








前言
上篇文章讲解了resnet网络,今天给大家讲解的是MobileNetV1版本,传统 CNN 结构(如 VGG 和 ResNet)计算量大,难以在移动设备上高效运行。为此,Google 在 2017 年提出 MobileNetV1,采用 深度可分离卷积(Depthwise Separable Convolution),大幅降低计算量和参数规模,同时保持较高准确率。
与 VGG 相比,MobileNetV1 计算量仅为其 1/10,但能在轻量级设备上保持良好性能。与 ResNet 相比,MobileNetV1 通过高效卷积减少计算开销,使其在相似准确率下更适用于移动端应用。总的来说就是在提出了深度可分离卷积,使得conv网络的计算量大大减少,可以部署在IOT设备上,论文本身并没有强调SOTA(State-of-the-Art ),主要是创新点还是在SOTA可以和vgg,resnet网络匹及的同时,还可以使网络部署在移动端的设备上
领取100G深度学习资料,500多篇经典论文,论文辅导等请关注作者公众号: 智算学术 回复:资料 领取
论文链接:[1704.04861] MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
视频讲解:待更新
代码讲解:待更新
往期回顾
LeNet 论文精读 | 深度解析+PyTorch代码复现(上)_yann lecun卷积网络的奠定文章-CSDN博客
LeNet 论文精读 | 深度解析+PyTorch代码复现(下)_lenet搭建与mnist训练-CSDN博客
AlexNet 论文精读 | 深度解析+PyTorch代码复现 (上)-CSDN博客
AlexNet 论文精读 | 深度解析+PyTorch代码复现 (下)-CSDN博客
VGG论文精读 | 深度解析+PyTorch代码复现_dense convnet evaluation-CSDN博客
GoogleNet论文精读 | 深度解析+PyTorch代码复现-CSDN博客
ResNet论文精读:翻译+学习笔记+Pytorch代码复现-CSDN博客
三、MobileNet Architecture— MobileNet结构
3.1 Depthwise Separable Convolution—深度可分离卷积
3.2 Network Structure and Training— 网络结构和训练
3.3 Width Multiplier: Thinner Models—宽度超参数α
3.4 Resolution Multiplier: Reduced Representation—分辨率超参数ρ
4.2 Model Shrinking Hyperparameters—模型收缩参数
4.3 Fine Grained Recognition—细粒度图像分类
4.4 Large Scale Geolocalizaton—以图搜地
Abstract—摘要
翻译
我们提出了一类高效的模型,称为 MobileNets,适用于移动和嵌入式视觉应用。MobileNets 基于一个简化的架构,采用深度可分离卷积来构建轻量级的深度神经网络。我们引入了两个简单的全局超参数,它们可以高效地在延迟和准确度之间进行权衡。这些超参数使得模型构建者能够根据问题的约束选择合适大小的模型。我们在资源和准确性权衡方面进行了广泛的实验,并在 ImageNet 分类上与其他流行模型相比展示了强大的性能。随后,我们展示了 MobileNets 在多种应用场景中的有效性,包括目标检测、细粒度分类、人脸属性和大规模地理定位。
精读
-
MobileNets介绍:是一种轻量级模型,专为移动和嵌入式视觉应用设计。
-
架构特点:采用深度可分离卷积,降低计算复杂度,构建高效的神经网络。
-
超参数调节:引入两个全局超参数,可以调节这两个超参数来调节结果的准确性和运行时长。
-
实验与对比:MobileNets在ImageNet分类等任务上与其他模型相比表现强劲。
-
广泛应用:适用于目标检测、细粒度分类、人脸属性识别和地理定位等多个应用场景。
一、Introduction-介绍
翻译
卷积神经网络(CNN)自从 AlexNet [19] 通过赢得 ImageNet 挑战赛 ILSVRC 2012 [24] 而使深度卷积神经网络广泛流行以来,已经在计算机视觉领域变得无处不在。一般的趋势是使网络变得更深、更复杂,以实现更高的准确率 [27, 31, 29, 8]。然而,这些提高准确率的进展不一定使得网络在大小和速度上变得更高效。在许多实际应用中,如机器人技术、自动驾驶汽车和增强现实,识别任务需要在计算资源有限的平台上及时执行。本文描述了一种高效的网络架构和一组超参数,用于构建非常小的、低延迟的模型,这些模型可以轻松地与移动和嵌入式视觉应用的设计需求相匹配。第二部分回顾了构建小型模型的相关工作。第三部分介绍了 MobileNet 架构以及两个超参数:宽度乘子(width multiplier)和分辨率乘子(resolution multiplier),用来定义更小、更高效的 MobileNets。第四部分描述了在 ImageNet 上的实验以及各种不同的应用和使用场景。第五部分总结并得出结论。
精读
-
背景:CNN自AlexNet以来广泛应用于计算机视觉,但增加网络深度并不一定提高效率,特别是在资源受限的平台上。
-
应用挑战:实际应用如机器人、自动驾驶等需要在计算有限的设备上实时处理任务,既要有高准确度,又要有低延迟。
-
解决方案:本文提出一种高效的网络架构,并通过两个超参数(宽度乘子和分辨率乘子)来优化模型大小和速度,适应移动和嵌入式应用。
-
结构概览:
-
第二部分回顾了小型模型的研究。
-
第三部分介绍了MobileNet架构和超参数。
-
第四部分展示了ImageNet实验和不同应用的结果。
-
第五部分总结结论。
-
关键点:MobileNet旨在通过灵活调节两个超参数在效率和准确度之间找到最佳平衡,适用于资源受限的设备。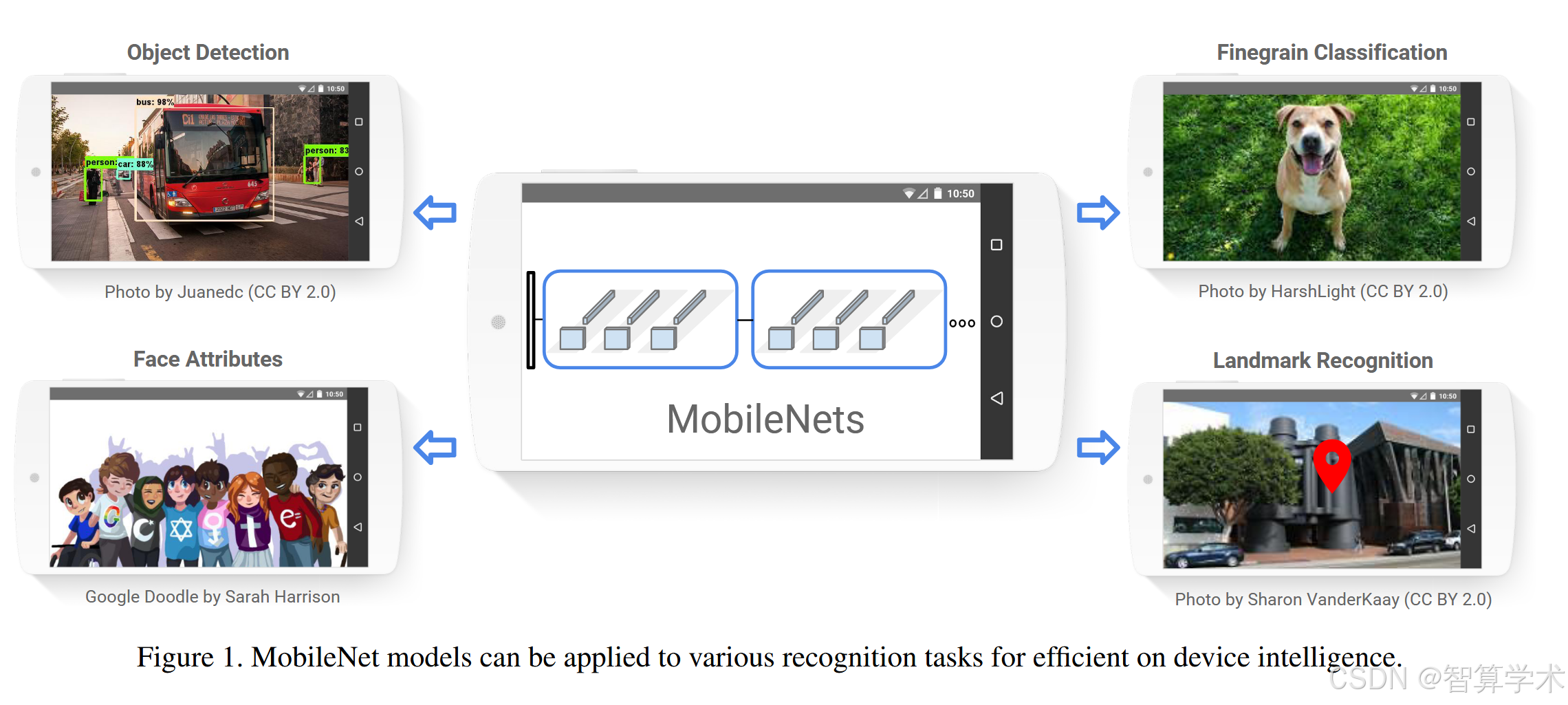
二、Prior Work—先前的工作
翻译
