








前言
上一篇给大家讲解了MobileNetV2版本,这篇是MobileNetV3也是MobileNet系列的最终章,建议大家按V1,V2,V3的顺序来看,好了,开整!
MobileNetV3 版本主要是在v2的基础上做的改进,主要体现在 1.引入 SE(Squeeze-and-Excitation)模块:增强通道注意力机制 2.激活函数优化:ReLU6 → h-swish,提高计算效率 3. 改进倒残差块结构:通过 NAS 选择更优的扩展因子和层数 4. 轻量化 Head 设计:使用全局平均池化(GAP)+ 轻量化 FC 层 5. 提供 Large 和 Small 版本:适配不同计算需求
注:NAS(Neural Architecture Search,神经网络架构搜索)是一种自动化设计神经网络结构的方法,利用搜索算法(如强化学习或进化算法)来找到最优的网络结构,而不是依赖人工经验设计。
论文地址:[1905.02244] Searching for MobileNetV3
图像分类前景回顾
LeNet 论文精读 | 深度解析+PyTorch代码复现(上)_yann lecun卷积网络的奠定文章-CSDN博客
LeNet 论文精读 | 深度解析+PyTorch代码复现(下)_lenet搭建与mnist训练-CSDN博客
AlexNet 论文精读 | 深度解析+PyTorch代码复现 (上)-CSDN博客
AlexNet 论文精读 | 深度解析+PyTorch代码复现 (下)-CSDN博客
VGG论文精读 | 翻译+学习笔记+PyTorch代码复现_vgg数据增强-CSDN博客
GoogleNet论文精读 | 翻译+学习笔记+PyTorch代码复现-CSDN博客
ResNet论文精读:翻译+学习笔记+Pytorch代码复现-CSDN博客
MobileNetV1论文精读(八):翻译+学习笔记+pytorch代码复现-CSDN博客
MobileNetV2论文精读(九):翻译+学习笔记+pytorch代码复现-CSDN博客
Abstract—摘要
翻译
我们展示了下一代 MobileNet,基于一系列互补的搜索技术和一种新颖的架构设计。MobileNetV3 通过结合硬件感知网络架构搜索(NAS)和 NetAdapt 算法进行调优,专门针对手机 CPU 进行了优化,随后通过新的架构进展进一步提升。本论文开始探索自动化搜索算法和网络设计如何协同工作,利用互补的方法共同推动整体技术水平的提升。通过这一过程,我们创建了两个新的 MobileNet 模型:MobileNetV3-Large 和 MobileNetV3-Small,分别面向高资源和低资源的应用场景。这些模型随后被调整并应用于目标检测和语义分割任务。在语义分割(或任何稠密像素预测)任务中,我们提出了一种新的高效分割解码器:Lite Reduced Atrous Spatial Pyramid Pooling(LR-ASPP)。我们在移动端分类、检测和分割任务中取得了新的最先进结果。与 MobileNetV2 相比,MobileNetV3-Large 在 ImageNet 分类任务上的准确率提高了 3.2%,同时延迟降低了 20%。MobileNetV3-Small 在相似延迟下,比 MobileNetV2 提高了 6.6%的准确率。在 COCO 检测任务中,MobileNetV3-Large 比 MobileNetV2 快 25%以上,且准确率基本相当。MobileNetV3-Large 的 LRASPP 在 Cityscapes 分割任务中,比 MobileNetV2 的 R-ASPP 快 34%,而且准确率相似。
精读
主要工作
-
优化模型架构以适应移动设备的计算资源限制。结合硬件感知的 NAS 和 NetAdapt 算法,自动化地搜索最适合移动设备的网络架构。
-
两种不同版本的MobileNetV3
-
MobileNetV3-Large:为高资源需求的任务(如图像分类)设计,提供更高的准确度。
-
MobileNetV3-Small:为低资源设备设计,优化了延迟与计算效率
-
-
提升语义分割任务的效率,提出了 LR-ASPP,减少计算开销。
-
MobileNetV3 在多个任务(如图像分类、目标检测和语义分割)中取得了显著的提升。该模型适用于需要兼顾高效性和精度的 移动设备 和 嵌入式系统,为低资源环境下的深度学习任务提供了一个理想的解决方案。
一、Introduction—简介
翻译
