








前言
上一篇给大家讲解了2019年google发表的EfficientNetV1版本网络,今天给大家带来EfficientNetV2版本的详解,因为谷歌更看重技术落地和影响力,不需要通过顶会发表来证明自己,所以 EfficientNetV2 直接发布在 arXiv,以更快、更自由的方式公开,同时保护商业利益和技术节奏。EfficientNetV2 在训练速度优化方面,在保持推理性能的同时,更关注模型的训练效率,在efficientNetV1的基础上引入 Fused-MBConv 模块,并结合更强的数据增强与正则化策略使得模型在不同规模的数据集上均展现出更好的泛化能力和鲁棒性。
论文地址:EfficientNetV2: Smaller Models and Faster Training
论文讲解+代码讲解:B站 智算学术
领取100G深度学习资料,500多篇经典论文,模块缝合,论文辅导等请关注作者公众号: 智算学术 回复:资料 领取
前景回顾
LeNet 论文精读 | 深度解析+PyTorch代码复现(上)
LeNet 论文精读 | 深度解析+PyTorch代码复现(下)
AlexNet 论文精读 | 深度解析+PyTorch代码复现 (上)
AlexNet 论文精读 | 深度解析+PyTorch代码复现 (下)
VGG论文精读 | 翻译+学习笔记+PyTorch代码复现
GoogleNet论文精读 | 翻译+学习笔记+PyTorch代码复现
ResNet论文精读:翻译+学习笔记+Pytorch代码复现
MobileNetV1论文精读(八):翻译+学习笔记+pytorch代码复现
MobileNetV2论文精读(九):翻译+学习笔记+pytorch代码复现
MobileNetV3论文精读(十):翻译+学习笔记+pytorch代码复现
ShuffleNetV1论文精读(十一):翻译+学习笔记+pytorch代码复现
ShuffleNetV2论文精读(十二):翻译+学习笔记+pytorch代码复现
EfficientNetV1论文精读(十三):翻译+学习笔记+pytorch代码复现
目录
三、EfficientNetV2 Architecture Design—高效EfficientNetV2架构设计
3.1 Review of EfficientNet—回顾EfficientNet
3.2 Understanding Training Efficiency—了解训练效率
3.3 Training-Aware NAS and Scaling—训练感知NAS和缩放
4.2 Progressive Learning with adaptive Regularization—自适应正则化的渐进学习
5.3 Transfer Learning Datasets—迁移学习数据集
6.1 Comparison to EfficientNet—与EfficientNet的比较
6.2 Progressive Learning for Different Networks—针对不同网络的渐进式学习
6.3 Importance of Adaptive Regularization—自适应正则化的重要性
Abstract—摘要
翻译
本文提出了 EfficientNetV2,一个新的卷积神经网络系列,其训练速度更快、参数效率也优于以往的模型。为了设计这些模型,我们结合了训练感知的神经架构搜索和缩放策略,以同时优化训练速度和参数效率。模型是在一个扩展了新操作(如 Fused-MBConv)的搜索空间中搜索得到的。实验表明,EfficientNetV2 相比现有最先进的模型,训练速度大幅提升,且模型体积最多可缩小 6.8 倍。 此外,我们通过在训练过程中逐步增加图像尺寸的方法进一步加速训练,但这一做法通常会导致精度下降。为了解决这一问题,我们提出了一种改进的渐进式学习方法,能够在调整图像尺寸的同时,自适应地调整正则化强度(如数据增强)。 使用渐进式学习后,EfficientNetV2 在 ImageNet、CIFAR、Cars 和 Flowers 等数据集上显著超越了以往的模型。在同样以 ImageNet21k 进行预训练的条件下,EfficientNetV2 在 ImageNet ILSVRC2012 上达到了 87.3% 的 top-1 准确率,比最新的 ViT 模型高出 2.0%,且在相同计算资源下训练速度快了 5 至 11 倍。
精读
提出 EfficientNetV2 模型系列: 相比之前的 EfficientNet,新的网络在训练速度和参数效率上都有显著提升。
使用训练感知的架构搜索 (Training-Aware NAS): 在搜索过程中,不只是考虑推理性能,还把训练速度作为优化目标,找到更易训练的结构。
引入 Fused-MBConv 模块: 在搜索空间中添加了新的高效操作(如 Fused-MBConv),进一步加快训练速度。
提出渐进式学习 (Progressive Learning): 在训练过程中逐步增大输入图像尺寸,同时自适应调整正则化强度(如数据增强幅度),避免模型在训练中出现精度下降。
实验验证:
-
在 ImageNet、CIFAR、Cars、Flowers 等多个数据集上大幅提升了准确率和训练速度。
-
比如在 ImageNet ILSVRC2012 上,EfficientNetV2 在使用相同预训练(ImageNet21k)时,比 ViT 准确率高 2%,训练速度快 5-11 倍。
一、Introduction—简介
翻译