近年来,构建小型高效神经网络的兴趣日益增加,例如 [16, 34, 12, 36, 22]。这些不同的方法通常可以分为两类:一类是压缩预训练网络,另一类是直接训练小型网络。本文提出了一类网络架构,允许模型开发者根据应用的资源限制(延迟、大小)选择匹配的小型网络。MobileNets 主要专注于优化延迟,同时也能生成小型网络。许多小型网络的论文仅关注网络大小,而忽略了速度。MobileNets 主要由深度可分离卷积构建,这一方法最初在 [26] 中提出,随后在 Inception 模型 [13] 中用于减少前几层的计算量。Flattened networks [16] 使用完全因式分解的卷积构建网络,展示了极其因式分解网络的潜力。独立于本文,Factorized Networks [34] 引入了类似的因式分解卷积以及拓扑连接的使用。随后,Xception 网络 [3] 展示了如何扩展深度可分离滤波器,从而超越 Inception V3 网络。另一种小型网络是 Squeezenet [12],它使用瓶颈方法设计了一个非常小的网络。其他减少计算量的网络包括结构变换网络 [28] 和深度炸裂卷积网络 [37]。获取小型网络的另一种方法是通过压缩、因式分解或压缩预训练网络。文献中提出了基于产品量化 [36]、哈希 [2]、剪枝、向量量化和哈夫曼编码 [5] 的压缩方法。此外,提出了多种因式分解方法来加速预训练网络 [14, 20]。训练小型网络的另一种方法是蒸馏 [9],它使用较大的网络来教导较小的网络。这与我们的方法是互补的,并在第四部分的某些使用案例中有所涵盖。另一种新兴的方法是低位网络 [4, 22, 11]。
精读
构建小型网络的方法:
1、压缩预训练网络(指的是在已经训练好的大规模神经网络(预训练网络)基础上,使用各种技术将其体积或计算量减小,从而使其更加高效,适应计算资源有限的设备)
量化:将权重从浮点数转换为低精度(例如8位整数),减少存储和计算量。
剪枝:删除网络中不重要的参数(通常是权重值接近零的连接),减少计算复杂度。
因式分解:使用矩阵因式分解等技术,将大规模的计算操作分解为小规模的操作,从而加速计算过程。
哈希(Hashing):将高维数据映射到低维空间,减少存储和计算负担。
矢量编码:将网络中的权重值进行分类,每类对应一个代表值,减少存储空间。
霍夫曼编码:对权重进行编码,减少存储需求。
2、直接训练小型网络
3、蒸馏
蒸馏(Distillation) 是一种训练小型网络的方法。其核心思想是使用一个大型的、性能更强的网络(通常是预训练网络)来指导一个较小的网络(学生网络)的训练。
教师-学生架构: 在蒸馏过程中,大型网络作为“教师”模型,提供标签或者软标签(soft labels),即输出概率分布,而不是传统的硬标签。小型网络(学生网络)通过学习这些软标签,获得更加丰富的知识。
三、MobileNet Architecture— MobileNet结构
3.1 Depthwise Separable Convolution—深度可分离卷积
翻译
在本节中,我们首先描述了MobileNet所依赖的核心层,即深度可分离卷积(depthwise separable filters)。接着,我们介绍了MobileNet网络结构,并最终描述了两个模型压缩超参数:宽度乘子(width multiplier)和分辨率乘子(resolution multiplier)。MobileNet模型基于深度可分离卷积,这是一种因式分解卷积,将标准卷积分解为深度卷积和1 × 1卷积(称为点卷积)。在MobileNets中,深度卷积对每个输入通道应用一个单独的滤波器。然后,点卷积应用1 × 1卷积来结合深度卷积的输出。标准卷积在一步操作中既进行滤波又结合输入,深度可分离卷积将这一过程分为两个层次,一个用于滤波,另一个用于结合。这种因式分解大大减少了计算量和模型大小。图2展示了标准卷积2(a)如何被分解为深度卷积2(b)和1 × 1点卷积2(c)。标准卷积层的输入是一个DF × DF × M的特征图F,输出是一个DF × DF × N的特征图G,其中DF是输入特征图的空间宽度和高度,M是输入通道数(输入深度),DG是输出特征图的空间宽度和高度,N是输出通道数(输出深度)。标准卷积层的参数化由大小为DK × DK × M × N的卷积核K来定义,其中DK是卷积核的空间维度,假设为正方形,M是输入通道数,N是输出通道数,如前所述。在假设步长为1且有填充的情况下,标准卷积层的输出特征图计算公式为: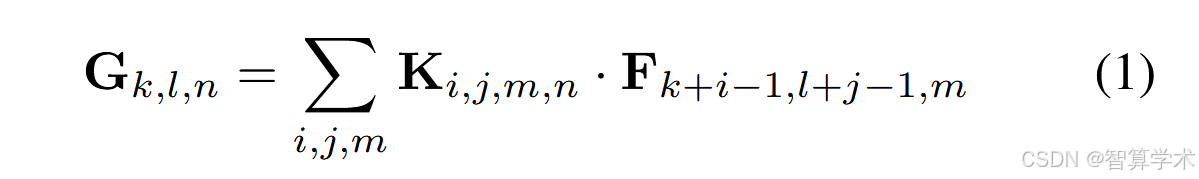
标准卷积的计算成本为: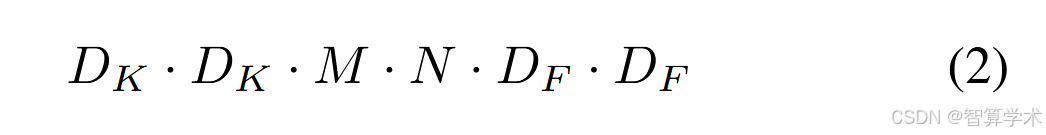
标准卷积的计算成本依赖于输入通道数M、输出通道数N、卷积核大小Dk × Dk和特征图大小DF × DF。MobileNet模型处理了这些术语及其相互作用。首先,MobileNet使用深度可分离卷积来打破输出通道数与卷积核大小之间的相互作用。标准卷积操作通过卷积核对特征进行滤波,并结合特征生成新的表示。通过使用因式分解卷积,称为深度可分离卷积,可以将滤波和结合步骤分为两步,从而显著减少计算成本。深度可分离卷积由两个层次组成:深度卷积和点卷积。我们使用深度卷积为每个输入通道(输入深度)应用一个单独的滤波器。然后,使用一个简单的1×1卷积(点卷积)来创建深度卷积输出的线性组合。MobileNets在这两层中都使用了批归一化(batchnorm)和ReLU非线性激活函数。每个输入通道(输入深度)使用一个滤波器的深度卷积可以表示为: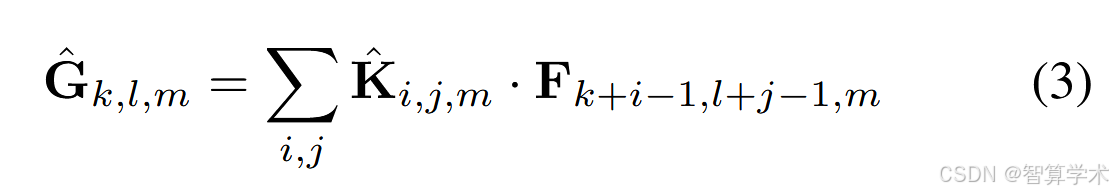
其中,ˆK是大小为DK × DK × M的深度卷积核,其中Kˆ中的第m个滤波器应用于F中的第m个通道,生成滤波后的输出特征图ˆG中的第m个通道。深度卷积的计算成本为: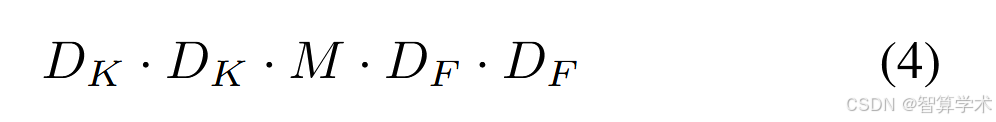
深度卷积相对于标准卷积来说非常高效。然而,它仅对输入通道进行滤波,并不会将它们组合成新的特征。因此,需要额外的一层,通过1 × 1卷积计算深度卷积输出的线性组合,以生成这些新特征。深度卷积和1 × 1(点卷积)卷积的组合被称为深度可分离卷积,这最早在[26]中提出。深度可分离卷积的计算成本为: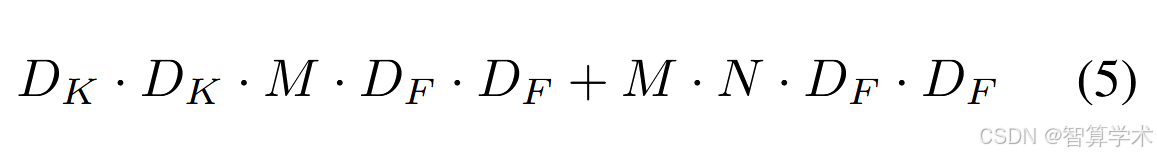
这是深度卷积和1 × 1点卷积的计算成本之和。通过将卷积表达为滤波和组合的两步过程,我们可以实现计算量的减少: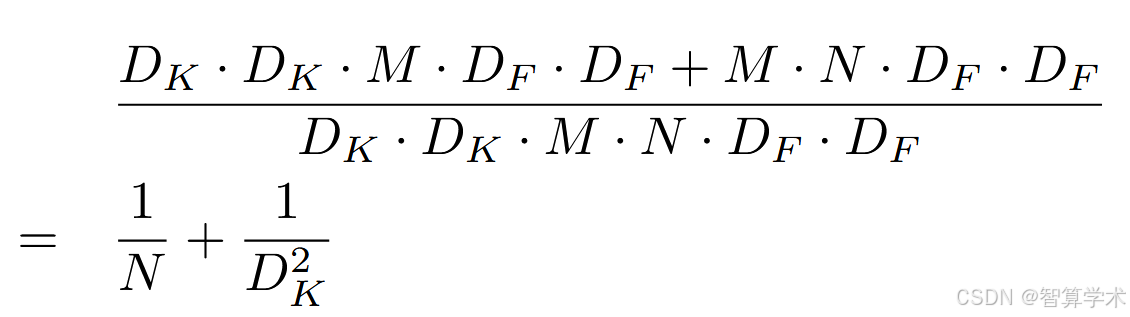
MobileNet使用3 × 3深度可分离卷积,相比于标准卷积,其计算量减少了8到9倍,且准确率仅有少量下降,如第4节所示。像[16, 31]中那样在空间维度上进行额外的因式分解,并不会节省太多额外的计算,因为在深度卷积中消耗的计算量非常少。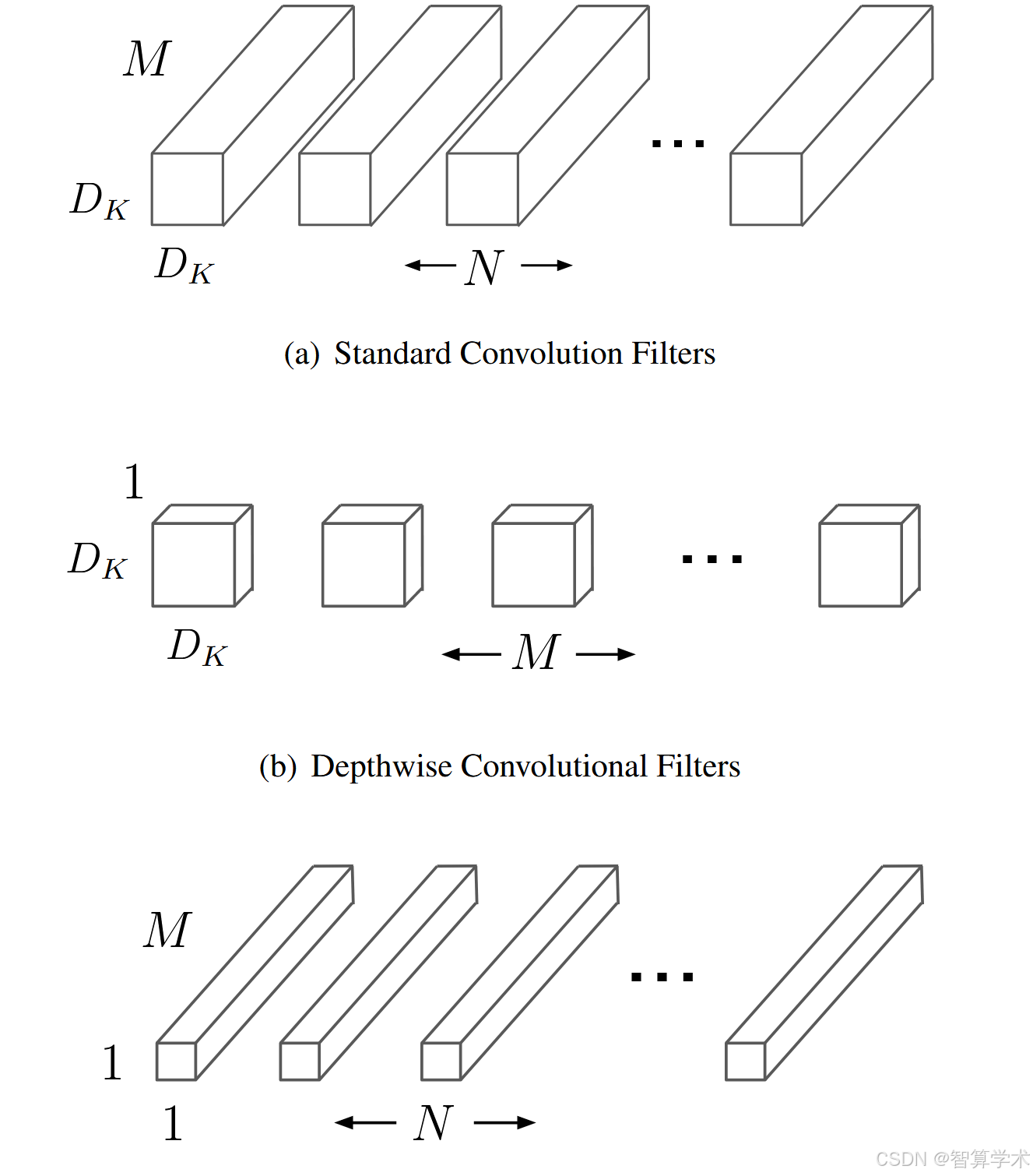
(c) 1×1 卷积滤波器,在深度可分离卷积的背景下称为点卷积
图2. 标准卷积滤波器(a)被两层替代:深度卷积(b)和点卷积(c),以构建深度可分离滤波器。
精读
这一部分是让人读起来头大的一部分,又涉及计算,又涉及网络结构,其实这一部分的主要目的就是要计算出,深度可分离卷积网络的计算量比标准卷积的参数量大致少了9倍。
我们来一步一步的抽丝剥茧的来看看到底是怎么计算的!
