像头采集神经网络所需要的图像数据。每次手动按键操控都将自动拍摄一张图片,拍摄到的图片在经过压缩、裁剪、滤波、灰度处理、大津二值化之后,通过numpy模块将图像像素矩阵重塑成一维数组,并打上左转、右转或是直行的标签,最后打包生成一个numpy的npz文件来保存一次运行的全部数据。在多次运行收集到一定量的数据之后,将数据传到电脑上进行神经网络的训练。训练的结果以xml文件的形式传回树莓派,供自动驾驶脚本读取。自动驾驶的过程中主要参照xml文件中的结果来进行判断。
文章目录
1 总体流程设计

1.分别在树莓派和本地配置好python3.7和opencv的环境
2.测试在本地通过pygame模块用键盘远程控制小车移动
3.测试树莓派端的摄像头图像获取
4.在树莓派端通过python脚本(myCollectData.py)实现神经网络的数据采集
5.将树莓派端采集的npz向量数据传回本地,通过python脚本(train.py)进行神经网络模型训练,生成xml结果
6.将训练结果xml传回到树莓派,通过python脚本(LoadData.py)读取训练结果,实现在树莓派的实时路线判断和自动驾驶
2 OPENCV在上位机(macOS)的环境配置
用的是anaconda+opencv+pycharm。
这个部分网上的教程是很多的,在这里就不贴出了。
为了之后的程序使用,不要忘记添加numpy和pygame包。
3 测试:基于pygame的keybDrive.py脚本——“遥控车”
实现在电脑上按下“wasd”、“qezc”或者“上下左右”可以控制小车的移动。按键和移动方式的具体对应关系如下:
| 按键 | 移动方式描述 | 调用函数 |
|---|---|---|
| w/up | 前进 | t_up(100,100) |
| a/left | 左转 | t_left(100,100) |
| s/down | 倒退 | t_down(100,100) |
| d/right | 右转 | t_right(100,100) |
| q | 前进-左前 | t_up(50,100) |
| e | 前进-右前 | t_up(100,50) |
| z | 后退-左后 | t_down(50,100) |
| c | 后退-右后 | t_down(100,50) |
在代码中的体现如下:
import pygame
……
try:
while True:
for event in pygame.event.get():
if event.type == KEYDOWN:
keys = pygame.key.get_pressed()
if keys[pygame.K_w]:
t_up(100,100)
print("forward")
elif keys[pygame.K_s]:
t_down(100,100)
print("back")
elif keys[pygame.K_q]:
t_up(50,100)
print("left")
elif keys[pygame.K_e]:
t_up(100,50)
print("right")
elif keys[pygame.K_z]:
t_down(50,100)
print("left back")
elif keys[pygame.K_c]:
t_down(100,50)
print("right back")
elif keys[pygame.K_a]:
t_left(100,100)
print("turn left")
elif keys[pygame.K_d]:
t_right(100,100)
print("turn right")
break
elif event.type == KEYUP:
t_stop(0)
print("stop")
except KeyboardInterrupt:
GPIO.cleanup()
需要注意的是,keybDrive.py中的控制方法和后面myCollectData.py和LoadData.py的控制方法是相同的,但是其中的参数不同。keybDrive.py仅作为测试代码使用。
4 测试:图像获取——启动摄像头
目的是测试一下小车的摄像头是否正常工作,端口是否正确。以下为测试代码的一部分:
import cv2
……
# get a frame
ret, frame = cap.read()
# show a frame
cv2.imshow("capture", frame)
如果正常运行的话屏幕上会出现一个名叫“capture”的窗口,里面显示当前摄像头正在拍摄的画面。如果拍摄正常的话代表摄像头工作正常,同时说明了opencv模块安装正确,没有环境上的问题。
在验证小车键盘操作无误和摄像头工作正常之后即可开始下一步工作。
5 小车跑道设计
此次跑道的设计主要考虑以下因素:
(1) 首先,由于之后要由摄像头实时判断前进路线,且硬件设备能力有限,此次的跑道设计需要足够宽,但同时要保持宽度的一致性,且转弯弧度不要太大,给小车一定的容错空间。
(2) 至少需要由左转、右转和直行道。
(3) 由于做的是基于图像识别的神经网络模型,所以可以出现一些车道线之外的东西,例如一个十字路口,来模拟现实交通情况,同时增加难度,作为本次简单自动驾驶设计的吸睛点,以体现神经网络的优越性。
(4) 该跑道应该是一个环线,这样之后在收集训练数据的时候可以减少人为干预,可以通过键盘遥控来让小车一直保持在轨道上,减少体力劳动。