训练效率对深度学习非常重要,因为模型的规模和训练数据的规模日益增大。例如,GPT-3(Brown 等,2020)作为一个拥有更大模型和更多训练数据的模型,展示了在少样本学习中的卓越能力,但它需要数周的时间和成千上万的 GPU 来训练,这使得它很难进行重新训练或改进。训练效率近年来受到广泛关注。例如,NFNets(Brock 等,2021)旨在通过去除昂贵的批量归一化来提高训练效率;一些近期的研究(Srinivas 等,2021)通过在卷积神经网络(ConvNets)中添加注意力层来加速训练;Vision Transformers(Dosovitskiy 等,2021)则通过使用 Transformer 块来提高大规模数据集上的训练效率。然而,这些方法通常会带来较大的参数开销,如图 1(b) 所示。本文通过结合训练感知的神经架构搜索(NAS)和缩放技术,改善了训练速度和参数效率。鉴于 EfficientNets(Tan & Le,2019a)在参数效率上的优势,我们首先系统地研究了 EfficientNets 的训练瓶颈。我们的研究发现:在 EfficientNets 中,(1) 使用非常大的图像尺寸训练速度较慢;(2) 深度可分离卷积在前几层训练时较慢;(3) 对每一阶段进行等比例缩放是次优的。基于这些观察,我们设计了一个扩展了 Fused-MBConv 等新操作的搜索空间,并应用训练感知的 NAS 和缩放策略来联合优化模型的准确性、训练速度和参数大小。我们发现的网络,命名为 EfficientNetV2,比之前的模型训练速度快最多 4 倍(图 3),同时参数大小最多缩小 6.8 倍。 我们的训练方法还可以通过在训练过程中逐步增加图像尺寸来进一步加速。许多之前的研究,如渐进式尺寸调整(Howard,2018)、FixRes(Touvron 等,2019)和 Mix&Match(Hoffer 等,2019),在训练时使用较小的图像尺寸,但它们通常对所有图像尺寸保持相同的正则化,这会导致精度下降。我们认为,对于不同图像尺寸保持相同的正则化并不理想:对于同一个网络,小图像尺寸导致小的网络容量,因此需要较弱的正则化;反之,大图像尺寸则需要更强的正则化来防止过拟合(见 4.1 节)。基于这一见解,我们提出了一种改进的渐进式学习方法:在训练的初期阶段,我们使用小图像尺寸和较弱的正则化(例如,dropout 和数据增强)进行训练,然后逐步增大图像尺寸并增加更强的正则化。我们的这一方法是在渐进式尺寸调整(Howard,2018)的基础上,通过动态调整正则化实现的,可以在加速训练的同时避免精度下降。 通过改进的渐进式学习,EfficientNetV2 在 ImageNet、CIFAR-10、CIFAR100、Cars 和 Flowers 数据集上取得了显著的结果。在 ImageNet 上,我们在训练速度上提高了 3-9 倍,并且参数大小最多缩小了 6.8 倍,达到了 85.7% 的 top-1 准确率(图 1)。我们的 EfficientNetV2 和渐进式学习方法还使得在更大数据集上的训练变得更加容易。例如,ImageNet21k(Russakovsky 等,2015)比 ImageNet ILSVRC2012 大约大 10 倍,但我们的 EfficientNetV2 可以在使用 32 个 TPUv3 核心的中等计算资源下,在两天内完成训练。通过在公开的 ImageNet21k 上进行预训练,我们的 EfficientNetV2 在 ImageNet ILSVRC2012 上取得了 87.3% 的 top-1 准确率,超越了最近的 ViT-L/16 2.0%的准确率,同时训练速度快了 5 倍至 11 倍(图 1)。 我们的贡献有三点: • 我们提出了 EfficientNetV2,这是一个新的、更小且更快速的模型系列。通过训练感知的 NAS 和缩放方法,EfficientNetV2 在训练速度和参数效率上超越了之前的模型。 • 我们提出了一种改进的渐进式学习方法,可以根据图像尺寸动态调整正则化。我们证明了这种方法不仅加速了训练,还提高了精度。 • 我们在 ImageNet、CIFAR、Cars 和 Flowers 数据集上展示了最多 11 倍的训练速度提升和最多 6.8 倍的参数效率提升,超越了之前的研究成果。
精读
前人工作总结
-
深度学习训练效率:随着模型规模和数据量的增大,深度学习的训练效率成为了一个重要问题
-
NFNets:通过去除批量归一化层来提高训练效率
-
卷积神经网络中的注意力层:通过添加注意力层加速训练
-
Vision Transformers(ViTs):使用 Transformer 块来提高大规模数据集上的训练效率
以上工作只注重了训练效率,参数开销过大
工作中的不足
-
大图像尺寸训练缓慢 2. 深度可分离卷积训练较慢 3.等比例缩放模型并不是最优的,会影响模型效率 4. 正则化问题:渐进式训练方法(例如渐进式尺寸调整、FixRes 等)通常保持相同的正则化,但这会导致精度下降,因为对于不同的图像尺寸需要不同强度的正则化。
本文主要贡献
-
提出 EfficientNetV2:基于训练感知的神经架构搜索(NAS)和缩放技术,提出了 EfficientNetV2。这些新模型在训练速度和参数效率方面比之前的模型要快得多,同时模型的参数量最多可以减少 6.8 倍。
-
引入改进的渐进式学习方法:提出了一种新的渐进式学习方法,在训练过程中动态调整正则化和图像尺寸。这种方法能够在加速训练的同时避免精度下降。
二、Related work—相关工作
翻译
训练和参数效率
许多研究,如 DenseNet(Huang 等,2017)和 EfficientNet(Tan & Le,2019a),关注参数效率,旨在通过减少参数量实现更好的准确性。一些更近期的工作则专注于提高训练或推理速度,而不是参数效率。例如,RegNet(Radosavovic 等,2020)、ResNeSt(Zhang 等,2020)、TResNet(Ridnik 等,2020)和 EfficientNet-X(Li 等,2021)聚焦于 GPU 和/或 TPU 推理速度;NFNets(Brock 等,2021)和 BoTNets(Srinivas 等,2021)则专注于提高训练速度。然而,这些方法的训练或推理速度通常伴随着更多的参数。本文旨在显著提高训练速度和参数效率,相比现有方法具有更好的表现。
渐进式训练