标准卷积图: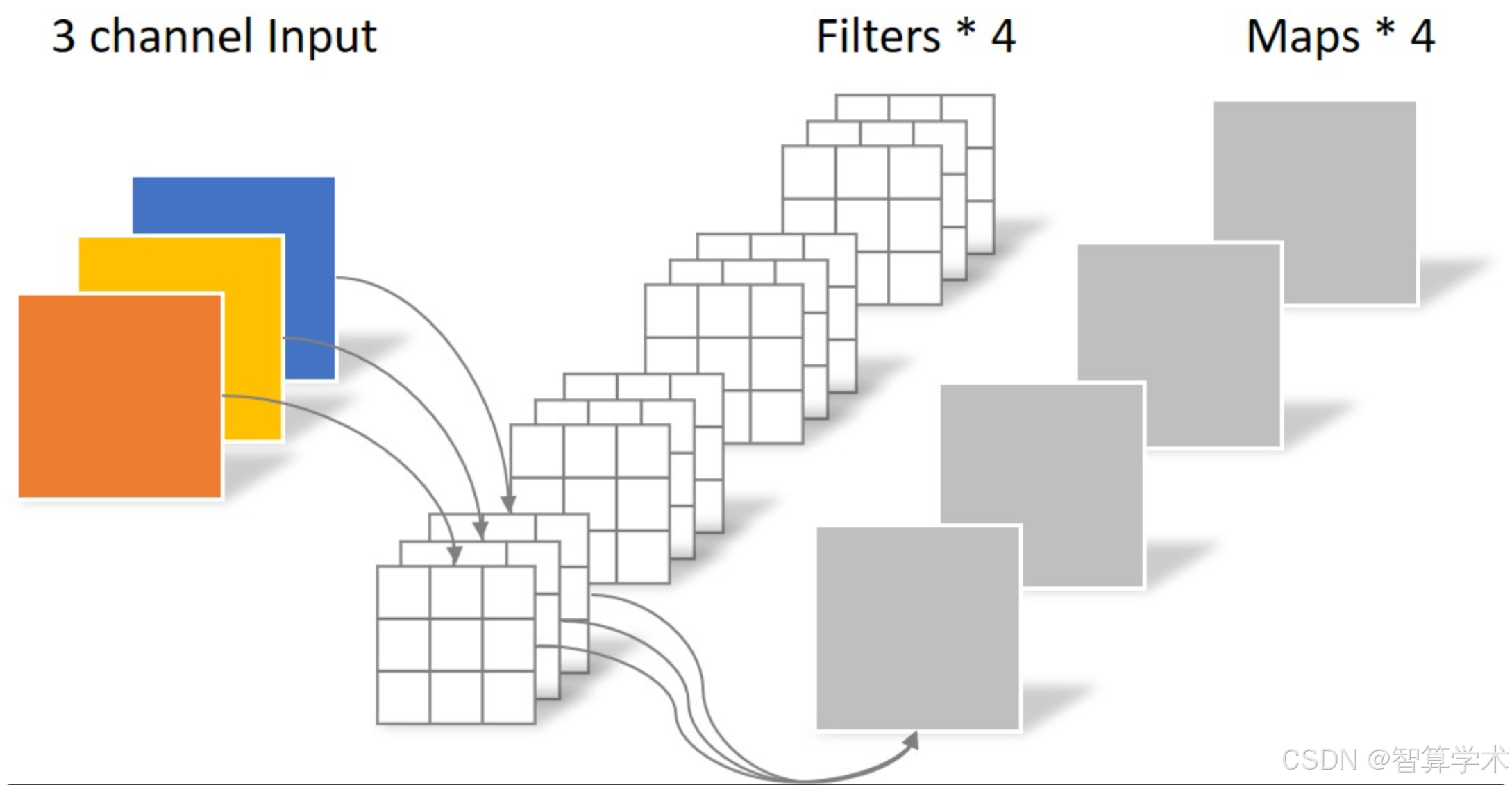
注意:这里对比的不是参数量,而是计算量
输入是DF × DF × M的特征图,输出是一个DF × DF × N的特征图,卷积核大小为DK × DK × M × N (M为通道数,N为个数)
计算量: Df×Df×Dk×Dk×M×N
参数量: Dk ×Dk ×M×N
深度可分离卷积: 说白了就是 我用了M个通道数为1的卷积核,然后每个卷积核分别和对应的输入特征矩阵的通道进行卷积
(也就说 输入特征矩阵的通道第H层就会和通道数为1的卷积核的第H个进行卷积)
输入是DF × DF × M的特征图,卷积核大小为DK × DK × M × N (M为通道数,N为个数),输出是一个DF × DF × M的特征图
计算量:Dk×Dk×M×Df×Df
参数量:Dk ×Dk ×M
其中卷积核尺寸是DK × DK,Df为特征图尺寸,M为输入通道数,N为输出通道数。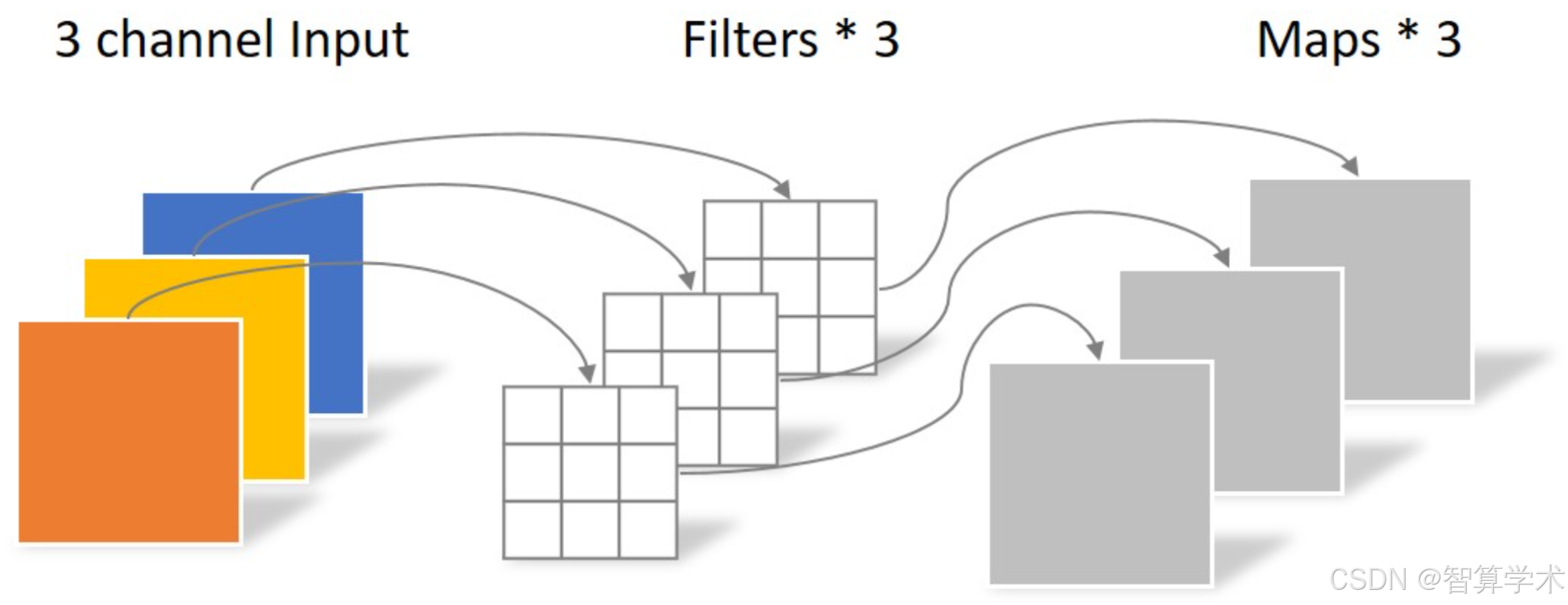
逐点卷积:
深度可分离卷积完事后,在经历一个逐点卷积(如下图),这个时候输入的特征矩阵为DF × DF × M,对的这时候发现,输入特征矩阵在经历了深度可分离卷积后,它的尺寸和通道数都没有变
计算量: DK × DKx M x N x Df x Df
参数量:DK × DK x M x N
其中卷积核尺寸是DK × DK,Df为特征图尺寸,M为输入通道数,N为输出通道数。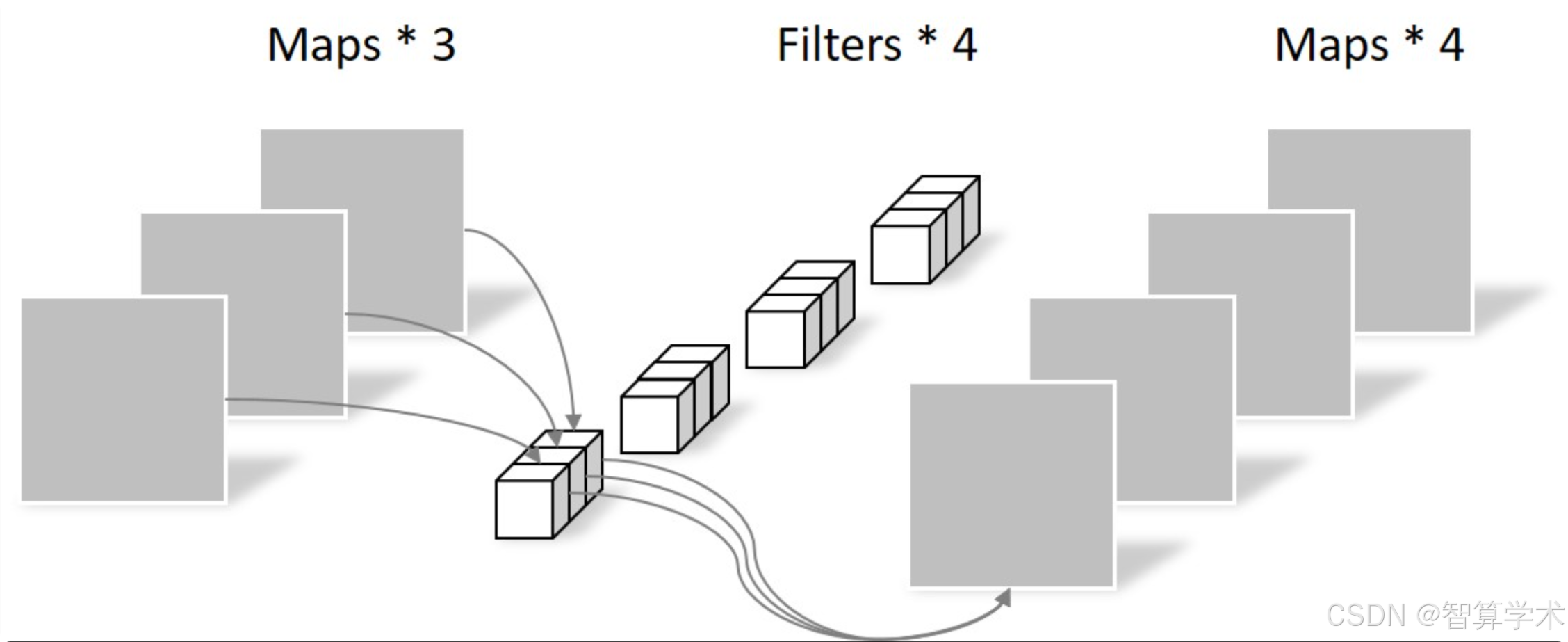
从上面就可以得出:
在经历了 深度可分离卷积和逐点卷积后计算量为: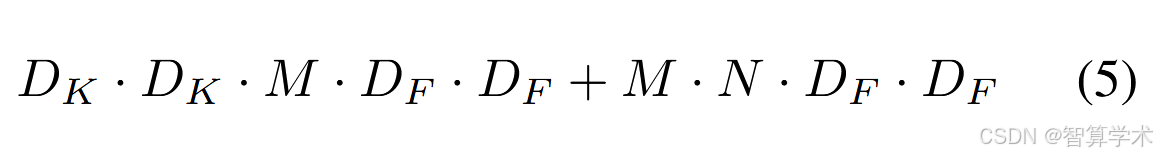
那么它们和标准卷积相比看下计算量相差的比例: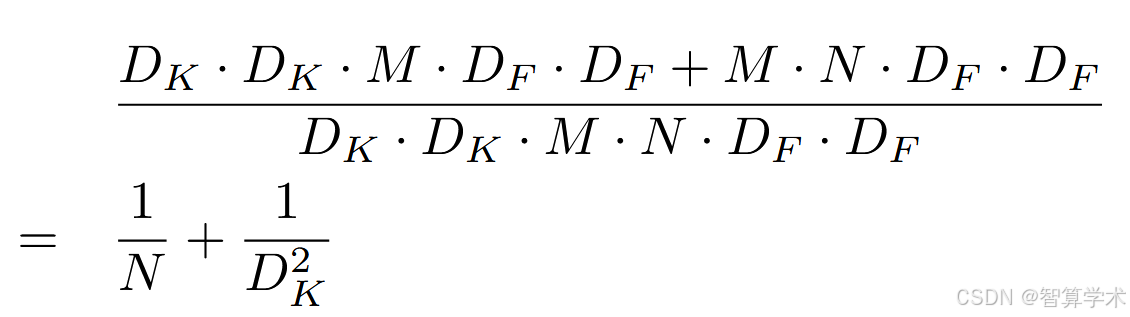
深度可分离卷积:标准卷积有N个卷积核,但是在深度可分离卷积中,只用了一个卷积核,那么计算量来说就是1/N
逐点卷积:就是用的1x1的卷积核而已,那么和标准卷积的计算量来说就差了1/Dk^2
3.2 Network Structure and Training— 网络结构和训练
翻译
MobileNet 结构建立在深度可分离卷积之上,唯一的例外是第一层,它是一个完整的卷积。通过以这种简单的方式定义网络,我们可以轻松地探索不同的网络拓扑结构,以找到一个良好的网络架构。MobileNet 的架构在表 1 中进行了定义。所有层(除了最终的全连接层)后面都跟着批量归一化(batchnorm)[13] 和 ReLU 非线性激活。最终的全连接层没有非线性激活,而是直接输入到 Softmax 层进行分类。
图 3 对比了常规卷积层(包括批量归一化和 ReLU 非线性激活)与因式分解后的层(包含深度卷积、1×1 逐点卷积,每个卷积层后都带有批量归一化和 ReLU 激活)。在 MobileNet 结构中,下采样(downsampling)是通过深度卷积中的步幅卷积(strided convolution)以及第一层的标准卷积来完成的。最终的全局平均池化(average pooling)将空间分辨率降低到 1×1,然后再连接到全连接层。
如果将深度卷积和逐点卷积分开计算层数,MobileNet 一共有 28 层。然而,仅仅用较少的计算量(Mult-Adds)来定义网络是不够的,确保这些操作可以高效执行同样至关重要。例如,非结构化的稀疏矩阵运算通常不会比稠密矩阵运算更快,除非稀疏度极高。MobileNet 结构的计算几乎全部集中在稠密的 1×1 卷积中,这些计算可以通过高度优化的通用矩阵乘法(GEMM)函数实现。