如图所示,本次跑道设计由两根车道线组成,不仅有左转道、右转道、直行道、还有一个十字路口。路口使用了重复的小短线来模拟现实的斑马线。小车需要按照图中所标注的方向前进,且在经过路口时需要保持直行。
6 小车摄像头固定
小车在行驶过程中摄像头需要保持稳定,尽量不能有震动、晃动等会影响结果判断的因素出现,同时摄像头最好能够看清前方的两根车道线,所以需要摄像头架在一个比较高的位置。

用纸板差不多搭了一个,哈哈哈:D
7 数据采集
运行数据采集的python脚本——myCollectData.py,我将手动操控小车,同时用车载摄像头采集神经网络所需要的图像数据。
样本采集的思路为按下某个按键时,同时记录当前画面,并对其添加该按键的标签,比如按下“左转“键时,记录下当前画面,并加入一个”左转“的标签。其他方向同理,这里只用三个标签,分别是:”前进“、”左转“、”右转“。而为了减少画面中的干扰,对画面进行一系列处理,处理过程为:压缩、裁剪、滤波、灰度处理、大津二值化,最终使用二值化后的图像作为样本。
接下来从各个部分对数据采集的过程进行讲解。
在之前的基础上,小车已经可以通过键盘遥控行驶,现在需要调用摄像头采集前方跑道的图像,并遥控小车采集数据,需要在之前的keybDrive.py上添加新的功能。
图像处理就要用到OpenCV来作为工具,那么第一步先调用摄像头,因为树莓派性能做实时处理还有些难度,所以将采集的图像像素进行压缩,具体代码如下:
import cv2
self.cap = cv2.VideoCapture(1) # 调用video1
self.cap.set(3,320) # 像素宽度
self.cap.set(4,240) # 像素高度
摄像头拍摄的效果大概是这样(糊了是意外):

这样,就会将摄像头采集的图像设置为320*240像素。而调用过后还需要读取摄像头,所以使用函数:ret, cam = self.cap.read()
这个cam变量就可以看作摄像头,每次使用摄像头只需要调用cam就可以。在实际的操作中,摄像头中的画面基本只有下半部分是地面,上半部分没有什么用,所以只选取下半部分作为我们感兴趣的区域,这样既减少硬件的运算,又减少非地面部分的干扰。这里就更加简单了,只需要非常短的代码:roi = cam[120:240, :] # 120:240

将直接取得的画面经过一些列处理,包括滤波、灰度和大津二值化等,得到最后的图像处理结果如下:

这里调用的变量是环环相扣的,先调用cam获得图像,再对cam进行一系列的滤波,灰度,二值化的处理。
图像的本质是一个大号像素矩阵,其中每个像素的灰度颜色在0~255变化(二值化后只有0和255了),这里就要用到Python中的numpy模块了,numpy模块是专门用于矩阵运算的数学运算模块,使用numpy可以非常方便的将图像像素矩阵重塑成一维数组,方便存储。
以下为采集程序的大概思路:
- 创建一个图像空矩阵(1行, 38400列)和一个标签空矩阵(1行,3列)。
image_array = np.zeros((1, 38400)) label_array = np.zeros((1, 3), 'float’)
- 在小车行驶的过程中,将实时处理过的图像数据放置在一个临时矩阵中。
temp_array = th3.reshape(1,38400).astype(np.float32)
- 每当按下前进或者左右键时(分别是w,q和e),将临时矩阵中的数据存放在先前创建的空矩阵中,并赋予标签矩阵一个标签值。
image_array = np.vstack((image_array, temp_array))
label_array = np.vstack((label_array, self.k[0])) #k[i],i=0,1,2
- 将每一次写入的图像矩阵和标签矩阵保存在train和train_label中。
train = image_array[1:, :] train_labels = label_array[1:, :]
- 最后将数据文件保存为numpy的npz文件。
这个程序有一个缺点就是不能实时存储并释放内存,每次占用内存超过300M以后就开始运行拖慢,大概是存入240个数据,或者是运行五分钟左右的时候。所以这时候需要一个停止程序的按键,将采集的数据从内存存入硬盘,重新运行采集程序。在本次程序设计中,按下“p”键,数据采集就会停止,并储存一次npz数据。
不算上之前没有用的数据,我一共采集了3500张数据用于训练最终的xml文件。然而总共大概拍了10000张左右,这个过程很枯燥,不过最后看到小车自己可以跑的时候很欣慰,这枯燥的时间并没有白费。
8 模型训练
这部分为在上位机运行的部分,所以需要将上一步采集来的数据拷贝到电脑中。我在这里是用scp来传文件的,个人感觉还是很便利的。
具体只要将数据拷贝过来之后在电脑上运行train.py脚本,完了就把训练出来的xml文件拷贝回小车上跑跑看LoadData.py,如果效果不好则要重新添加采集数据,重新训练,重新再试一遍。
直接使用OpenCV的机器学习模块非常方便,核心的训练部分只需要7行代码。这里就大概讲讲每句代码实现的功能。
在这七行代码中,第一句就需要创建一个神经网络:
# create MLP
model = cv2.ml.ANN_MLP_create()
创建完毕后需要对这个网络的结构以及一些参数进行设置:
# Create ANN layer
model.setLayerSizes(np.int32([38400,64,3])) #将网络结构设置为38400个输入层,64个隐层,3个输出层。
理论上隐层数量越多,训练时间就越长,结果就越好,还可以加入多层隐层。我分别使用16、32、64个隐层都训练过,64层的准确率基本是最高的,大约90%左右,就是需要一点时间,3500个数据大概十分钟左右。
接下来需要设置激活函数和训练停止条件,代码如下:
model.setActivationFunction(cv2.ml.ANN_MLP_SIGMOID_SYM)
model.setTermCriteria(( cv2.TERM_CRITERIA_COUNT | cv2.TERM_CRITERIA_EPS, 500, 0.001))
停止条件分为两个,分别是计算条件次数,和计算精度,0.001就相当于精度达到了0.1%。
接下来这三行理解为训练方法和学习速率,最后一条的作用是为了防止陷入局部最小值的函数,后两条默认为0.1。
# BP Method
model.setTrainMethod(cv2.ml.ANN_MLP_BACKPROP)
# speed of learning
model.setBackpropWeightScale(0.01)
# don't be part of lowest
model.setBackpropMomentumScale(0.1)
以上这7行代码为核心的负责训练程序的代码,这些设定完成过后,还需要一步来开始训练,代码如下:
num_iter = model.train(np.float32(train), cv2.ml.ROW_SAMPLE, np.float32(train_labels))
还需要数据读取、创建训练集和测试集、计算准确率和保存生成的模型。读取数据需要对采集来的数据加载到内存中。3500个数据大概有1g左右。代码如下:
# load training data
image_array = np.zeros((1, 38400))
label_array = np.zeros((1, 3), 'float')
training_data = glob.glob('./training_data/*.npz') #在本工程目录中找到training_data目录并读取里面的所有npz文件
# if no data, exit
if not training_data:
print("No training data in directory, exit")
sys.exit()
for single_npz in training_data:
with np.load(single_npz) as data:
train_temp = data['train']
train_labels_temp = data['train_labels']
image_array = np.vstack((image_array, train_temp))
label_array = np.vstack((label_array, train_labels_temp))
X = image_array[1:, :]
y = label_array[1:, :]
print('Image array shape: ', X.shape)