之前的工作提出了不同类型的渐进式训练,这些方法动态调整训练设置或网络,应用于生成对抗网络(GANs)(Karras 等,2018)、迁移学习(Karras 等,2018)、对抗性学习(Yu 等,2019)和语言模型(Press 等,2021)。渐进式调整图像尺寸(Progressive Resizing)(Howard,2018)与我们的方法密切相关,旨在提高训练速度。然而,通常会带来精度下降。另一个相关的工作是 Mix&Match(Hoffer 等,2019),它为每个批次随机采样不同的图像尺寸。渐进式调整图像尺寸和 Mix&Match 都为所有图像尺寸使用相同的正则化,导致精度下降。本文的主要区别在于,我们还自适应地调整正则化,从而同时提高训练速度和准确性。我们的方法部分受课程学习(Curriculum Learning)(Bengio 等,2009)的启发,该方法将训练样本从易到难进行调度。我们的方法也通过增加正则化逐步增加学习难度,但我们并不会选择性地挑选训练样本。
神经架构搜索(NAS)
通过自动化网络设计过程,神经架构搜索(NAS)已经被用于优化图像分类(Zoph 等,2018)、目标检测(Chen 等,2019;Tan 等,2020)、分割(Liu 等,2019)、超参数(Dong 等,2020)以及其他应用(Elsken 等,2019)的网络架构。之前的 NAS 工作大多集中在提高 FLOPs 效率(Tan & Le,2019b;a)或推理效率(Tan 等,2019;Cai 等,2019;Wu 等,2019;Li 等,2021)。与之前的工作不同,本文使用 NAS 来优化训练和参数效率。
精读
训练和参数效率:
用FLOPs 来衡量模型好坏:DenseNet和EfficientNet
用推理速度来衡量模型好坏:RegNet、ResNeSt和TResNet等
本文衡量模型的时候不但要关注FLOPs 还要关注推理速度
渐进式训练:通过自适应调整正则化来解决这一问题,确保在提高训练速度的同时不牺牲准确性。这一方法受到课程学习的启发,逐步增加训练难度。
神经架构搜索(NAS):本文使用NAS优化训练效率和参数效率
三、EfficientNetV2 Architecture Design—高效EfficientNetV2架构设计
在本节中,我们研究了EfficientNet(Tan & Le, 2019a)的训练瓶颈,并介绍了我们的训练感知NAS和缩放方法,以及EfficientNetV2模型。
3.1 Review of EfficientNet—回顾EfficientNet
翻译
EfficientNet(Tan & Le, 2019a)是一系列优化了FLOPs和参数效率的模型。它利用NAS搜索基准模型EfficientNet-B0,该模型在准确性和FLOPs之间具有更好的平衡。然后,基准模型通过复合缩放策略进行扩展,得到一系列模型B1-B7。尽管近期的研究声称在训练或推理速度上有显著提升,但在参数和FLOPs效率方面,它们通常不如EfficientNet(见表1)。本文的目标是在保持参数效率的同时,提升训练速度。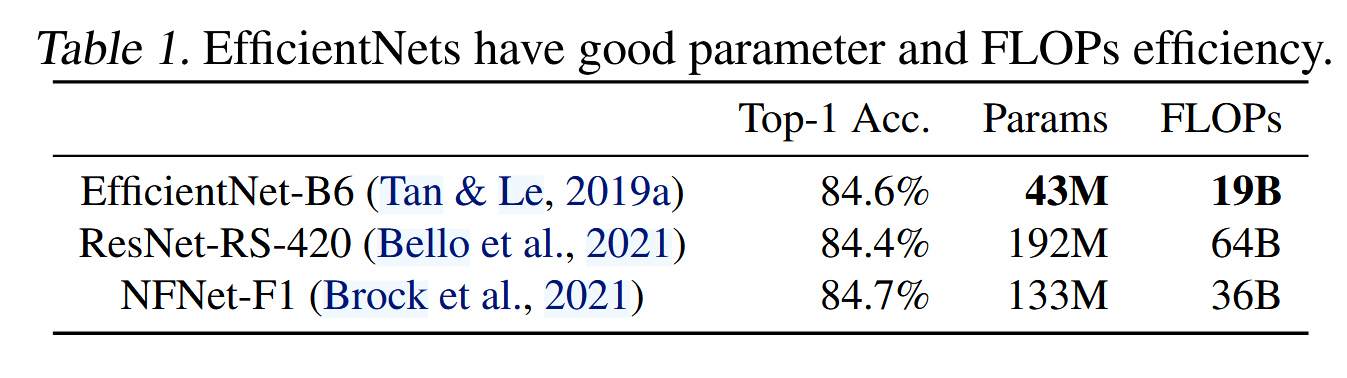
精读
EfficientNetV1版本论文精读链接:EfficientNetV1论文精读(十三):翻译+学习笔记+pytorch代码复现-CSDN博客
B站视频讲解链接:efficientNetV1论文精读: pytorch 代码复现_哔哩哔哩_bilibili
3.2 Understanding Training Efficiency—了解训练效率
翻译
我们研究了EfficientNet(Tan & Le, 2019a,以下简称EfficientNetV1)的训练瓶颈,并提出了一些简单的技术来提高训练速度。
使用非常大的图像尺寸训练很慢: 正如之前的研究所指出的(Radosavovic et al., 2020),EfficientNet使用较大的图像尺寸会导致显著的内存消耗。由于GPU/TPU的总内存是固定的,我们必须使用较小的批量大小进行训练,这会大大减慢训练速度。一个简单的改进方法是应用FixRes(Touvron et al., 2019),即在训练中使用比推理时更小的图像尺寸。如表2所示,较小的图像尺寸减少了计算量,并允许使用更大的批量大小,从而将训练速度提高了最多2.2倍。值得注意的是,如(Touvron et al., 2020; Brock et al., 2021)所指出,使用较小的图像尺寸进行训练还会略微提高准确性。但不同于(Touvron et al., 2019),我们在训练后不会对任何层进行微调。我们将在第4节中探讨通过逐步调整图像尺寸和正则化的更高级训练方法。
深度可分卷积在早期层较慢,但在后期阶段有效: EfficientNet的另一个训练瓶颈来自于广泛使用的深度可分卷积(Sifre, 2014)。深度可分卷积相比常规卷积具有更少的参数和FLOPs,但往往无法充分利用现代加速器。最近,在(Gupta & Tan, 2019)中提出了Fused-MBConv,并在(Gupta & Akin, 2020;Xiong et al., 2020;Li et al., 2021)中得到了应用,以更好地利用移动设备或服务器加速器。它将MBConv(Sandler et al., 2018;Tan & Le, 2019a)中的深度可分卷积3x3和扩展卷积1x1替换为一个常规卷积3x3,如图2所示。为了系统地比较这两种构建块,我们逐渐将EfficientNet-B4中的原始MBConv替换为FusedMBConv(表3)。当应用于早期的阶段1-3时,FusedMBConv可以提高训练速度,并在参数和FLOPs上带来较小的开销。但如果我们将所有阶段都替换为Fused-MBConv(阶段1-7),则会显著增加参数和FLOPs,同时还会减慢训练速度。找到这两种构建块(MBConv和Fused-MBConv)的最佳组合并非易事,这促使我们利用神经架构搜索(NAS)来自动搜索最佳组合。