通常,卷积操作可以通过 GEMM 实现,但需要先进行一次内存重新排序(称为 im2col),以便将其映射到 GEMM。比如,在流行的 Caffe 框架 [15] 中就采用了这种方法。而 1×1 卷积不需要这种内存重排,能够直接用 GEMM 实现,这是数值线性代数中最优化的算法之一。MobileNet 的计算时间有 95% 都花在 1×1 卷积上,同时 1×1 卷积占据了 75% 的模型参数(如表 2 所示)。几乎所有额外的参数都集中在最终的全连接层中。
MobileNet 模型是在 TensorFlow [1] 框架中使用 RMSprop [33] 进行训练的,采用类似 Inception V3 [31] 的异步梯度下降方法。然而,与大模型训练方式不同的是,由于小模型不太容易过拟合,我们使用了较少的正则化和数据增强技术。在 MobileNet 训练过程中,我们没有使用辅助分类器(side heads)或标签平滑(label smoothing),并且减少了图像变换的影响,限制了用于 Inception 大模型训练的裁剪区域大小 [31]。此外,我们发现,在深度卷积层上应用极少或不应用权重衰减(L2 正则化)非常重要,因为这些层的参数非常少。在下一节的 ImageNet 基准测试中,所有模型的训练参数都是相同的,而不论模型大小如何。
精读
-
深度可分离卷积模块

每个卷积层后都带有批量归一化和 ReLU 激活,最终的全连接层没有非线性激活,而是直接输入到 Softmax 层进行分类。
-
架构表
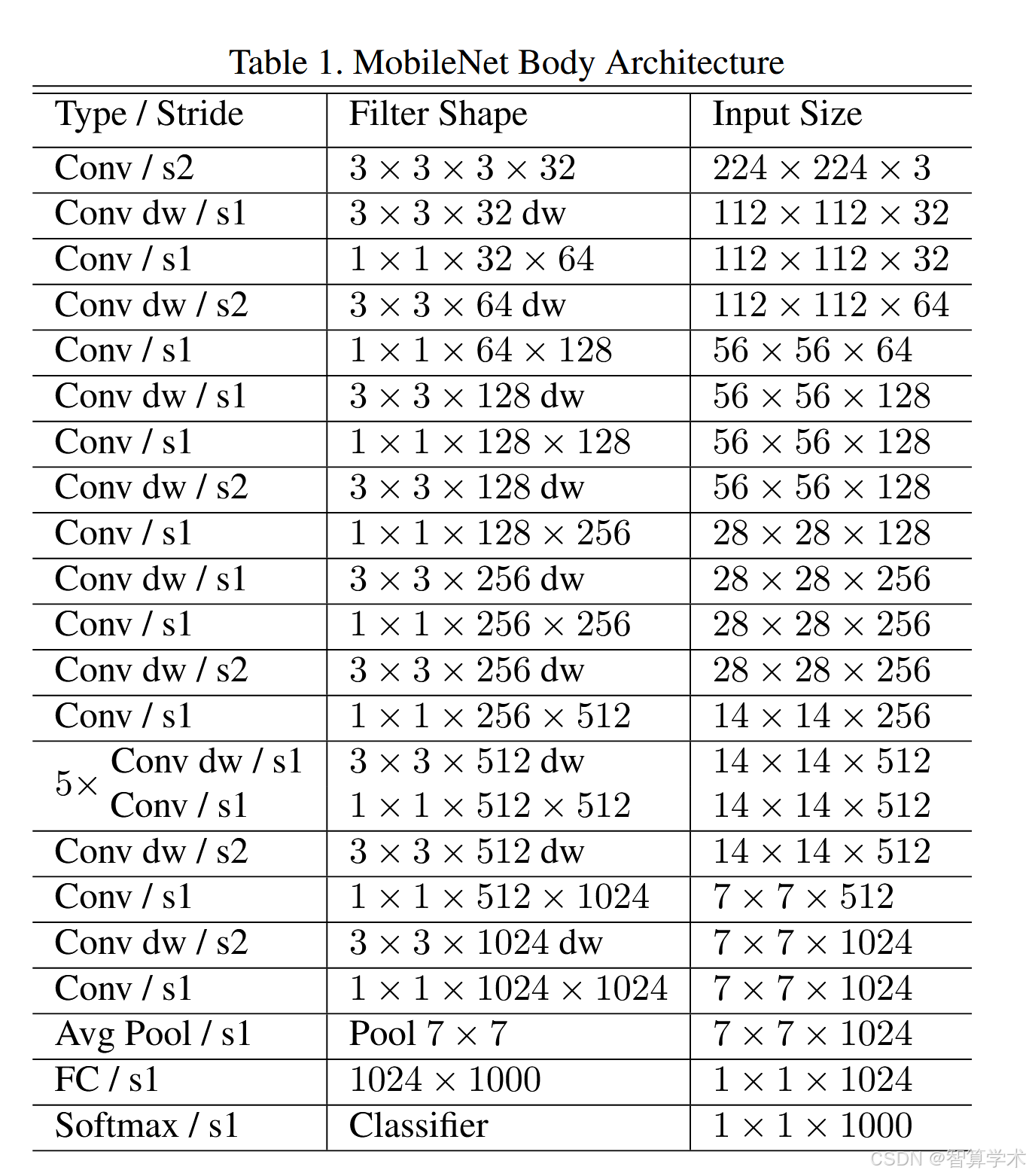
一共有28层(除了自适应下采样和全连接层),第一层为标准卷积,中间就是我们的深度可分离卷积模块,最后是平均池化层,全连接层和softmax层输出。除全连接层不使用激活函数,而使用softmax进行分类之外,其他所有层都使用BN和ReLU。
图片没有使用数据增强和正则化的技术(移动小设备用不到),MobileNet 的计算时间有 95% 都花在 1×1 卷积上,同时 1×1 卷积占据了 75% 的模型参数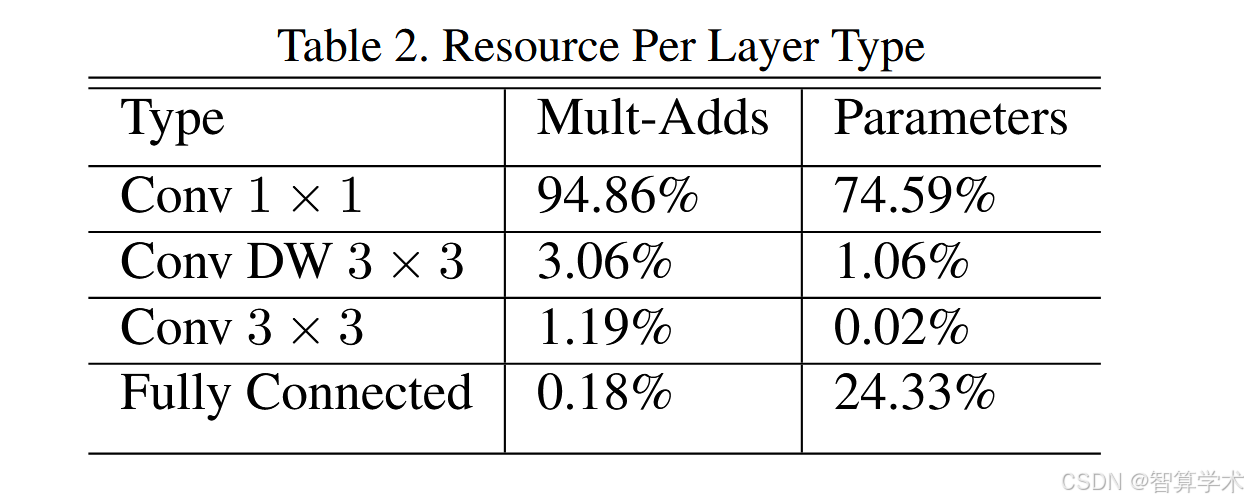
每层参数的占比,对应的计算时间的占比,如上表,在训练的时候使用了1x1卷积可以直接通过GEMM (general matrix multiply)进行加速计算,后面我们要讲的transform也是用的这个来加速计算
3.3 Width Multiplier: Thinner Models—宽度超参数α
翻译
尽管基础的 MobileNet 架构已经足够小且具有低延迟,但在许多特定的使用场景或应用中,可能需要使模型更加紧凑且计算速度更快。为了构建这些更小、更高效的模型,我们引入了一个非常简单的参数 α,称为宽度因子(width multiplier)。
宽度因子的作用是在每一层对网络进行均匀缩减。对于某一层,当宽度因子为 α 时,输入通道数 M 变为 αM,输出通道数 N 变为 αN。使用宽度因子 α 后,深度可分离卷积的计算成本为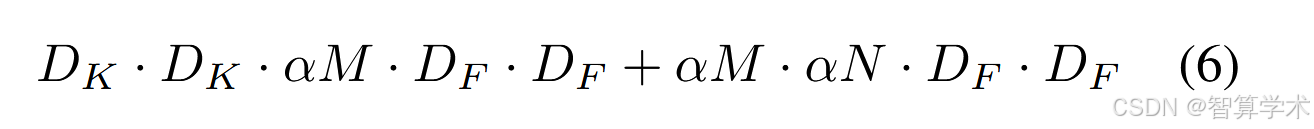
其中 α ∈ (0, 1],常见的取值为 1、0.75、0.5 和 0.25。α = 1 时对应的是标准的 MobileNet,而 α < 1 则表示缩小版本的 MobileNet。
宽度因子 α 的作用是使计算成本和参数数量近似按照 α² 的比例减少。