高效的神经网络在移动应用中变得越来越普遍,为完全新的设备端体验提供了可能。它们也是个人隐私的关键推动力,使得用户能够在不将数据发送到服务器进行处理的情况下,享受神经网络带来的好处。神经网络效率的提升不仅通过更高的准确度和更低的延迟改善了用户体验,还通过减少功耗帮助延长电池寿命。本文描述了我们为开发 MobileNetV3 Large 和 Small 模型所采取的方法,以提供下一代高准确度、高效能的神经网络模型,推动设备端计算机视觉的发展。这些新网络推动了技术的前沿,并展示了如何将自动化搜索与新颖的架构创新结合,构建有效的模型。本文的目标是开发最佳的移动计算机视觉架构,优化移动设备上的准确度-延迟平衡。为此,我们引入了以下几个关键点:(1)互补的搜索技术,(2)适用于移动端的新型高效非线性激活函数,(3)新的高效网络设计,(4)新的高效分割解码器。我们进行了全面的实验,展示了每项技术的有效性和价值,评估了广泛的使用案例和移动设备。本文的结构如下:第2节讨论相关工作;第3节回顾了用于移动模型的高效构建模块;第4节回顾了架构搜索,以及 MnasNet 和 NetAdapt 算法的互补性;第5节描述了通过联合搜索优化模型效率的创新架构设计;第6节呈现了分类、检测和分割任务的广泛实验,以展示技术的有效性并理解不同元素的贡献;第7节总结了结论和未来的工作。
精读
主要贡献
提出 MobileNetV3 Large 和 Small
方法
自动化搜索 + 手工优化:结合 MnasNet 和 NetAdapt 两种搜索方法,优化网络架构。
优化激活函数:设计适用于移动端的高效非线性激活函数,提高模型推理速度。
高效网络设计:调整 MobileNetV2 结构,使计算更轻量化,减少推理时的计算需求。
轻量级分割解码器(LR-ASPP):改进空洞卷积方法,使得语义分割在移动端更高效。
二、Related Work—相关工作
翻译
近年来,设计深度神经网络架构以在准确性和效率之间实现最佳权衡已成为一个活跃的研究领域。新颖的手工设计结构和算法化的神经架构搜索在推动该领域发展方面都发挥了重要作用。
SqueezeNet [22] 广泛使用 1×1 卷积,并采用 squeeze 和 expand 模块,主要侧重于减少参数数量。更近期的研究重点从减少参数数量转向减少计算量(MAdds)和实际测量的推理延迟。MobileNetV1 [19] 采用深度可分离卷积(Depthwise Separable Convolution)来显著提高计算效率。MobileNetV2 [39] 进一步扩展了这一点,引入了具有倒残差(Inverted Residuals)和线性瓶颈(Linear Bottlenecks)的高效计算单元。ShuffleNet [49] 利用组卷积(Group Convolution)和通道洗牌(Channel Shuffle)操作进一步减少计算量。CondenseNet [21] 在训练阶段学习组卷积,以在层之间保持有效的密集连接,从而实现特征复用。ShiftNet [46] 提出了交错点卷积(Point-wise Convolutions)的位移操作(Shift Operation),用于替换计算昂贵的空间卷积(Spatial Convolutions)。
为了自动化架构设计过程,强化学习(Reinforcement Learning,RL)最早被用于搜索具有竞争力准确率的高效架构 [53, 54, 3, 27, 35]。一个完全可配置的搜索空间会呈指数级增长,导致难以处理。因此,早期的架构搜索主要关注单元级结构搜索,并在所有层中复用相同的单元。最近,研究 [43] 探索了一种块级的层次化搜索空间,允许网络在不同的分辨率块中采用不同的层结构。为了降低搜索的计算成本,可微分架构搜索(Differentiable Architecture Search)框架被应用于 [28, 5, 45],采用基于梯度的优化方法。
针对移动端受限平台的适配,研究 [48, 15, 12] 提出了更高效的自动化网络简化算法。量化(Quantization)[23, 25, 47, 41, 51, 52, 37] 也是提升网络效率的另一项重要补充方法,它通过降低计算精度来减少计算量。最后,知识蒸馏(Knowledge Distillation)[4, 17] 提供了一种额外的补充方法,通过大型“教师”网络(Teacher Network)指导训练小型高效的“学生”网络(Student Network),以获得精度较高的小型网络。
精读
移动端应用的前人技术:SqueezeNet、MobileNetV1、MobileNetV2、ShuffleNet、CondenseNet、ShiftNet
自动化架构搜索(NAS):强化学习(RL)、可微分架构搜索(Differentiable NAS)、移动平台适配、
辅助技术:量化(Quantization)、知识蒸馏(Knowledge Distillation)
注解:NAS就是让机器自己去尝试不同的网络结构,找到最适合的方案,省时省力。NetAdapt:用于对各个模块确定之后网络层的微调。