每个阶段均匀缩放是次优的: EfficientNet通过简单的复合缩放规则均匀地扩展所有阶段。例如,当深度系数为2时,网络中的所有阶段都会将层数加倍。然而,这些阶段对训练速度和参数效率的贡献并不相同。本文将采用非均匀缩放策略,逐步增加后期阶段的层数。此外,EfficientNet过度扩展图像尺寸,导致内存消耗大且训练速度慢。为了解决这个问题,我们稍微修改了缩放规则,并将最大图像尺寸限制为较小的值。
精读
表2中:在使用大的图像size=512下,我们的batch=24设置变大后直接oom了,爆内存了
使用较小的图像size= 380下,我们的batch=24,可以看到我们在缩小图像尺寸,增大batch的情况下,准确率还增加了,gpu的处理速度明显增加了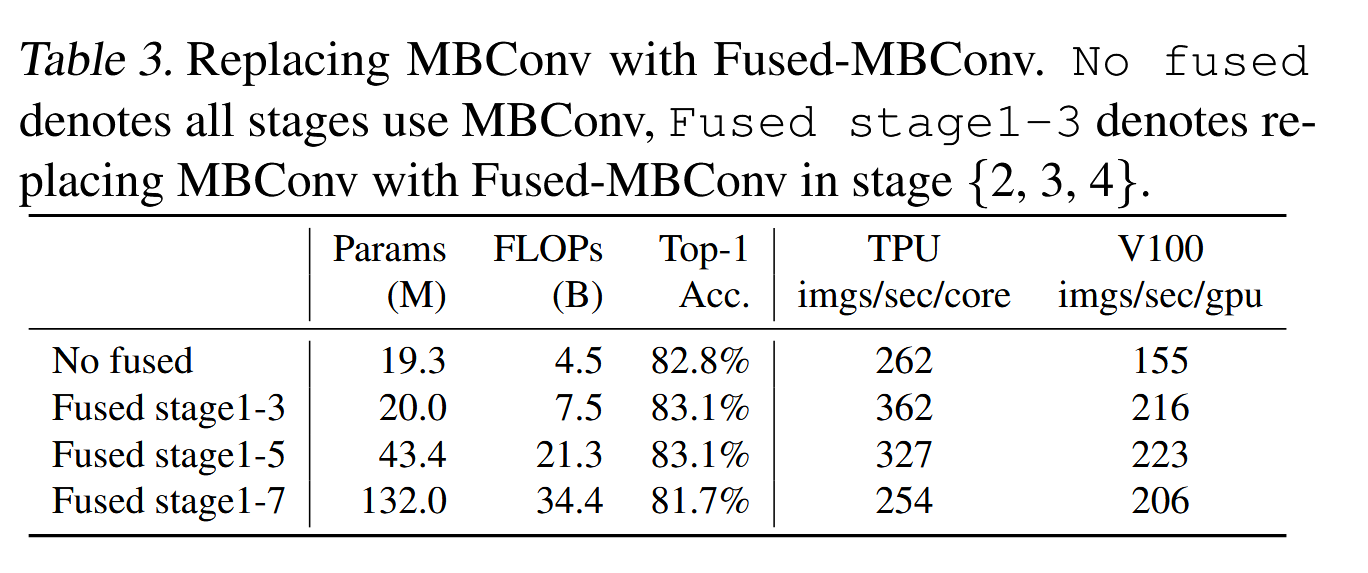
表3:深度可分卷积虽然在参数和FLOPs上较为高效,但在现代加速器上无法充分利用。通过引入Fused-MBConv替代部分深度可分卷积,提升了训练速度,且参数和FLOPs开销较小。
stage1-3阶段用Fused-MBConv 替代后,正确率和gpu每秒处理图片的速度在增加,stage1-3阶段用Fused-MBConv 替代后gpu每秒处理图片的速度依旧增加,但是在全部替换为Fused-MBConv后,参数量和计算量在增加的同时,准确率在下降,gpu每秒处理图片的速度也在下降
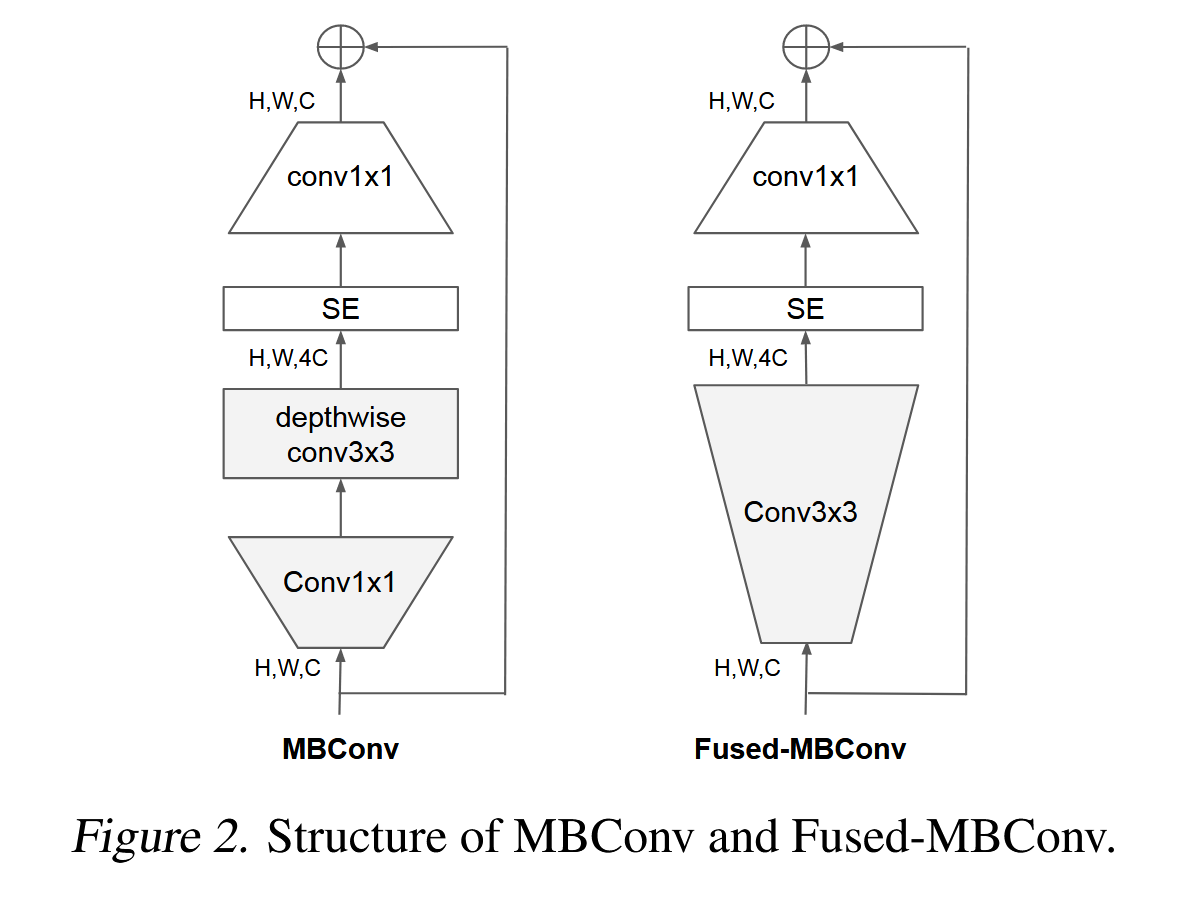 图二所示为MBConv 和 Fused-MBConv 对比,很明显就是把conv1X1 卷积和DW卷积 替换为一个Conv3x3 的卷积核
图二所示为MBConv 和 Fused-MBConv 对比,很明显就是把conv1X1 卷积和DW卷积 替换为一个Conv3x3 的卷积核
均匀缩放策略的局限性:EfficientNet使用简单的复合缩放策略来扩展每个阶段,但这种均匀缩放方式并非最优。(1)本文提出了非均匀缩放策略,逐步增加后期stage的层数,从而优化训练速度和参数效率。(2)对缩放规则进行了轻微调整并将最大图像尺寸限制在一个较小的数值。
3.3 Training-Aware NAS and Scaling—训练感知NAS和缩放
翻译
为此,我们研究了多种提高训练速度的设计选择。为了寻找最佳的设计组合,我们提出了一个训练感知的神经架构搜索(NAS)。
NAS搜索:我们的训练感知NAS框架在很大程度上基于之前的NAS工作(Tan等,2019;Tan & Le,2019a),但旨在联合优化现代加速器上的准确性、参数效率和训练效率。具体来说,我们使用EfficientNet作为骨干网络。我们的搜索空间是一个基于阶段的分解空间,类似于(Tan等,2019),包括卷积操作类型{MBConv,Fused-MBConv}、层数、卷积核大小{3x3,5x5}、扩展比{1,4,6}等设计选择。另一方面,我们通过以下方式减少搜索空间的大小:(1) 去除不必要的搜索选项,如池化跳过操作,因为它们在原始EfficientNets中从未使用过;(2) 复用骨干网络中已搜索的相同通道大小(因为这些已经在(Tan & Le, 2019a)中进行了搜索)。由于搜索空间较小,我们可以使用强化学习(Tan等,2019)或简单的随机搜索,针对类似EfficientNetB4大小的大型网络进行搜索。具体来说,我们最多采样1000个模型,并对每个模型进行大约10个epoch的训练,使用减小的训练图像大小。我们的搜索奖励结合了模型的准确性A、归一化训练步骤时间S和参数大小P,使用简单的加权乘积A · Sw · P v,其中w = -0.07和v = -0.05是根据经验确定的,以平衡类似于(Tan等,2019)的权衡。
EfficientNetV2架构:表4显示了我们搜索到的模型EfficientNetV2-S的架构。与EfficientNet骨干网络相比,我们搜索到的EfficientNetV2有几个主要区别:(1) EfficientNetV2在早期层广泛使用了MBConv(Sandler等,2018;Tan & Le,2019a)和新加入的Fused-MBConv(Gupta & Tan,2019)。(2) 其次,EfficientNetV2倾向于使用较小的MBConv扩展比,因为较小的扩展比往往会减少内存访问开销。(3) 第三,EfficientNetV2倾向于使用较小的3x3卷积核,但通过增加更多的层来补偿由于较小卷积核导致的感受野减小。(4) 最后,EfficientNetV2完全去除了原始EfficientNet中的最后一个步幅为1的阶段,这可能是因为它的参数规模大且内存访问开销较高。
EfficientNetV2扩展:我们使用类似于(Tan & Le, 2019a)的复合扩展方法,将EfficientNetV2-S扩展为EfficientNetV2-M/L,并进行了几项额外优化:(1) 我们将最大推理图像大小限制为480,因为非常大的图像通常会导致高昂的内存和训练速度开销;(2) 作为启发式,我们还逐渐将更多的层添加到后期阶段(例如表4中的阶段5和6),以增加网络容量而不增加太多的运行时开销。
训练速度比较:图3比较了我们新的EfficientNetV2的训练步骤时间,所有模型都使用固定的图像大小进行训练,而没有进行渐进式学习。对于EfficientNet(Tan & Le,2019a),我们展示了两条曲线:一条是使用原始推理大小训练,另一条是使用大约30%的较小图像大小训练,与EfficientNetV2和NFNet(Touvron等,2019;Brock等,2021)相同。所有模型都训练了350个epoch,除了NFNet训练了360个epoch,因此所有模型的训练步骤数相似。有趣的是,我们观察到当训练得当时,EfficientNet仍然能够实现相当强的性能权衡。更重要的是,通过我们的训练感知NAS和扩展,我们提出的EfficientNetV2模型训练速度明显快于其他最近的模型。这些结果也与我们的推理结果一致,如表7和图5所示。