宽度因子可以应用于任何模型结构,以定义一个更小的模型,同时在准确率、延迟和模型大小之间进行合理的权衡。然而,使用宽度因子缩减后的模型需要从头开始训练。
精读
为了构建这些更小、更高效的模型,我们引入了一个非常简单的参数 α,称为宽度因子
宽度因子的作用是在每一层对网络进行均匀缩减,输入通道数 M 变为 αM,输出通道数 N 变为 αN。使计算成本和参数数量近似按照 α² 的比例减少
当α=1的时候是一个标准版的MobileNet,α<1的时候就是mini版的MobileNet
3.4 Resolution Multiplier: Reduced Representation—分辨率超参数ρ
翻译
第二个超参数是分辨率因子 ρ,用于减少神经网络的计算成本。我们将其应用于输入图像,并且每一层的内部表示都会按相同的因子进行缩减。在实际操作中,我们通过设置输入分辨率来隐式地设定 ρ。
现在,我们可以将网络核心层的计算成本表示为具有宽度因子 α 和分辨率因子 ρ 的深度可分离卷积: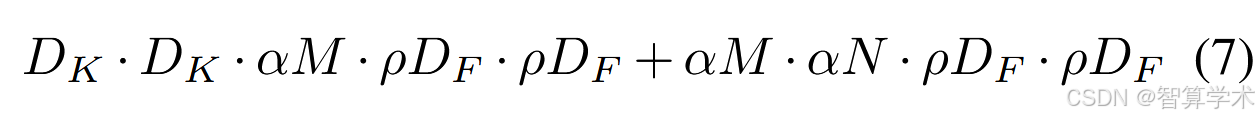
其中 ρ ∈ (0, 1],通常通过设置网络的输入分辨率来隐式设定,分辨率可以是 224、192、160 或 128。ρ = 1 是基准 MobileNet,ρ < 1 则是减少计算量的 MobileNet。分辨率因子具有通过 ρ² 减少计算成本的效果。
例如,我们可以看一下 MobileNet 中的典型层,观察深度可分离卷积、宽度因子和分辨率因子是如何减少计算成本和参数的。表 3 显示了当架构缩减方法依次应用到该层时,该层的计算量和参数数量。第一行显示了具有 14 × 14 × 512 尺寸输入特征图的完整卷积层的 Mult-Adds 和参数,其中卷积核 K 的尺寸为 3 × 3 × 512 × 512。我们将在下一节详细探讨资源与准确度之间的权衡。
精读
通过控制输入图像分辨率的大小来控制总计算量,输入图像的尺寸变小,那么输入特征矩阵就会变小,计算量自然就会下降
ρ = 1 是基准 MobileNet,ρ < 1 则是减少计算量的 MobileNet,分辨率因子具有通过 ρ² 减少计算成本
下表给出 标准卷积、深度可分离卷积、α、ρ的计算量和参数量的对比,输入的feature map 为14x14x512,卷积核大小为3x3x512x512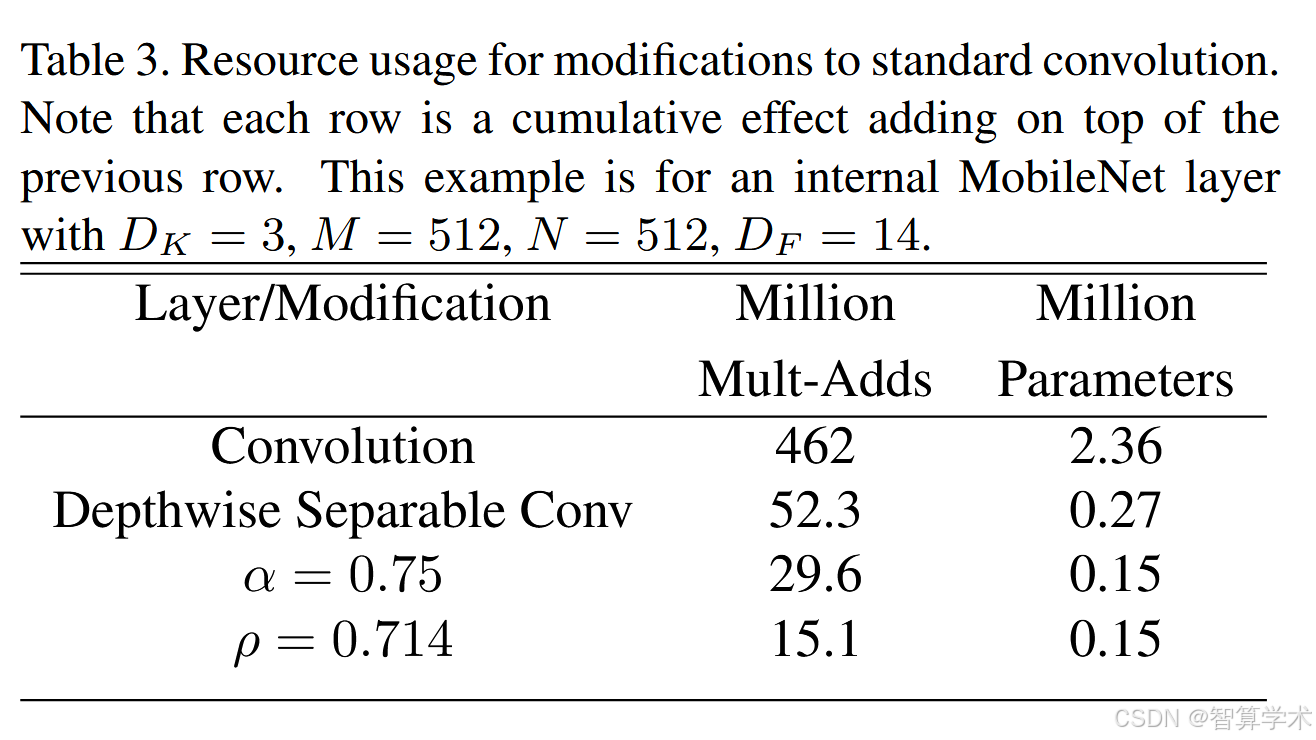
以上总结,α、ρ分别控制输入特征矩阵的通道数和尺寸来控制总计算量
四、Experiments—实验
4.1 Model Choices—模型的选择
翻译
在本节中,我们首先探讨深度卷积的影响以及通过减少网络宽度而不是减少层数来缩小网络的选择。接着,我们展示了基于两个超参数(宽度乘子和分辨率乘子)缩小网络的权衡,并将结果与一些流行的模型进行比较。最后,我们研究了 MobileNets 在不同应用中的表现。
首先,我们展示了使用深度可分卷积的 MobileNet 与使用全卷积构建的模型的结果。在表 4 中,我们看到与全卷积相比,使用深度可分卷积仅在 ImageNet 上将准确率降低了 1%,但在计算量和参数量上节省了大量资源。接下来,我们展示了使用宽度乘子比较更瘦的模型与使用较少层数的更浅模型的结果。为了使 MobileNet 更浅,表 1 中的 5 层特征大小为 14 × 14 × 512 的可分滤波器被移除。表 5 显示,在相似的计算量和参数数量下,使 MobileNet 更瘦比使其更浅要好 3%。
精读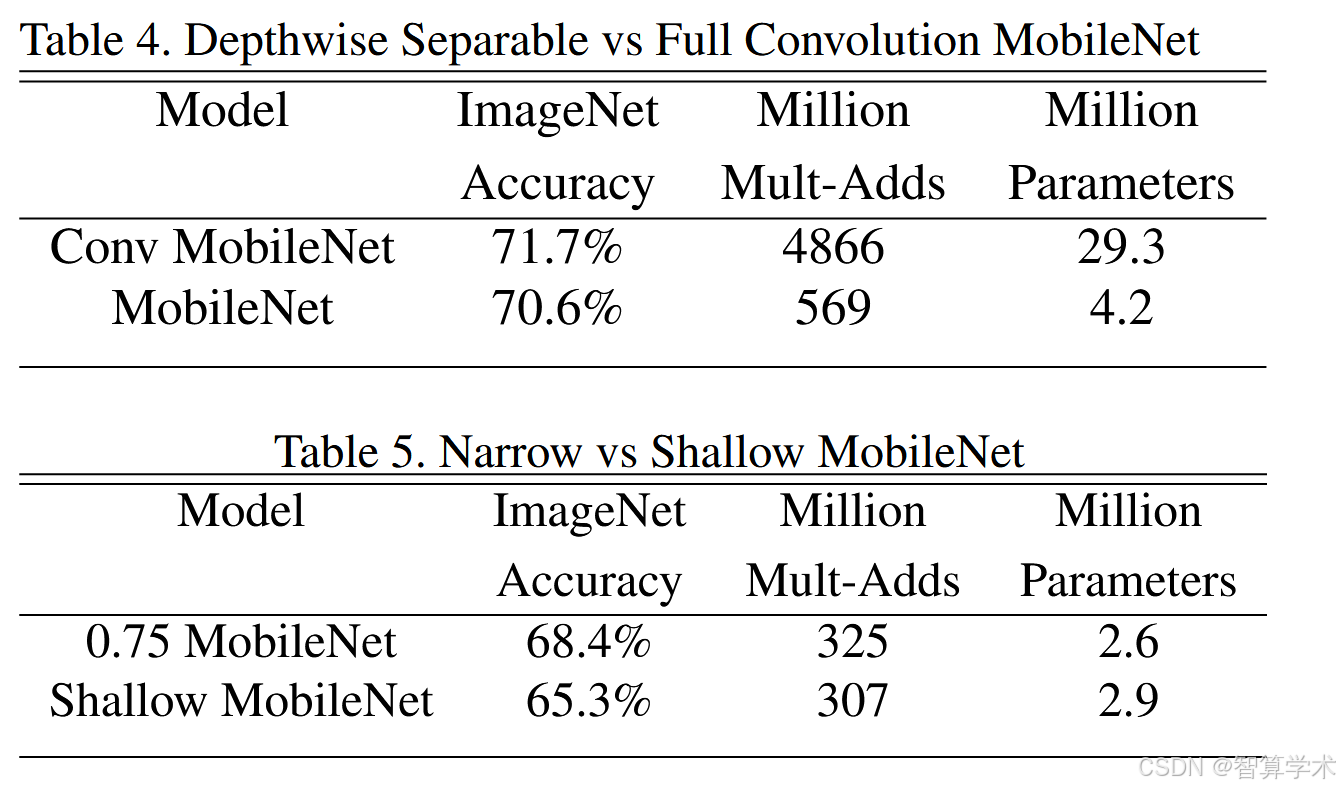