print('Label array shape: ', y.shape)
读取完成后需要对其进行一个分割,因为不光要有训练集,还需要有测试集来测试我们的模型准确率,这个也有现成的模块,分割数据集代码如下:
from sklearn.model_selection import train_test_split
# train test split, 8:2
train, test, train_labels, test_labels = train_test_split(X, y, test_size=0.2)
测试部分代码如下:
# train data
ret_0, resp_0 = model.predict(train)
prediction_0 = resp_0.argmax(-1)
true_labels_0 = train_labels.argmax(-1)
train_rate = np.mean(prediction_0 == true_labels_0)
print('Train accuracy: ', "{0:.2f}%".format(train_rate * 100))
# test data
ret_1, resp_1 = model.predict(test)
prediction_1 = resp_1.argmax(-1)
true_labels_1 = test_labels.argmax(-1)
test_rate = np.mean(prediction_1 == true_labels_1)
print('Test accuracy: ', "{0:.2f}%".format(test_rate * 100))
最终保存模型:
# save model
model.save('mlp_xml/mlp.xml')
下图为训练出结果的截图:
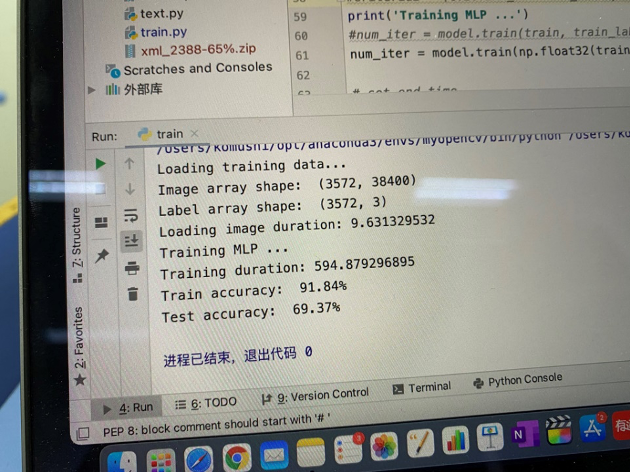
9 装载模型——自动驾驶
每次训练的累的快不行的时候,最能振奋人心的就是将训练好的结果装载上去的时刻!
说得简单点,与数据采集类似,装载模型只是将操作手交给计算机,由计算机根据图像来做出相应决策。
在LoadData.py脚本中,首先我们需要将keybDrive.py里面的电机接口和方向控制的方法贴过来。这段代码由于太长就先不贴了,请见我的github链接。
接下来读取模型,将之前训练好的xml文件加载到程序中:
class NeuralNetwork(object):
def __init__(self):
self.annmodel = cv2.ml.ANN_MLP_load('mlp_xml/mlp.xml')
def predict(self, samples):
ret, resp = self.annmodel.predict(samples)
return resp.argmax(-1) # find max
现在模型有了,如何控制方向的方法也有了,接下来该打开我们的摄像头,让“机器”看到前方的道路。同样,初始化神经网络和摄像头参数:
def __init__(self):
self.model = NeuralNetwork()
print('load ANN model.')
#self.obj_detection = ObjectDetection()
self.car = Carctrl()
print('----------------Caminit completed-----------------')
self.handle()
def handle(self):
self.cap = cv2.VideoCapture(1)
self.cap.set(3, 320)
self.cap.set(4, 240)
获取图像并处理:
#获取图像并处理:
try:
while True:
ret, cam = self.cap.read()
gray = cv2.cvtColor(cam, cv2.COLOR_RGB2GRAY)
ret, th3 = cv2.threshold(gray, 0, 255, cv2.THRESH_BINARY + cv2.THRESH_OTSU)
roi = th3[120:240, :]
设置一个模型变量,供控制程序调用。这一步可以加入一句cv2.imshow('cam',cam) 或者cv2.imshow('cam',roi)就可以观察小车实际获取图像的情况,调试的时候也能知道是什么情况导致的小车发出错误指令。
image_array = roi.reshape(1, 38400).astype(np.float32)
prediction = self.model.predict(image_array)
# cv2.imshow('roi',roi)
cv2.imshow('cam', cam)
设计一个程序终止方法:
if cv2.waitKey(1) & 0xFF == ord('l'):
break
else:
self.car.self_driving(prediction)
最终,模仿手动操作的方法,将方向的控制权交给计算机:
def self_driving(self, prediction):
if prediction == 0:
self.t_up(10, 10)
print("Forward")
elif prediction == 1:
self.t_up(5, 10)
print("Left")
elif prediction == 2:
self.t_up(10, 5)
print("Right")
else:
self.t_stop(0)
经多多次反复训练/实验后,自动驾驶运行测试成功!连续跑了四圈!好耶!
10 copyright&源代码
本文已经过知乎原作者“丶冬沐”授权改写,仅用于学习交流。
下方github链接是本人亲自实践用的代码,和原作者的有所不同。
原文传送门
代码(Edited by tomatoz)-github
















 1224
1224











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