精读
NAS搜索:与传统的NAS不同,这里不仅仅是关注网络的准确性(能做得多好),还会同时考虑两个其他方面—参数效率和训练效率
总的来说,NAS搜索就是通过自动化方式帮我们找出一个又好又快且参数少的网络结构,而不需要每次都手动调试每个参数,节省了大量的时间和精力。
EfficientNetV2架构:
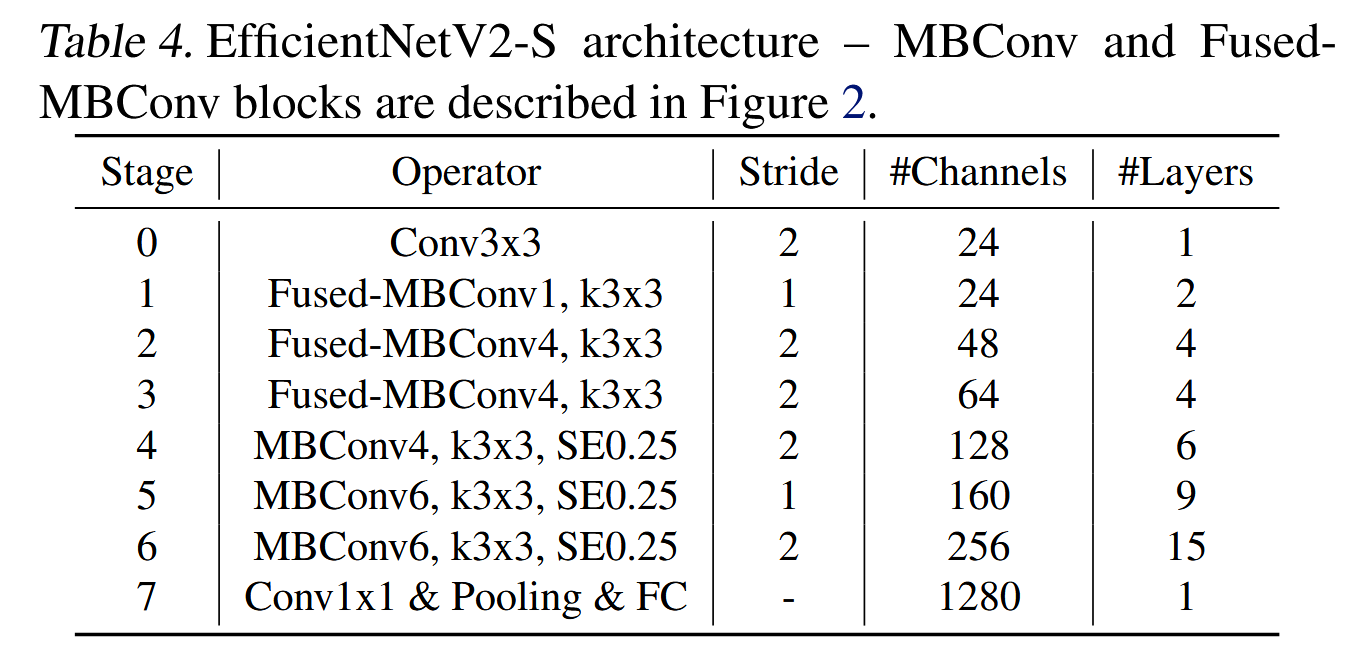 表4 是efficientNetV2的参数表,和v1版本有几点不同
表4 是efficientNetV2的参数表,和v1版本有几点不同
-
kernel_size 的大小只有3x3了,并通过增加层数来弥补感受野减小的缺陷
-
stage1-3 阶段换成了Fused-MBConv
-
移除了最后一个stride为1的stage,从而减少部分参数和内存访问
EfficientNetV2扩展:
我们通过复合扩展方法将EfficientNetV2-S扩展为EfficientNetV2-M/L,并对图像大小和层数进行优化,以减少内存开销并提高训练效率。1.将最大推理图像大小限制为480 2. 更多的层添加到后期阶段(例如表4中的阶段5和6)
训练速度比较
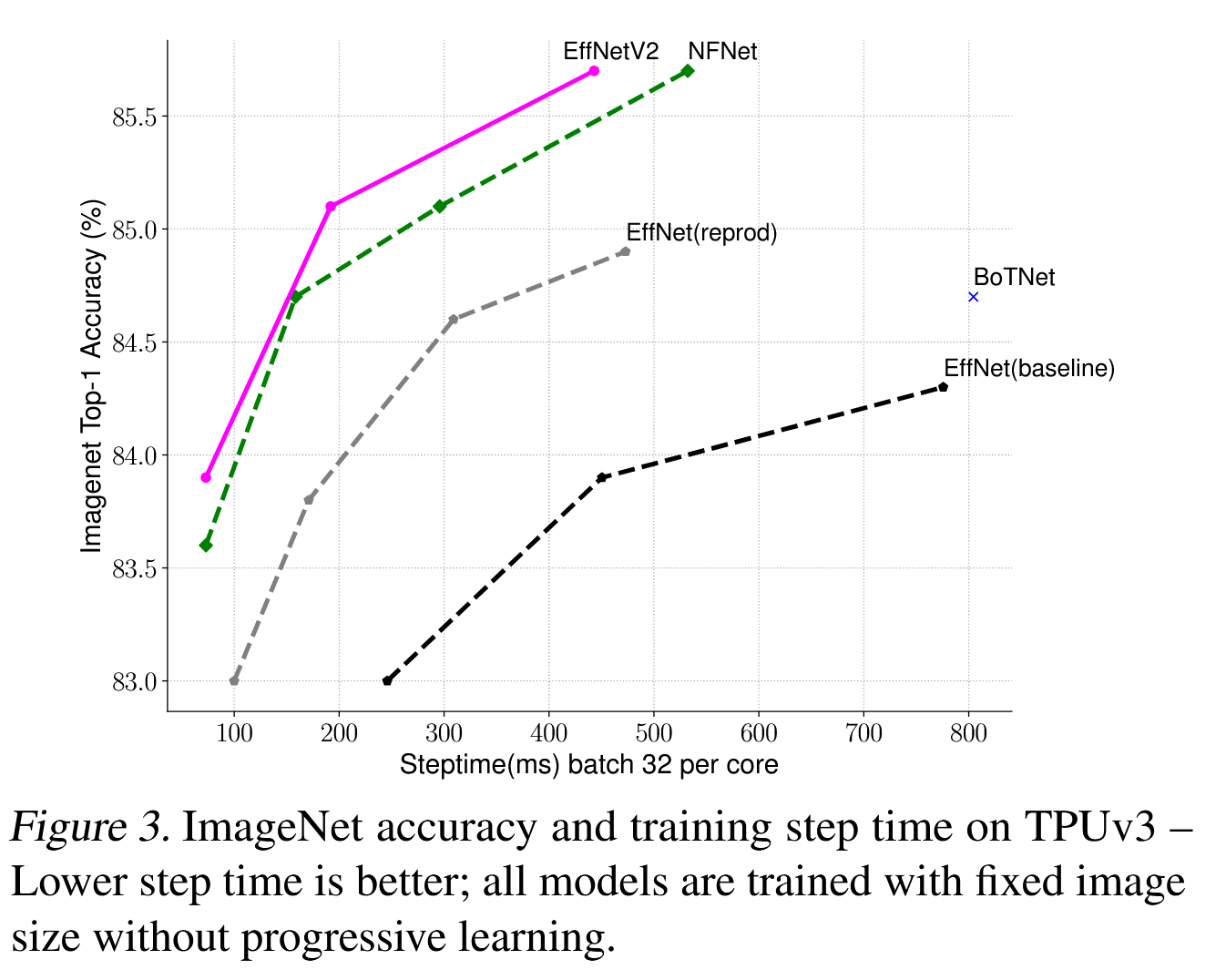 图3. 在TPUv3上的ImageNet准确率和训练步骤时间。较低的步骤时间更好;所有模型均使用固定的图像大小进行训练,且不进行渐进式学习。
图3. 在TPUv3上的ImageNet准确率和训练步骤时间。较低的步骤时间更好;所有模型均使用固定的图像大小进行训练,且不进行渐进式学习。
每核处理一个批次的时间,随着时间的增大,准确率也在增大。
四、Progressive Learning—渐进式学习
4.1 Motivation—动机
翻译
正如第3节所讨论的,图像大小在训练效率中起着重要作用。除了FixRes(Touvron等,2019)外,许多其他研究也在训练过程中动态调整图像大小(Howard,2018;Hoffer等,2019),但这些方法通常会导致准确率下降。我们假设准确率下降是由于正则化的不平衡:当使用不同的图像大小进行训练时,我们应该相应地调整正则化强度(而不是像之前的研究那样使用固定的正则化)。实际上,通常情况下,大型模型需要更强的正则化来防止过拟合:例如,EfficientNet-B7使用比B0更大的丢弃率和更强的数据增强。在本文中,我们认为,即使是相同的网络,较小的图像大小会导致较小的网络容量,因此需要较弱的正则化;相反,较大的图像大小会导致更多的计算和更大的容量,因此更容易发生过拟合。为了验证我们的假设,我们从我们的搜索空间中抽取一个模型,在不同的图像大小和数据增强下进行训练(表5)。当图像大小较小时,使用较弱的增强时准确率最好;而对于较大的图像,使用更强的增强效果更好。这个观点促使我们在训练过程中随着图像大小的变化自适应地调整正则化,从而提出了我们的进阶学习方法。
精读
 本文探讨了图像大小对训练效率的影响,并提出了自适应调整正则化的策略。研究发现,不同图像大小需要不同强度的正则化:较小的图像大小需要较弱的正则化,而较大的图像大小则需要更强的正则化。为了验证这一假设,作者通过训练模型并调整图像大小和数据增强策略,发现小图像适合弱增强,大图像则需强增强。基于此,提出了进阶学习方法,旨在通过根据图像大小自适应地调整正则化来提高训练效果和准确性。
本文探讨了图像大小对训练效率的影响,并提出了自适应调整正则化的策略。研究发现,不同图像大小需要不同强度的正则化:较小的图像大小需要较弱的正则化,而较大的图像大小则需要更强的正则化。为了验证这一假设,作者通过训练模型并调整图像大小和数据增强策略,发现小图像适合弱增强,大图像则需强增强。基于此,提出了进阶学习方法,旨在通过根据图像大小自适应地调整正则化来提高训练效果和准确性。
4.2 Progressive Learning with adaptive Regularization—自适应正则化的渐进学习
翻译
图4展示了我们改进的渐进学习过程:在训练的早期阶段,我们使用较小的图像和弱正则化来训练网络,这样网络可以更快速地学习简单的表示。然后,我们逐渐增加图像大小,同时通过增加更强的正则化使学习变得更困难。我们的方法基于(Howard, 2018)中渐进变化图像大小的思想,但在此基础上我们还自适应地调整正则化。
具体来说,假设整个训练过程有N个步骤,目标图像大小为Se,正则化幅度为Φe = {φek},其中k代表正则化类型,如dropout率或mixup比例值。我们将训练分为M个阶段:对于每个阶段1 ≤ i ≤ M,模型使用图像大小Si和正则化幅度Φi = {φk i}进行训练。最后一个阶段M将使用目标图像大小Se和正则化Φe。为简单起见,我们启发式地选择初始图像大小S0和正则化Φ0,然后使用线性插值来确定每个阶段的值。算法1总结了这一过程。在每个阶段开始时,网络将继承上一个阶段的所有权重。与transformer不同,后者的权重(例如位置嵌入)可能依赖于输入长度,而ConvNet的权重与图像大小无关,因此可以轻松继承。
我们改进的渐进学习方法通常与现有的正则化兼容。为了简化,本文主要研究以下三种类型的正则化:
-
Dropout(Srivastava et al., 2014):一种网络级别的正则化,通过随机丢弃通道来减少协同适应。我们将调整dropout率γ。
-
RandAugment(Cubuk et al., 2020):一种每图像的数据增强,具有可调节的幅度。
-
Mixup(Zhang et al., 2018):一种跨图像的数据增强。给定两张图像及其标签(xi, yi)和(xj, yj),通过mixup比例λ将它们组合:x ̃i = λxj + (1 − λ)xi 和 y ̃i = λyj + (1 − λ)yi。在训练过程中,我们将调整mixup比例λ。