表4表明:对比标准卷积和DW卷积的实验,可以看到dw深度可分卷积仅在 ImageNet 上将准确率降低了 1%,但在计算量和参数量上节省了指数级的资源
表5表明:对比网络层数更少(层数减少)和网络更瘦(通道数减小,α=0.75)哪个效果好,结果表明MobileNet 更瘦比其层数更少要好 3%。
4.2 Model Shrinking Hyperparameters—模型收缩参数
翻译
首先,我们展示了使用深度可分离卷积的MobileNet与使用全卷积的模型的对比结果。在表4中,我们看到与全卷积相比,使用深度可分离卷积在ImageNet上仅减少了1%的准确性,但在多次加法运算和参数上节省了大量计算。接下来,我们展示了使用宽度乘数来缩小模型与使用较少层的较浅模型的对比结果。为了使MobileNet更浅,表1中具有14 × 14 × 512特征大小的5层可分离滤波器被移除。表5显示,在计算量和参数数量相似的情况下,使MobileNet更薄比使其更浅要好3%。
表6展示了通过宽度乘数α缩小MobileNet架构的准确性、计算量和大小之间的权衡。准确性平稳下降,直到架构变得过小时(α = 0.25)。表7展示了通过减少输入分辨率训练MobileNet时,不同分辨率乘数的准确性、计算量和大小的权衡。准确性在不同分辨率之间平稳下降。图4展示了通过宽度乘数α ∈ {1, 0.75, 0.5, 0.25}和分辨率{224, 192, 160, 128}的交叉组合产生的16个模型在ImageNet上的准确性与计算量之间的权衡。结果呈对数线性,当模型变得非常小(α = 0.25)时出现跳跃。图5展示了通过宽度乘数α ∈ {1, 0.75, 0.5, 0.25}和分辨率{224, 192, 160, 128}的交叉组合产生的16个模型在ImageNet上的准确性与参数数量之间的权衡。
表8将全MobileNet与原始的GoogleNet [30]和VGG16 [27]进行了对比。MobileNet的准确性几乎与VGG16相同,但其模型大小比VGG16小32倍,计算量少27倍。它的准确性比GoogleNet高,同时模型更小,计算量也比GoogleNet少2.5倍以上。
表9将缩小版的MobileNet(宽度乘数α = 0.5和分辨率160 × 160)与AlexNet [19]进行对比。缩小版MobileNet比AlexNet高4%的准确性,同时模型比AlexNet小45倍,计算量减少9.4倍。它的表现也比Squeezenet [12]高4%,且大小相当,计算量减少22倍。
精读
-
不同的宽度因子对准确率、计算量和大小的权衡的影响:
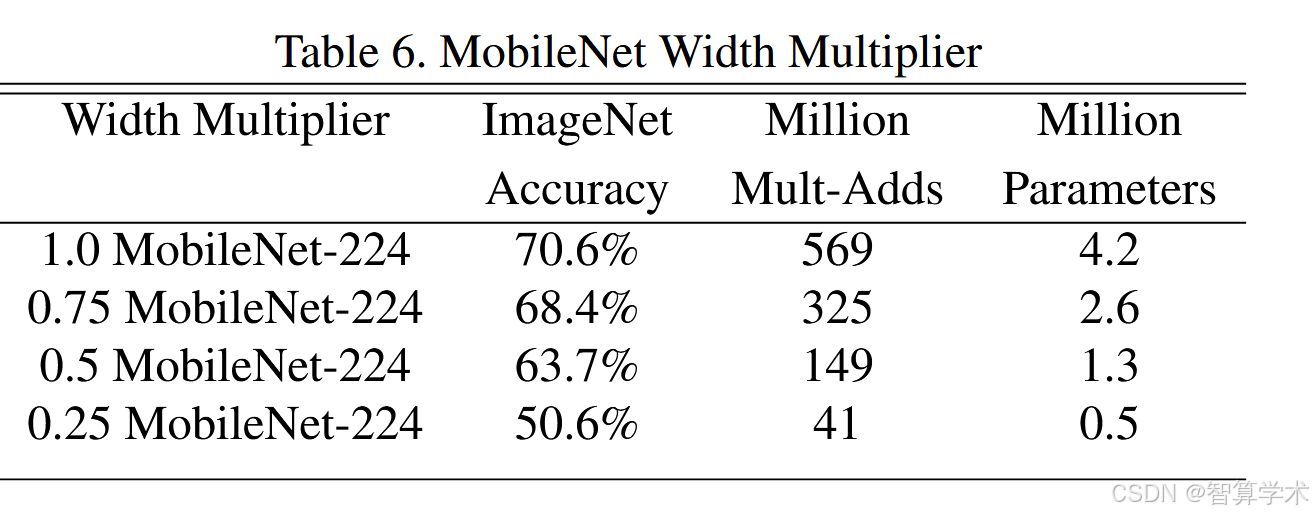
准确性平稳下降,直到架构变得过小时(α = 0.25)
-
减少输入分辨率训练MobileNet时,不同分辨率乘数的准确性、计算量和大小的权衡
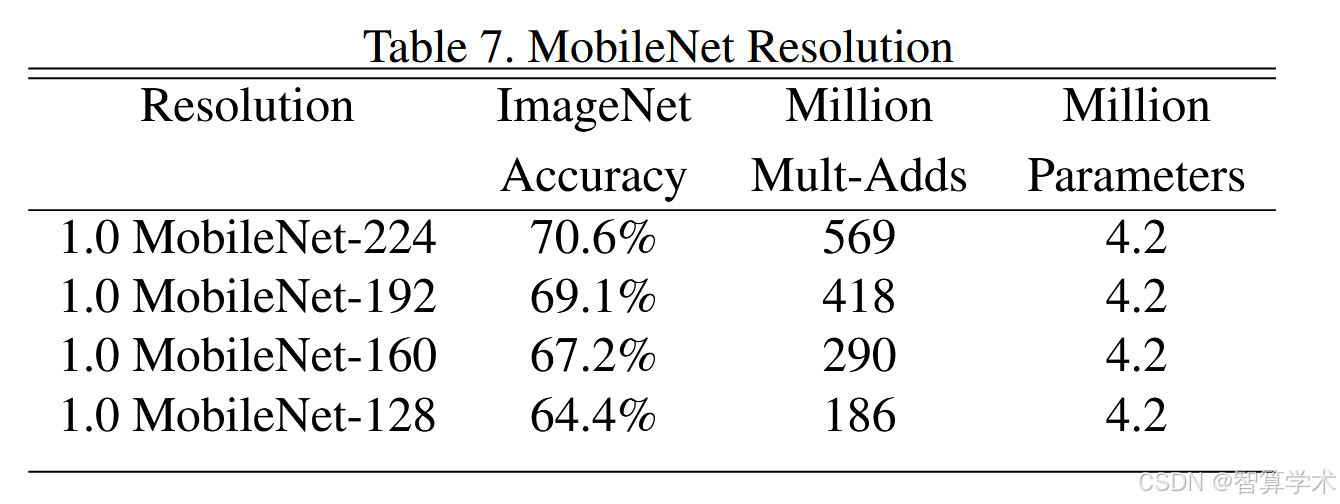
结果:准确性在不同分辨率之间平稳下降
-
计算量(Mult-Adds)对准确率的影响
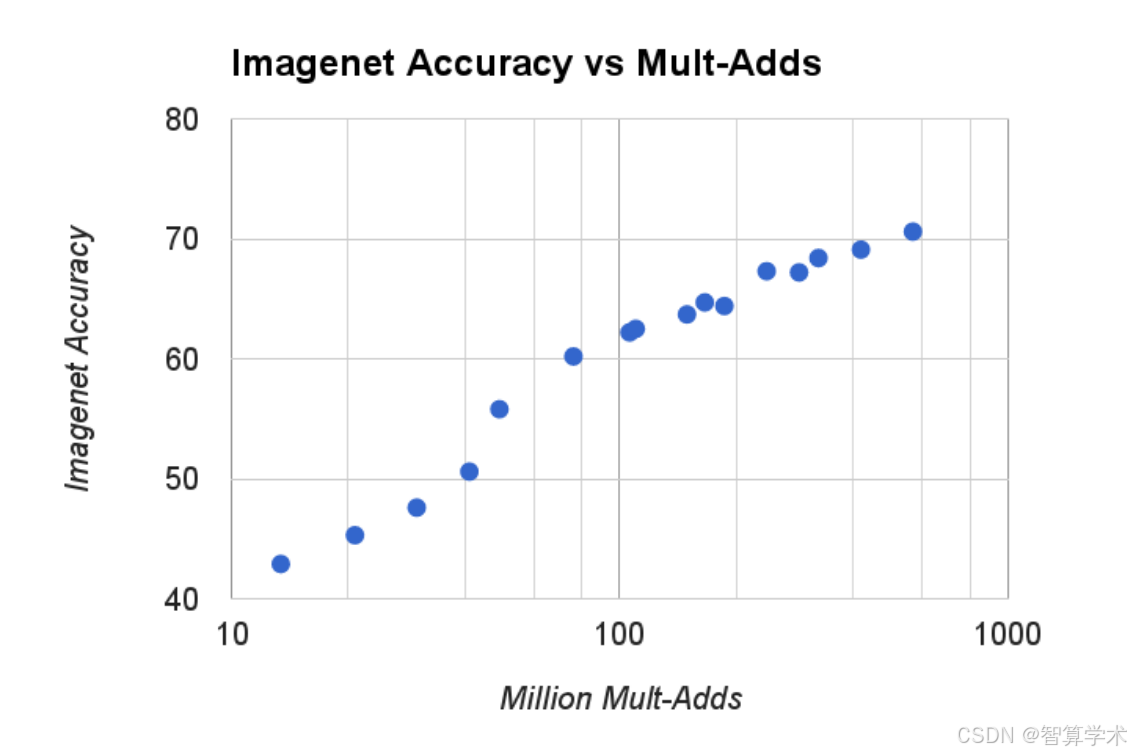
结果:随着计算量的增加,准确率在平稳变大
4、和先进模型对比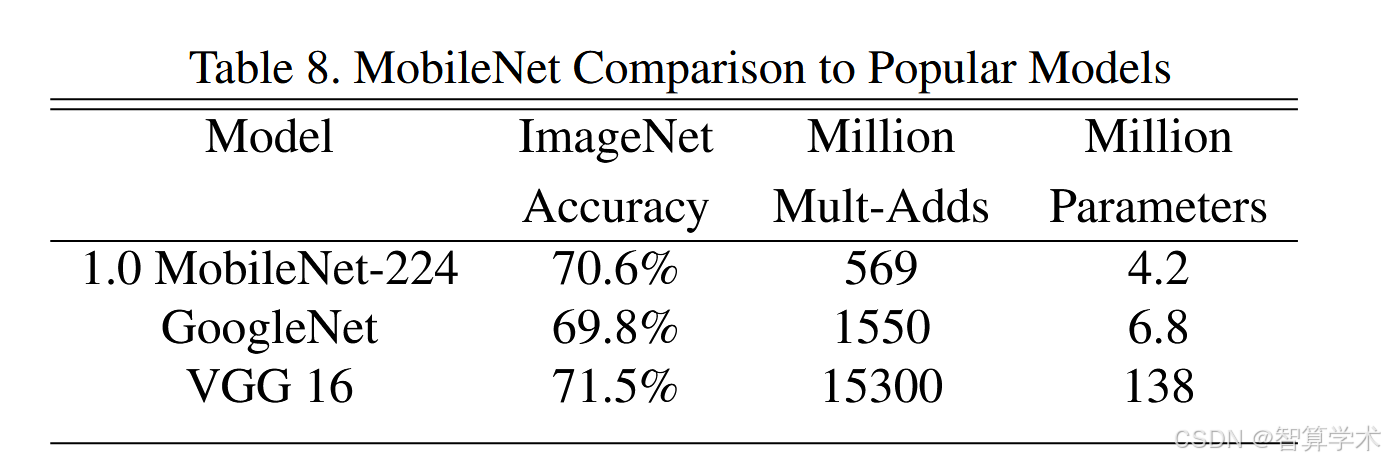
MobileNet 参数量和计算量都是最少的,在正确率上超过googleNet,略低于vgg16
4.3 Fine Grained Recognition—细粒度图像分类