精读
本文介绍了一种改进的渐进学习方法,该方法在训练过程中逐步增加图像大小并自适应地调整正则化强度。具体而言,训练分为多个阶段,每个阶段使用不同的图像大小和正则化强度。最初使用较小的图像和较弱的正则化,让网络快速学习简单特征;随着训练进展,图像大小逐渐增大,同时增强正则化,使学习变得更困难。该方法与现有的正则化技术兼容,并且能够自适应调整正则化强度。
本文主要研究三种正则化技术:
-
Dropout:通过随机丢弃网络中的通道来减少协同适应。
-
RandAugment:一种每图像的数据增强方法,具有可调节的增强幅度。
-
Mixup:一种跨图像的数据增强方法,通过加权组合两张图像及其标签来创建新的样本。
这种渐进学习方法通过自适应调整正则化与图像大小的关系,提高了训练效率和模型表现。
五、Main Results—主要结果
5.1 ImageNet ILSVRC2012
翻译
设置:
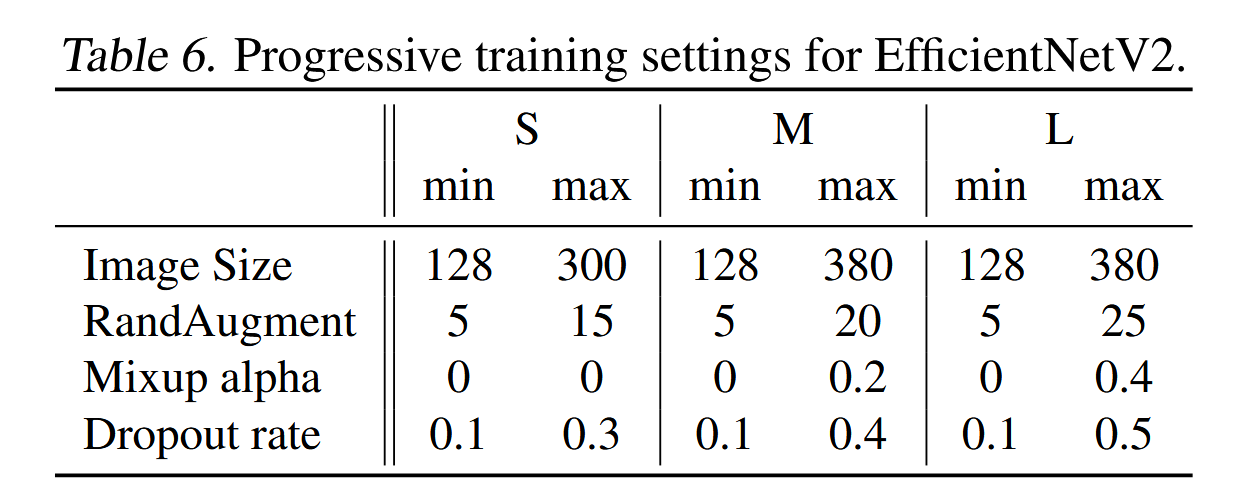
ImageNet ILSVRC2012(Russakovsky等,2015)包含大约128万张训练图像和50,000张验证图像,涵盖1000个类别。在架构搜索或超参数调优过程中,我们从训练集保留了25,000张图像(约2%)作为minival,用于准确性评估。同时,我们也使用minival来执行早期停止。我们的ImageNet训练设置主要参考EfficientNets(Tan & Le,2019a):使用RMSProp优化器,衰减系数0.9,动量0.9;批归一化动量为0.99;权重衰减为1e-5。每个模型训练350个epochs,总批量大小为4096。学习率从0逐步加热到0.256,然后每2.4个epochs衰减0.97。我们使用指数移动平均法,衰减率为0.9999,应用RandAugment(Cubuk等,2020),Mixup(Zhang等,2018),Dropout(Srivastava等,2014)和随机深度(Huang等,2016),生存概率为0.8。在渐进学习中,我们将训练过程分为四个阶段,每个阶段约87个epochs:初期阶段使用较小的图像尺寸和弱正则化,而后期阶段使用较大的图像尺寸和更强的正则化,具体步骤如算法1所示。表6显示了图像尺寸和正则化的最小(第一阶段)和最大(最后阶段)值。为了简便起见,所有模型都使用相同的最小尺寸和正则化值,但它们采用不同的最大值,因为较大的模型通常需要更多的正则化来对抗过拟合。根据(Touvron等,2020),我们训练时的最大图像尺寸比推理时小约20%,但在训练后我们不再微调任何层。
结果:
如表7所示,我们的EfficientNetV2模型在ImageNet上的训练速度明显更快,且在准确性和参数效率上超越了之前的ConvNets和Transformers。特别是,我们的EfficientNetV2-M在训练时速度是EfficientNet-B7的11倍,而准确性相当,使用相同的计算资源。此外,EfficientNetV2模型在准确性和推理速度上都显著超越了所有近期的RegNet和ResNeSt。图1进一步展示了训练速度和参数效率的对比。值得注意的是,这种加速是渐进训练和更好网络的结合结果,我们将在消融研究中探讨它们各自的影响。
近年来,视觉Transformer在ImageNet上的准确性和训练速度上表现出色。然而,我们的研究表明,经过精心设计的ConvNets,配合改进的训练方法,仍然可以在准确性和训练效率上大大超越视觉Transformers。特别是,我们的EfficientNetV2-L达到了85.7%的top-1准确率,超越了ViT-L/16(21k),这个更大的transformer模型是基于更大的ImageNet21k数据集进行预训练的。这里,ViTs在ImageNet ILSVRC2012上的调优效果不佳;DeiTs使用与ViTs相同的架构,但通过增加更多正则化来获得更好的结果。
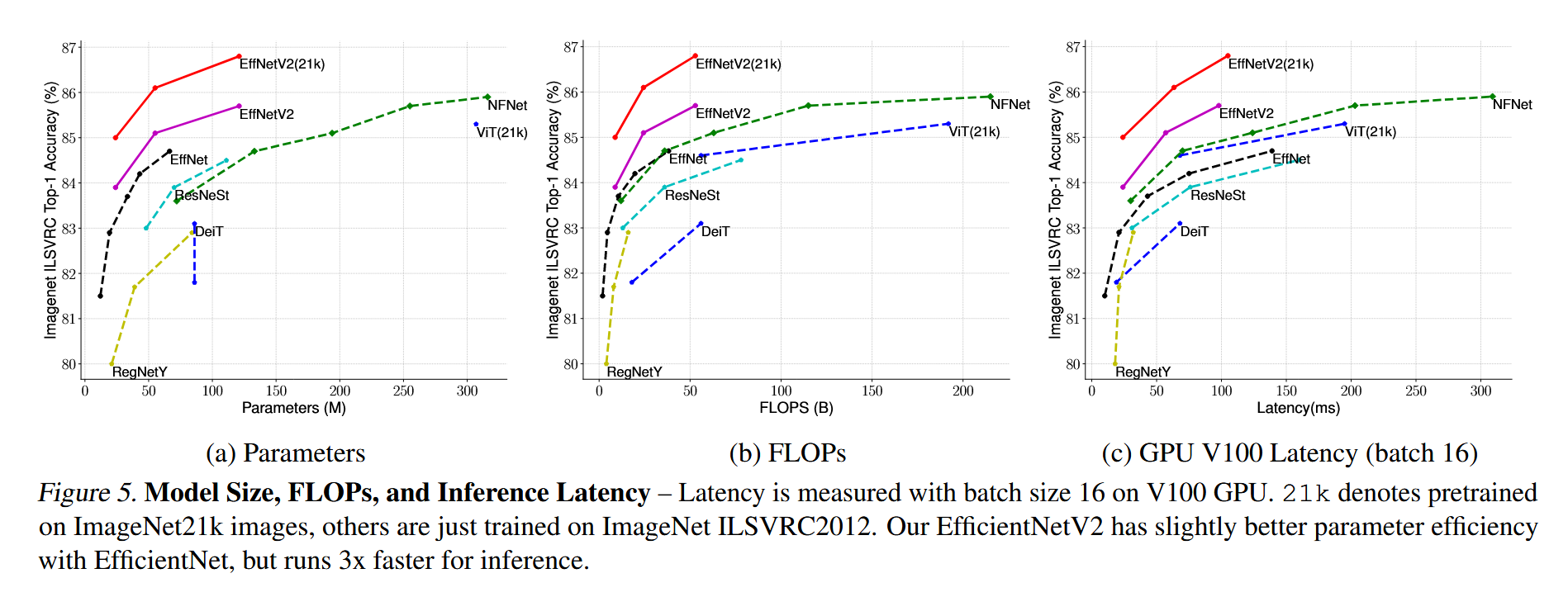
尽管我们的EfficientNetV2模型是针对训练进行了优化,但它们在推理上也表现出色,因为训练速度通常与推理速度相关。图5展示了基于表7的模型大小、FLOPs和推理延迟。由于延迟通常依赖于硬件和软件,这里我们使用相同的PyTorch Image Models代码库(Wightman,2021),并在相同的机器上以批量大小16运行所有模型。总体而言,我们的模型在参数/FLOPs效率上略优于EfficientNets,但推理延迟比EfficientNets快最多3倍。与专门为GPU优化的ResNeSt相比,我们的EfficientNetV2-M在推理速度上快2.8倍,同时准确率提高了0.6%。
精读
优化器和学习率设置:
-
优化器:使用 RMSProp 优化器,衰减率为 0.9,动量为 0.9。
-
批归一化动量: 0.99。
-
权重衰减: 1e-5。
-
学习率:首先从 0 增加到 0.256,然后每 2.4 个epochs衰减 0.97。
训练过程:
-
每个模型训练 350 epochs,总批量大小为 4096。
-
使用 指数移动平均法,衰减率为 0.9999。
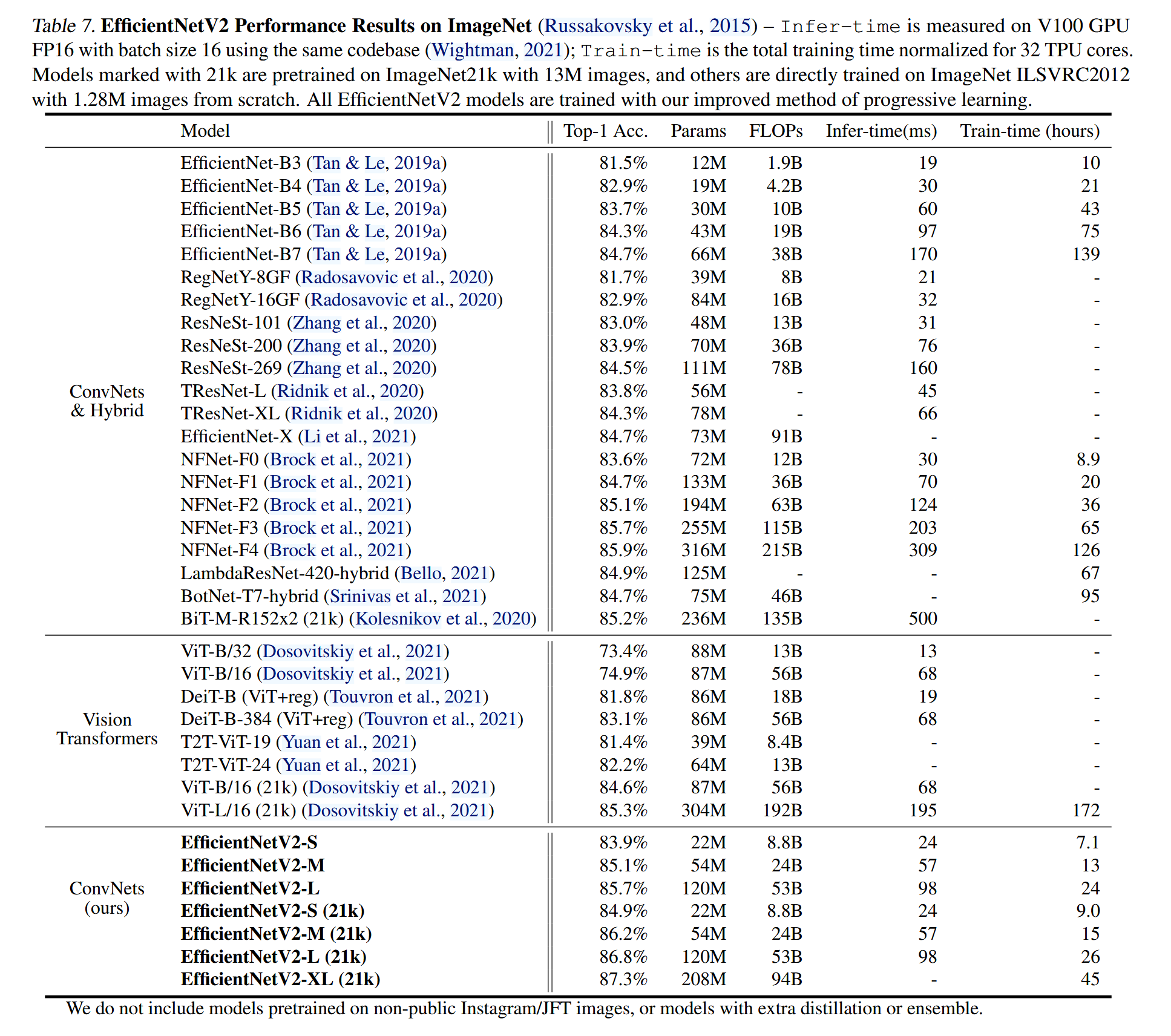
训练速度和准确性:EfficientNetV2 模型比以前的 ConvNets 和 Transformers 在 ImageNet 上表现更好,尤其是 EfficientNetV2-M,在训练速度上比 EfficientNet-B7 快 11 倍,同时保持相似的准确性。
与其他模型对比:EfficientNetV2 在准确性和推理速度上优于最新的 RegNet 和 ResNeSt。
与 Vision Transformers(ViT)对比:EfficientNetV2-L 在 ImageNet 上超越了 ViT-L/16(21k),即使 ViT 在更大数据集上预训练。
推理性能:EfficientNetV2 在推理速度上比 EfficientNet 快最多 3 倍,比专门优化的 ResNeSt 快 2.8 倍,同时提高了准确性。
5.2 ImageNet21k
翻译
设置:ImageNet21k包含约1300万张训练图像,涵盖21,841个类别。原始的ImageNet21k没有训练/验证集划分,因此我们随机挑选了10万张图像作为验证集,其余作为训练集。我们在训练设置上大体沿用ImageNet ILSVRC2012的设置,但做了一些调整:
-
将训练周期调整为60或30,以减少训练时间,并使用余弦学习率衰减,无需额外调参;
-
由于每张图像有多个标签,计算softmax损失前,我们将标签归一化使其和为1。经过ImageNet21k预训练后,每个模型在ILSVRC2012上进行了15轮的微调。
结果:表7展示了性能对比,标记为21k的模型在ImageNet21k上预训练后,再在ImageNet ILSVRC2012上微调。与最近的ViT-L/16(21k)相比,我们的EfficientNetV2L(21k)在top-1准确率上提高了1.5%(85.3% vs. 86.8%),同时参数量减少了2.5倍,FLOPs减少了3.6倍,训练和推理速度提高了6到7倍。
一些重要观察:
-
数据量扩大比模型扩大更有效:当top-1准确率超过85%时,单纯增加模型规模很难进一步提高准确率,因为过拟合问题严重。但通过额外的ImageNet21k预训练,准确率显著提高。这也与之前的研究发现相符。
-
ImageNet21k预训练非常高效:尽管ImageNet21k的数据量是原数据集的10倍,我们的训练方法使得EfficientNetV2的预训练只用了两天时间(使用32个TPU核心),比ViT(需要几周时间)更高效。这比在ImageNet上训练更大的模型要更有效。我们建议未来的大规模模型研究可以默认使用公开的ImageNet21k数据集。
精读
该研究对EfficientNetV2模型进行了ImageNet21k数据集的预训练,并在ILSVRC2012数据集上进行了微调。主要设置包括调整训练周期至60或30,并使用余弦学习率衰减,同时对多标签数据进行了归一化。研究发现,使用ImageNet21k进行预训练可以显著提升模型的准确率和训练效率。
主要结果:
-
性能提升:与ViT-L/16(21k)相比,EfficientNetV2L(21k)在top-1准确率上提高了1.5%,且参数量和FLOPs减少了2.5倍和3.6倍,训练和推理速度快了6到7倍。
-
数据量比模型规模更有效:扩大数据集比单纯增大模型规模在高准确率时更有效。额外的ImageNet21k预训练可以显著提高准确率,克服过拟合问题。
-
预训练效率:尽管ImageNet21k数据量是原数据集的10倍,但该方法使EfficientNetV2的预训练仅用了两天时间,远比ViT高效。建议未来使用ImageNet21k作为默认数据集进行大规模模型研究。
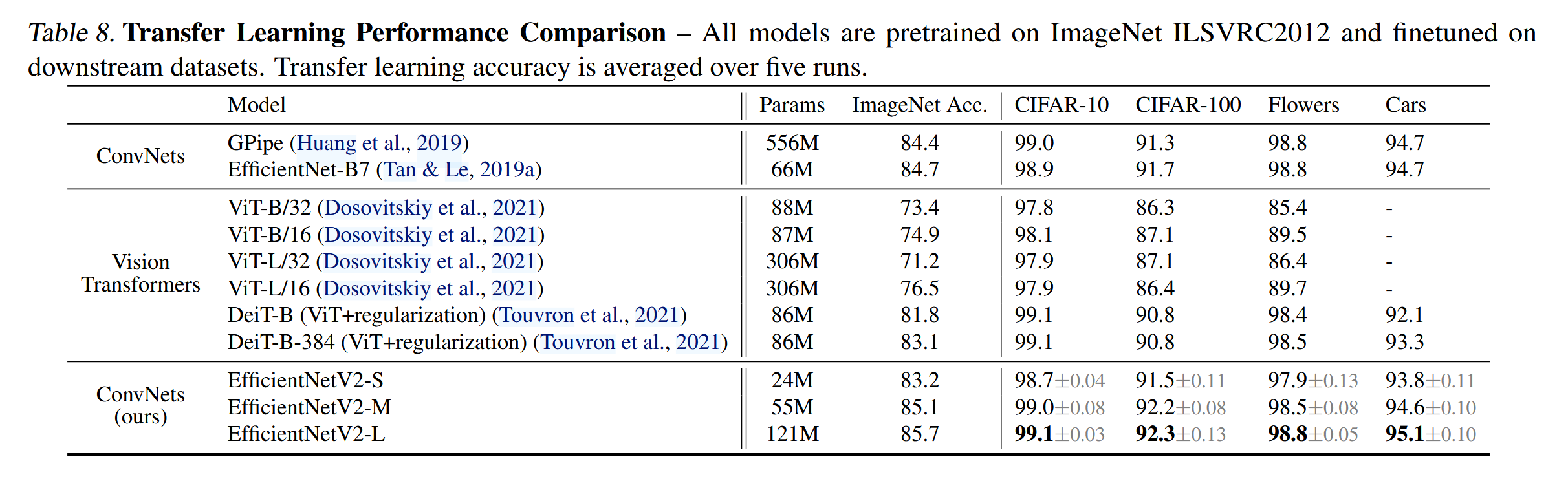
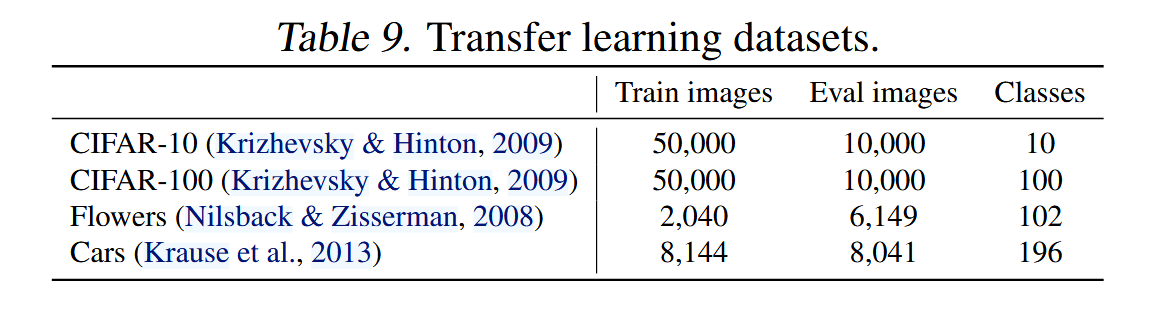
5.3 Transfer Learning Datasets—迁移学习数据集
翻译
设置:我们在四个迁移学习数据集上评估了我们的模型:CIFAR-10、CIFAR-100、Flowers 和 Cars。表9包含了这些数据集的统计信息。为了公平比较,本实验使用的是在ImageNet ILSVRC2012上训练的检查点,未使用ImageNet21k的图像。我们的微调设置与ImageNet训练大体相同,只有一些类似于(Dosovitskiy et al., 2021; Touvron et al., 2021)的修改:使用较小的批量大小(512),较小的初始学习率(0.001)和余弦衰减。对于所有数据集,每个模型训练10,000步。由于每个模型微调步骤非常少,我们禁用了权重衰减,并使用了简单的cutout数据增强。
结果:表8对比了迁移学习的性能。总体而言,我们的模型在所有这些数据集上均优于以前的ConvNets和Vision Transformers,有时甚至有显著的提升:例如,在CIFAR-100上,EfficientNetV2-L比之前的GPipe/EfficientNets提高了0.6%的准确率,比之前的ViT/DeiT模型提高了1.5%的准确率。这些结果表明,我们的模型在超越ImageNet的应用中也具有很好的泛化能力。
精读
设置:在四个迁移学习数据集(CIFAR-10、CIFAR-100、Flowers 和 Cars)上评估模型,使用在ImageNet ILSVRC2012上训练的检查点。为了公平比较,未使用ImageNet21k图像。微调设置包括较小的批量大小(512)和较小的初始学习率(0.001),并且禁用权重衰减,使用简单的cutout数据增强。
结果:我们的模型在所有迁移学习数据集上表现优于以前的ConvNets和Vision Transformers,特别是在CIFAR-100上,EfficientNetV2-L比以前的GPipe/EfficientNets和ViT/DeiT模型提高了准确率,表现出良好的泛化能力。
六、Ablation Studies—消融研究
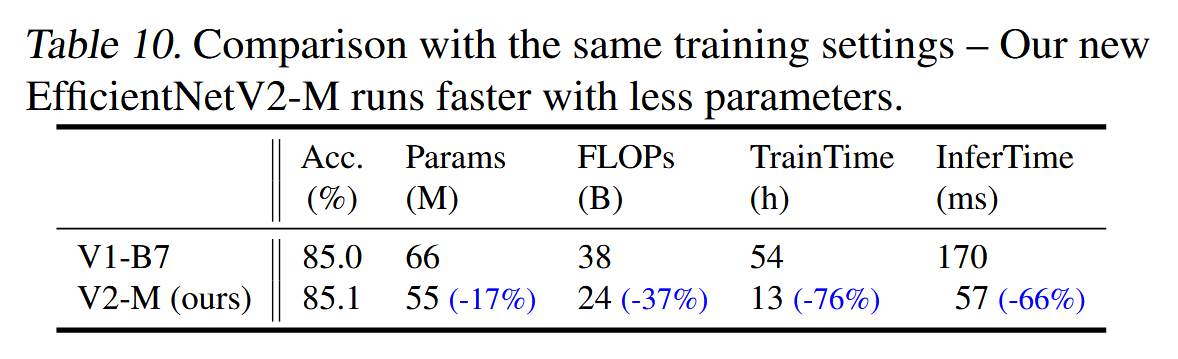
6.1 Comparison to EfficientNet—与EfficientNet的比较
翻译
在本节中,我们将对比EfficientNetV2(简称V2)和EfficientNets(Tan & Le, 2019a)(简称V1)在相同训练和推理设置下的表现。