翻译
我们在斯坦福狗狗数据集(Stanford Dogs dataset)[17]上训练了MobileNet进行细粒度识别。我们扩展了[18]的方法,并从网上收集了比[18]更大但更嘈杂的训练集。我们使用这些嘈杂的网络数据对细粒度狗狗识别模型进行预训练,然后在斯坦福狗狗训练集上进行微调。斯坦福狗狗测试集上的结果见表10。MobileNet几乎可以在大幅减少计算量和模型大小的情况下,达到[18]的最新成果。
精读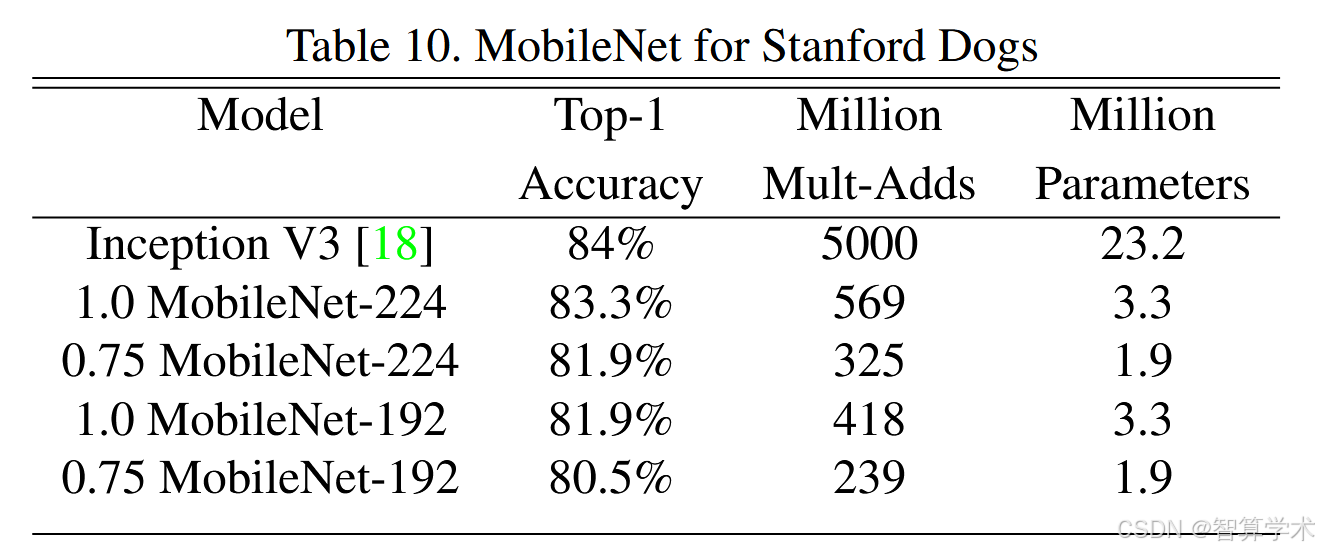
结果:MobileNet几乎能在大幅减少计算量和模型大小的情况下,达到IncepionV3的最新成果。
4.4 Large Scale Geolocalizaton—以图搜地
翻译
PlaNet [35] 将确定照片拍摄地点的任务视为一个分类问题。该方法将地球划分为一个地理网格,每个网格单元作为目标类别,并在数百万张带地理标签的照片上训练卷积神经网络。研究表明,PlaNet能够成功地定位各种照片,并且在执行相同任务时优于Im2GPS [6, 7]。我们使用MobileNet架构对PlaNet进行重新训练,数据集与原始模型相同。虽然基于Inception V3架构的完整PlaNet模型有5200万个参数和57.4亿次乘加运算(mult-adds),但MobileNet模型只有1300万个参数,其中300万个参数用于主体,1000万个参数用于最后一层,且只有58万次乘加运算。正如表11所示,尽管MobileNet模型更为紧凑,但其性能仅略有下降,且仍然大幅优于Im2GPS。
精读
基于以图搜地,对比不同网络结构进行对比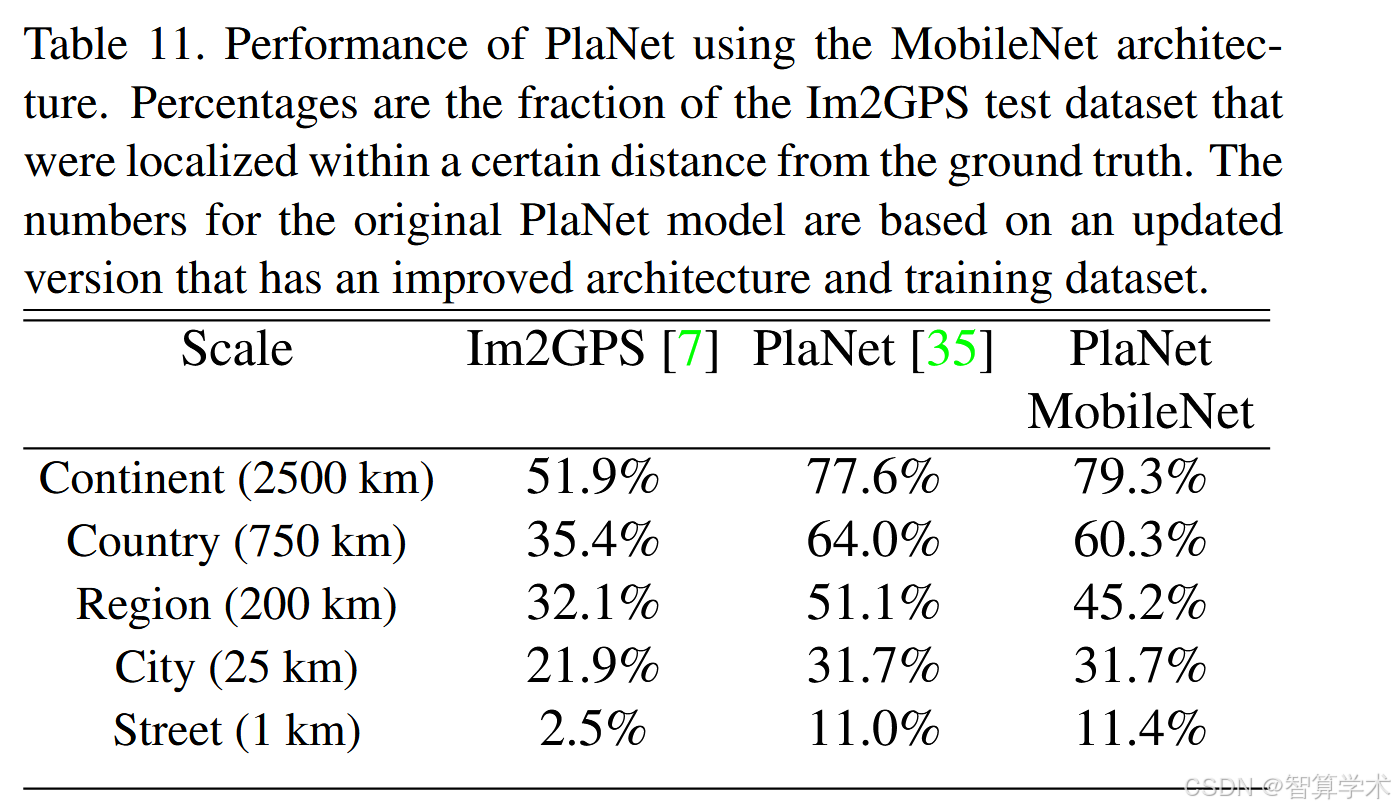
使用MobileNet重新训练PlaNet显著减少了模型大小和计算量,同时几乎保持与原始模型相当的性能,超越了Im2GPS。
4.5 Face Attributes—人脸属性
翻译
MobileNet的另一个应用场景是压缩那些训练过程未知或复杂的大型系统。在一个人脸属性分类任务中,我们展示了MobileNet与蒸馏(distillation)技术之间的协同关系。我们试图将一个具有7500万个参数和16亿Mult-Adds的人脸属性分类器压缩,该分类器是在类似YFCC100M的数据集上训练的。通过蒸馏,我们使用MobileNet架构来蒸馏这个人脸属性分类器。蒸馏技术通过训练分类器模仿一个较大模型的输出,而不是地面真值标签,从而实现从大规模(甚至是无限的)未标记数据集进行训练。结合蒸馏训练的可扩展性和MobileNet的简洁参数化,最终的系统不仅不需要正则化(例如权重衰减和提前停止),而且表现有所增强。从表12中可以明显看出,基于MobileNet的分类器对模型压缩具有较强的韧性:它在各个属性上的平均精度(mean AP)与原有模型相当,但计算量仅为1%的Mult-Adds。、
精读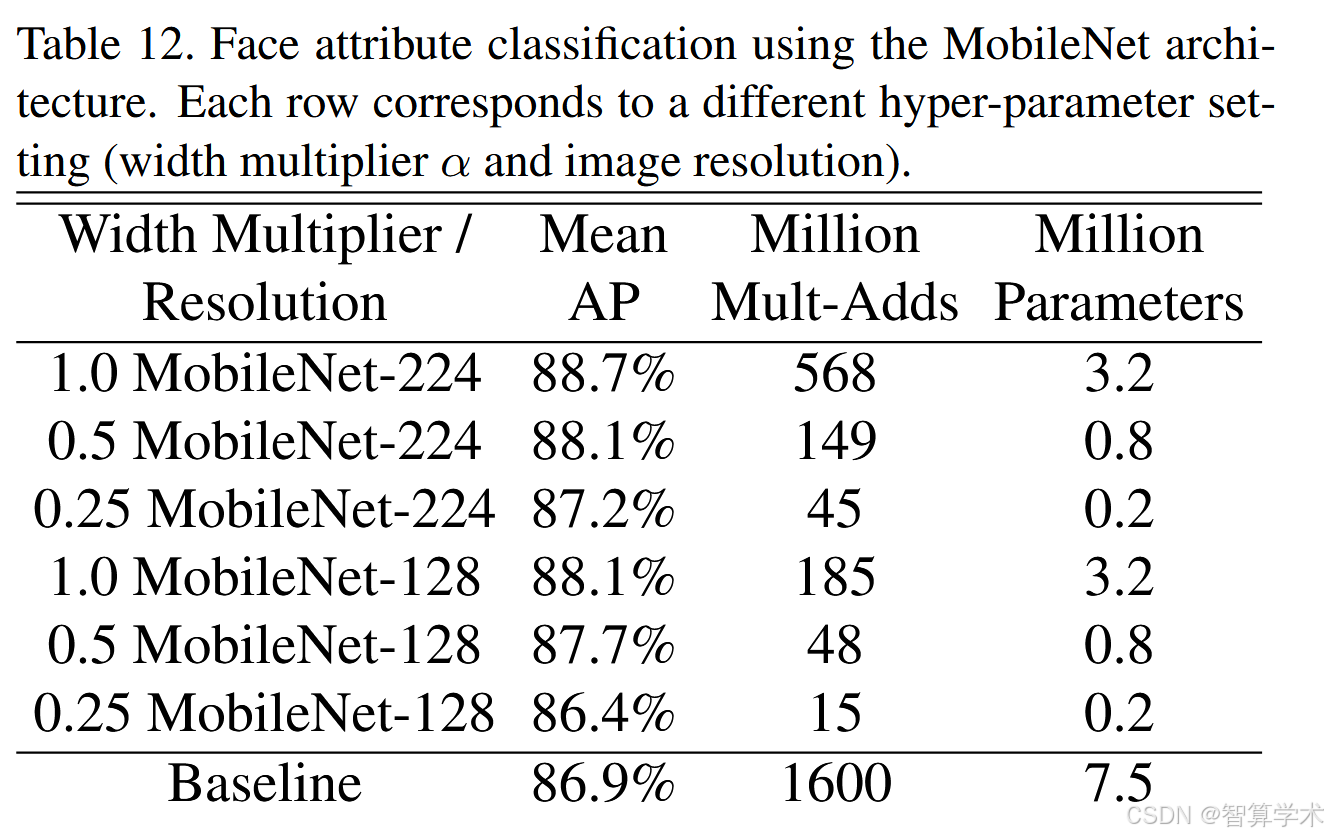
总结:通过结合蒸馏技术和MobileNet架构,成功压缩了一个大型人脸属性分类器,显著减少了计算量,同时保持了与原模型相似的性能。
4.6 Object Detection— 目标检测
翻译
MobileNet 还可以作为现代目标检测系统中的高效基础网络。我们基于 2016 年 COCO 挑战赛的获奖方法,在 COCO 数据集上训练 MobileNet 进行目标检测,并报告实验结果。在表 13 中,我们将 MobileNet 在 Faster-RCNN 和 SSD 框架下的表现,与 VGG 和 Inception V2 进行对比。实验中,SSD 采用 300 分辨率输入(SSD 300),Faster-RCNN 采用 300 和 600 分辨率输入(Faster-RCNN 300、Faster-RCNN 600),且 Faster-RCNN 模型每张图片评估 300 个 RPN 提案框。所有模型均在 COCO train+val(排除 8k minival 图像)上训练,并在 minival 集上进行评估。实验结果表明,在这两种检测框架下,MobileNet 仅用极少的计算量和模型大小,就能实现与其他网络相当的检测效果。
精读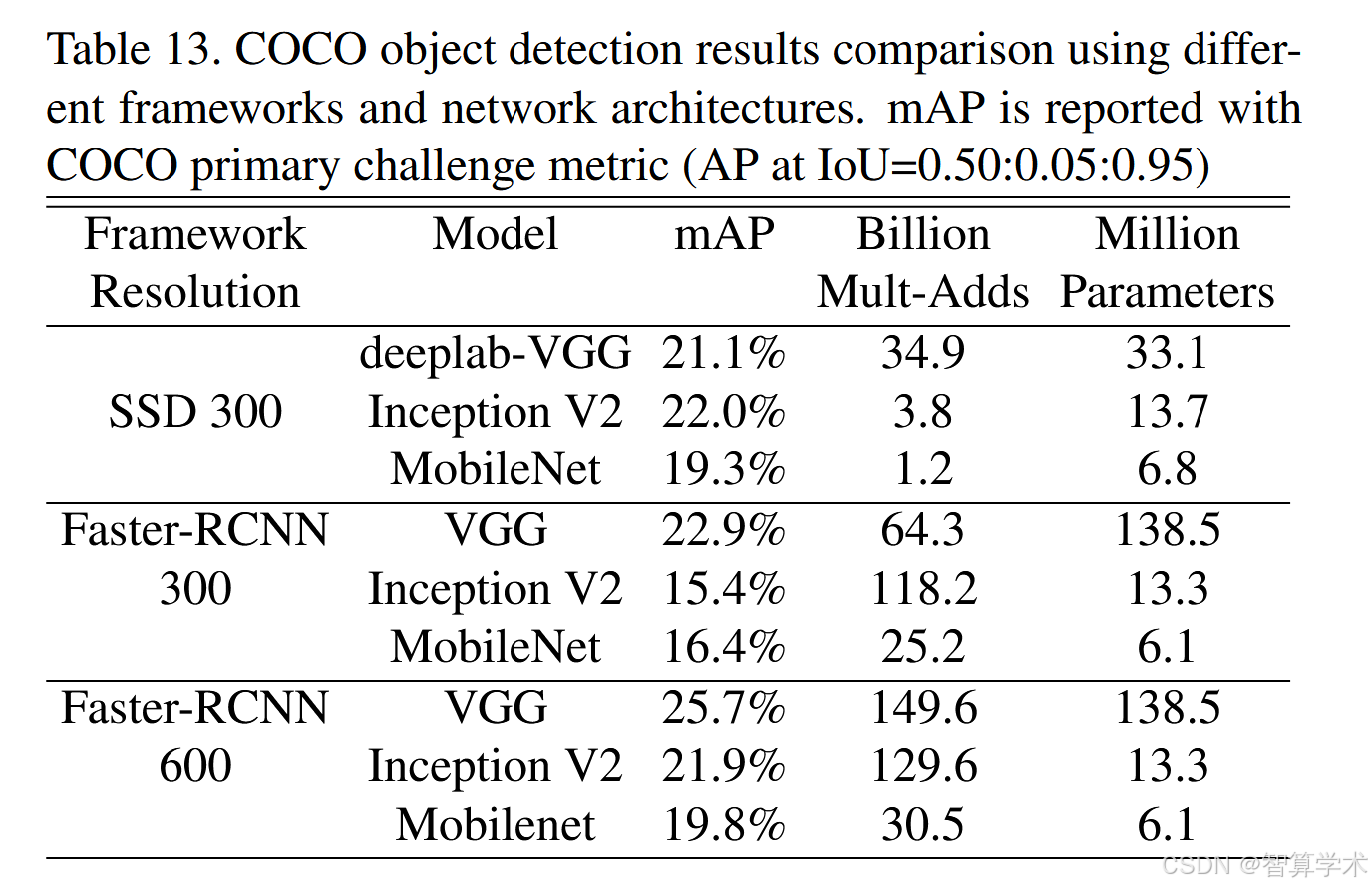
总结:MobileNet 作为目标检测的基础网络,在 COCO 数据集上的 Faster-RCNN(300 和 600 分辨率)和 SSD(300 分辨率)框架下,与 VGG 和 Inception V2 取得了可比的检测效果,同时相比 VGG 和 Inception V2,仅使用了其计算复杂度和模型大小的一小部分。
4.7 Face Embeddings—人脸识别
翻译
FaceNet 模型是一种先进的人脸识别模型,它基于三元组损失(triplet loss)构建人脸嵌入。为了构建移动端的 FaceNet 模型,我们使用蒸馏(distillation)方法进行训练,通过最小化 FaceNet 和 MobileNet 在训练数据上的输出平方差来优化模型。
精读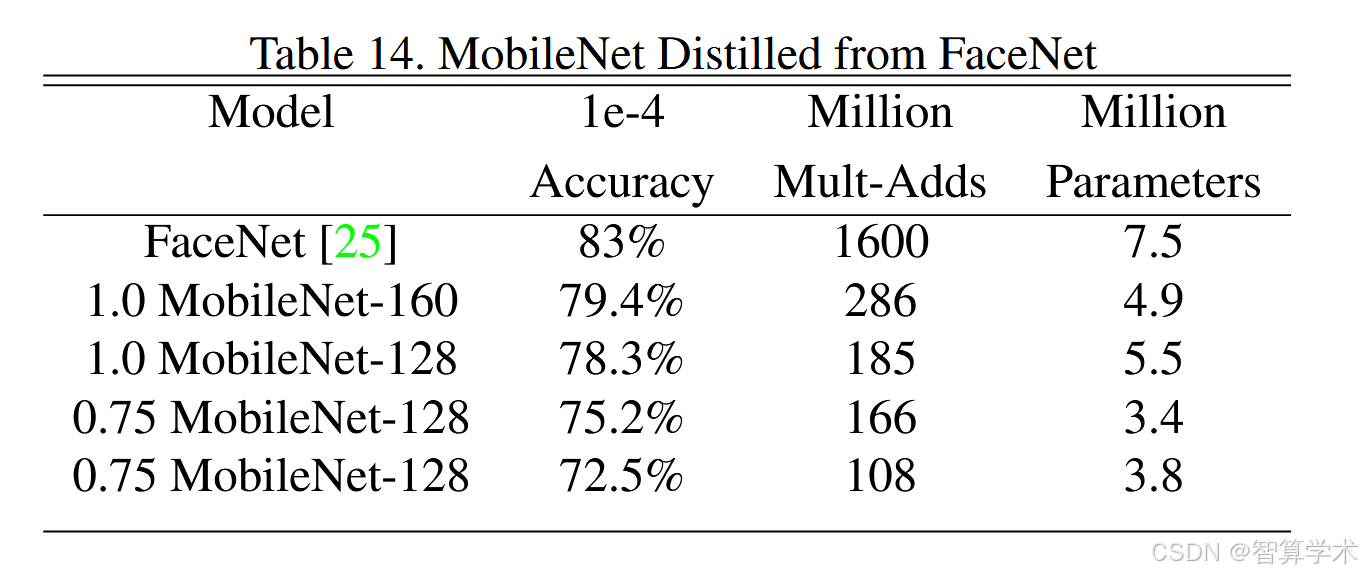
总结:通过蒸馏(distillation)技术,使用 MobileNet 训练了一个轻量级的 FaceNet 人脸识别模型,使其在计算量大幅降低的同时仍能保持较高的识别精度
五、Conclusion—结论
翻译
我们提出了一种新的模型架构——MobileNets,该架构基于深度可分离卷积。我们研究了影响模型高效性的关键设计决策,并展示了如何通过宽度因子和分辨率因子构建更小、更快的 MobileNets,在牺牲一定精度的情况下减少模型大小和计算延迟。随后,我们将不同版本的 MobileNets 与流行模型进行比较,展示了其在尺寸、速度和精度方面的优势。最后,我们证明了 MobileNet 在多种任务中的有效性。为了促进 MobileNets 的应用和进一步探索,我们计划在 TensorFlow 中发布相关模型。
精读
1.模型架构
采用深度可分离卷积(Depthwise Separable Convolutions)以降低计算复杂度,同时保持较高的准确率。
-
模型优化
通过宽度因子(Width Multiplier)和分辨率因子(Resolution Multiplier)调整模型大小,实现计算量和精度的权衡。
3.实验结果
-
MobileNets 在多个任务上(如图像分类、目标检测、人脸识别等)相比 VGG、InceptionV3 等主流模型,具有更小的模型尺寸和更快的推理速度。
4.任务适用性
-
在 COCO 目标检测、PlaNet 地理定位、FaceNet 人脸识别等任务中,MobileNets 在大幅减少计算量的同时仍保持竞争力。
5.未来计划
-
研究团队计划在 TensorFlow 中发布 MobileNets 预训练模型,以促进更广泛的应用和研究。


















 2206
2206

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