相同训练下的表现:表10展示了使用相同渐进学习设置下的性能对比。当我们对EfficientNet应用相同的渐进学习时,它的训练速度(从139小时降至54小时)和准确率(从84.7%提高到85.0%)相比原论文(Tan & Le, 2019a)有所改善。然而,如表10所示,我们的EfficientNetV2模型仍然大幅度优于EfficientNet:EfficientNetV2M减少了17%的参数和37%的FLOPs,同时在训练速度上比EfficientNet-B7快4.1倍,在推理速度上快3.1倍。由于我们在这里使用相同的训练设置,我们将这些提升归因于EfficientNetV2架构。
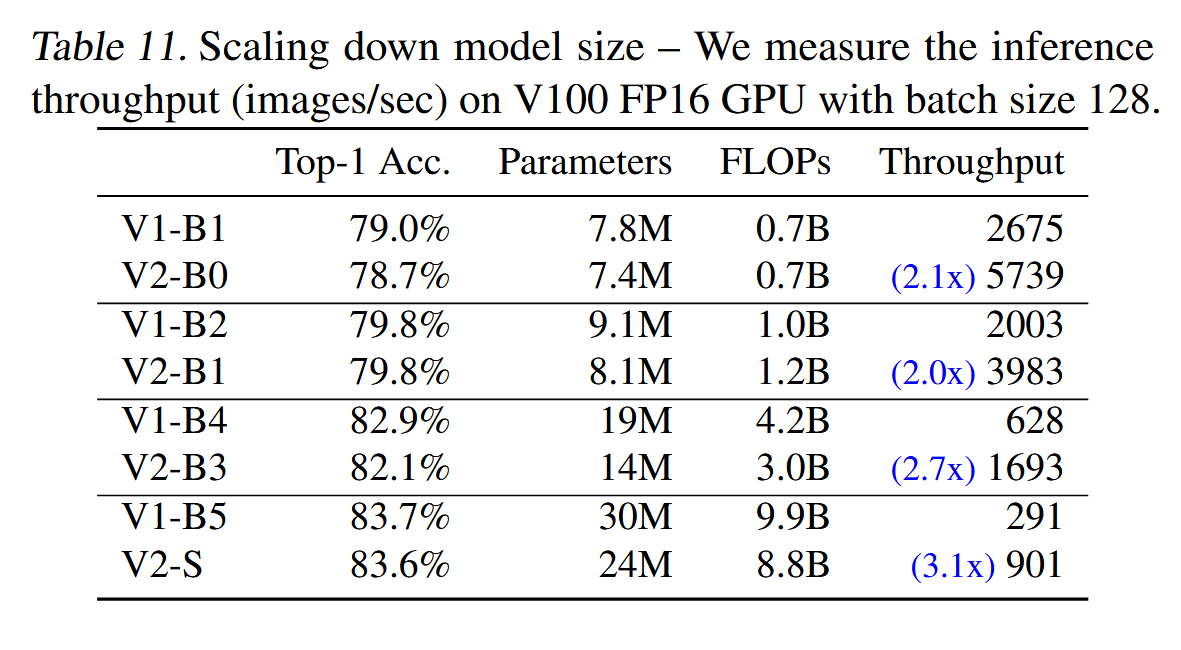
缩小规模:前几节主要集中于大规模模型。在这里,我们通过使用EfficientNet复合缩放来比较小型模型。为了方便比较,所有模型均未使用渐进学习训练。与小型EfficientNet(V1)相比,我们的新EfficientNetV2(V2)模型在保持相似的参数效率的同时,通常更快。
精读
本节对比了EfficientNetV2(V2)和EfficientNet(V1)在相同训练和推理设置下的表现。使用相同的渐进学习设置,EfficientNetV2在训练速度和准确率上都优于EfficientNet,尤其是在训练速度上提高了4.1倍,推理速度提高了3.1倍,同时减少了17%的参数和37%的FLOPs。对于小型模型,EfficientNetV2在不使用渐进学习的情况下,相较于EfficientNet,表现出更快的训练速度和相似的参数效率。
6.2 Progressive Learning for Different Networks—针对不同网络的渐进式学习
翻译
我们对不同网络的渐进学习性能进行了消融实验。表12显示了在相同的ResNet和EfficientNet模型下,我们的渐进训练与基准训练的性能对比。这里,基准ResNet的准确率高于原论文(He等人,2016),因为它们采用了我们的改进训练设置(见第5节),使用了更多的训练轮次和更好的优化器。我们还将ResNet的图像尺寸从224增加到380,以进一步提升网络容量和准确率。如表12所示,我们的渐进学习通常能减少训练时间,同时提高所有不同网络的准确率。毫不奇怪,当默认图像尺寸非常小,例如ResNet50(224)使用224x224的尺寸时,训练速度的提升有限(提高1.4倍);然而,当默认图像尺寸较大且模型更复杂时,我们的方法在准确性和训练效率上都取得了更大的提升:对于ResNet152(380),我们的方法使训练速度提高了2.1倍,准确率略有提高;对于EfficientNet-B4,我们的方法使训练速度提高了2.2倍。
精读
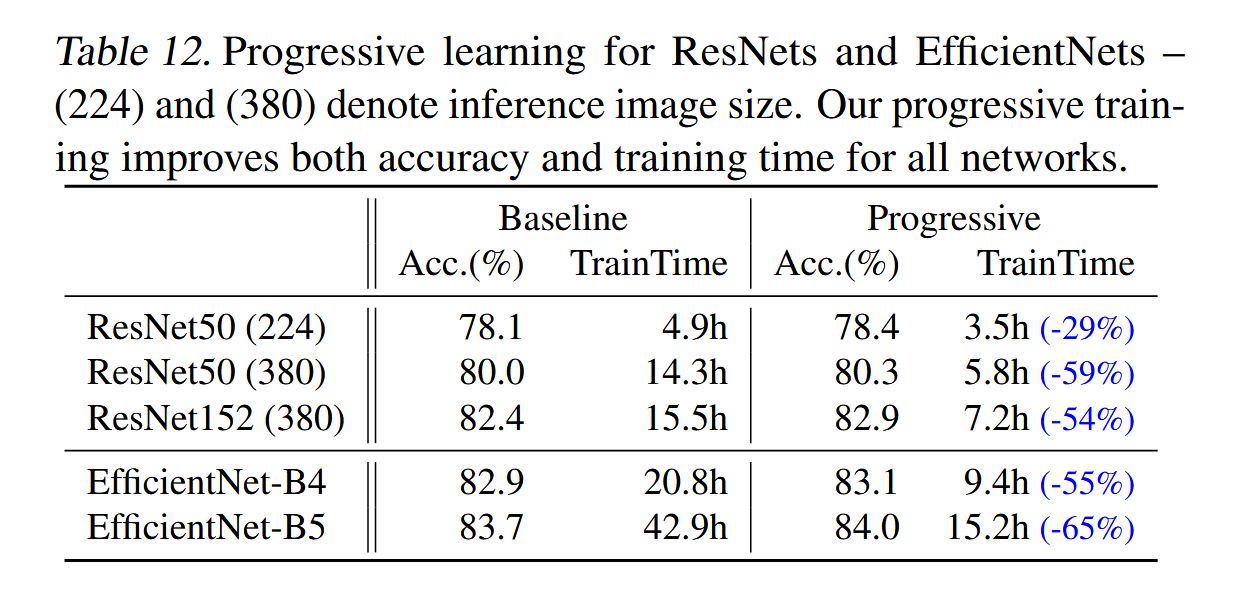
表12主要比较了使用渐进训练(Progressive Learning)与基准训练(Baseline Training)在不同网络(如ResNet和EfficientNet)上的性能表现
渐进训练大大缩短了训练时间。例如,对于ResNet152(380),训练速度提高了2.1倍;对于EfficientNet-B4,训练速度提高了2.2倍。
6.3 Importance of Adaptive Regularization—自适应正则化的重要性
翻译
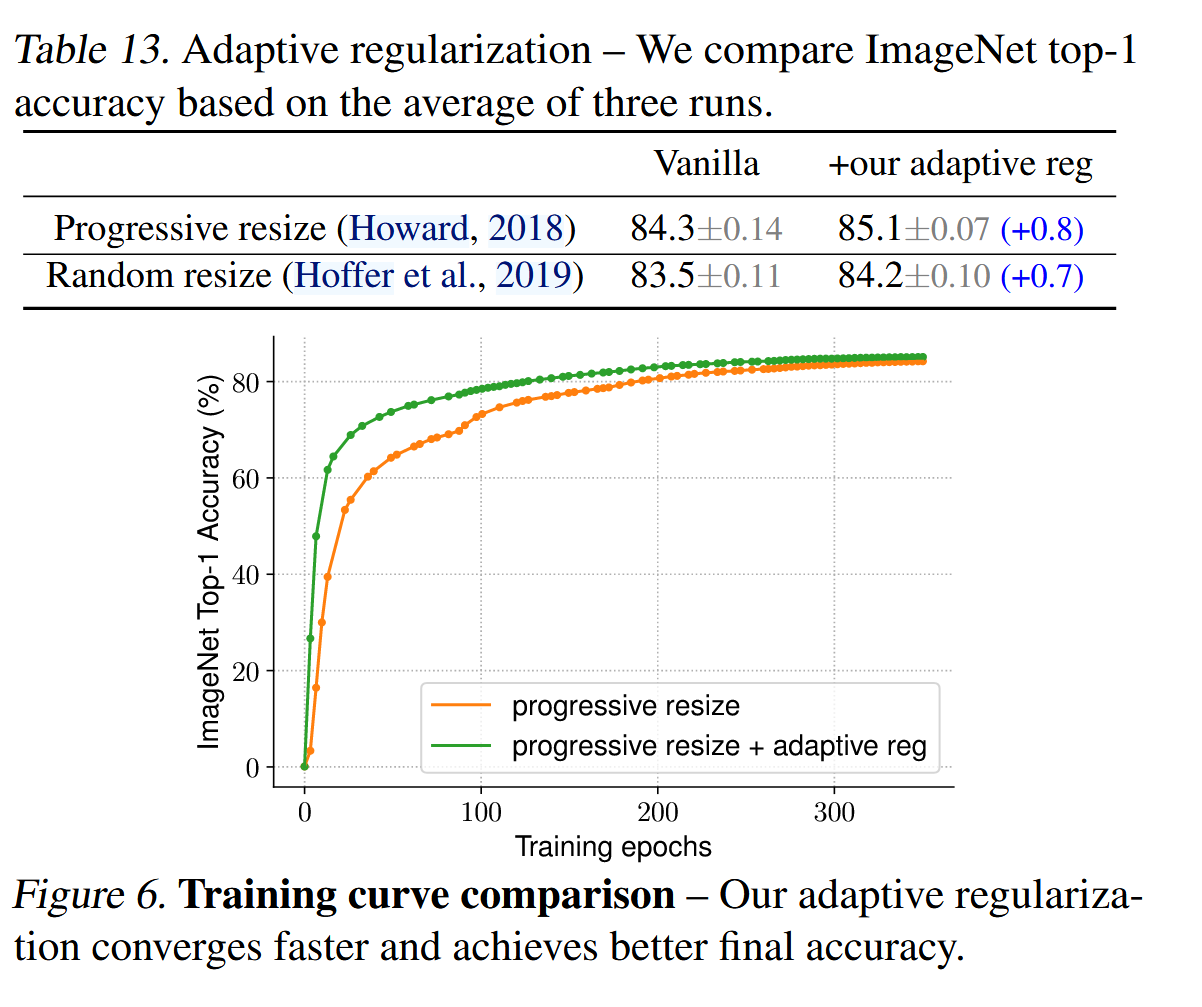
我们训练方法的一个关键见解是自适应正则化,即根据图像尺寸动态调整正则化。本文选择了一个简单的渐进式方法,因为它简单易行,但它也是一种通用方法,可以与其他方法结合使用。表13研究了我们的自适应正则化在两种训练设置下的表现:一种是从小到大逐渐增加图像尺寸(Howard, 2018),另一种是为每个批次随机采样不同的图像尺寸(Hoffer et al., 2019)。由于TPU需要为每个新尺寸重新编译计算图,这里我们每八个epoch随机采样一次图像尺寸,而不是每个批次都采样一次。与使用相同正则化的渐进式或随机调整尺寸的传统方法相比,我们的自适应正则化提高了0.7%的准确率。图6进一步比较了渐进式方法的训练曲线。我们的自适应正则化在训练初期对小尺寸图像使用较小的正则化,使得模型能够更快收敛,并最终获得更好的准确性。
精读
本文介绍了一种自适应正则化方法,该方法根据图像尺寸动态调整正则化。在渐进式训练中,图像尺寸逐步增大,同时正则化强度逐渐增加。研究显示,采用自适应正则化相比于传统的渐进式或随机调整图像尺寸方法,提高了0.7%的准确率。自适应正则化通过在训练初期对小图像使用较小的正则化,使得模型更快收敛,并在最终达到更高的准确度。
七、Conclusion—结论
翻译
本文介绍了EfficientNetV2,一个新的更小、更快的图像识别神经网络系列。通过训练感知的神经架构搜索(NAS)和模型缩放优化,EfficientNetV2显著超越了之前的模型,同时在参数上更加高效且训练速度更快。为了进一步加速训练,我们提出了一种改进的渐进式学习方法,在训练过程中同时增加图像尺寸和正则化。大量实验表明,EfficientNetV2在ImageNet、CIFAR、Flowers和Cars等数据集上取得了优秀的结果。与EfficientNet及更近期的工作相比,EfficientNetV2训练速度提高最多可达11倍,同时参数量最多减小6.8倍。
精读
EfficientNetV2简介: EfficientNetV2是一个新的神经网络系列,专为图像识别任务设计,具有更小、更快的特点。
优化方法: 使用训练感知的神经架构搜索(NAS)和模型缩放,显著提高了模型的效率和训练速度。
渐进式学习改进: 提出了一种改进的渐进式学习方法,通过增加图像尺寸和正则化来加速训练。
实验结果: 在ImageNet、CIFAR、Flowers和Cars等数据集上,EfficientNetV2表现出色。
训练速度与参数效率: 相比于EfficientNet和其他近期的工作,EfficientNetV2训练速度提高最多可达11倍,且参数量最多减小6.8倍。


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