三、Efficient Mobile Building Blocks—高效移动端构建块
翻译
移动模型已经建立在越来越高效的构建模块之上。MobileNetV1 [19] 引入了深度可分离卷积,作为传统卷积层的高效替代。深度可分离卷积通过将空间滤波与特征生成机制分离,有效地将传统卷积分解。深度可分离卷积由两个独立的层组成:轻量级的深度卷积用于空间滤波,较重的 1x1 点卷积用于特征生成。
MobileNetV2 [39] 引入了线性瓶颈和倒残差结构,通过利用问题的低秩特性,使得层结构更加高效。该结构如图3所示,定义为一个 1x1 扩展卷积,接着是深度卷积和一个 1x1 投影层。如果输入和输出的通道数相同,则它们之间有一个残差连接。该结构在输入和输出端保持紧凑的表示,同时在内部扩展到更高维的特征空间,以增加非线性每通道转换的表达能力。
MnasNet [43] 在 MobileNetV2 结构的基础上,通过引入基于压缩和激励的轻量级注意力模块,进一步优化瓶颈结构。需要注意的是,压缩和激励模块的位置与[20]中提出的基于ResNet的模块不同。该模块被放置在深度卷积之后的扩展部分,以便在最大的表示上应用注意力,如图4所示。
对于 MobileNetV3,我们使用这些层的组合作为构建模块,以构建最有效的模型。同时,层也进行了升级,采用了修改后的 swish 非线性函数 [36, 13, 16]。压缩和激励以及 swish 非线性都使用 sigmoid,这在计算上可能低效,并且在固定点算术中保持准确性也具有挑战性,因此我们将其替换为硬 sigmoid [2, 11],具体内容在第5.2节中讨论。
精读
MobileNetV1:引入了深度可分离卷积
MobileNetV2:引入了线性瓶颈和倒残差结构
MnasNet:在 MobileNetV2 的基础上,加入了轻量级的压缩和激励模块(基于注意力机制)
MobileNetV3:结合了 MobileNetV1、V2 和 MnasNet 的结构创新。MobileNetV3 引入了改进的 Swish 非线性激活函数,改进传统的 sigmoid,以提高计算效率并保持准确性。
四、Network Search—网络搜索
NAS(网络架构搜索):NAS 就是自动化的方式来帮你找出最适合某个任务或硬件的平台的网络结构。它的目标是通过搜索不同的架构配置,找到能在给定资源下(比如计算能力、内存等)最有效的网络模型。你可以把它理解成让计算机自己去探索和设计神经网络的架构,而不是手动设计。
NetAdapt:NetAdapt 是一种算法,主要是用来调节每层网络的大小,也就是决定每一层需要多少个滤波器(通俗点讲就是网络中每一层要有多少个“特征探测器”)。它会根据硬件平台的限制(比如计算能力)来逐层调整,确保网络既能保持良好的性能,同时又不会消耗太多的计算资源。
4.1 Platform-Aware NAS for Block-wise Search—使用NAS感知平台进行逐块(Block-wise)搜索
翻译
与[43]类似,我们采用了一个平台感知的神经网络架构方法来寻找全局网络结构。由于我们使用相同的基于RNN的控制器和相同的分解层次搜索空间,因此我们在目标延迟约为80ms的情况下,对于大型移动模型得到了与[43]类似的结果。因此,我们直接将相同的MnasNet-A1 [43]作为我们的初始大型移动模型,然后在其基础上应用NetAdapt [48]和其他优化。然而,我们发现原始的奖励设计并没有针对小型移动模型进行优化。具体来说,它使用了一个多目标奖励ACC(m) × [LAT (m)/T AR]w来近似Pareto最优解,通过平衡模型准确性ACC(m)和延迟LAT(m),根据目标延迟T AR为每个模型m进行优化。我们观察到,对于小型模型,准确度随着延迟的变化更加剧烈;因此,我们需要一个更小的权重因子w = −0.15(而在[43]中的原始w = −0.07),以补偿不同延迟下准确度的较大变化。在这个新的权重因子w的增强下,我们从头开始进行新的架构搜索,找到初始种子模型,然后应用NetAdapt和其他优化,最终获得MobileNetV3-Small模型。
精读
MnasNet-A1作为初始的网络模型,但是原始模型发现对小型移动模型并没有效果,通过参数参数调优,把原来w = −0.07,改为更小的权重因子w = −0.15
4.2 NetAdapt for Layer-wise Search—使用NetAdapt 进行 Layerwise 搜索
翻译
我们在架构搜索中使用的第二种技术是NetAdapt [48]。这种方法与平台感知NAS互为补充:它允许以顺序方式微调各个层,而不是尝试推测粗略的全局架构。我们可以参考原论文获取详细信息。简而言之,该技术的流程如下:
-
从平台感知NAS找到的种子网络架构开始。
-
每一步: (a) 生成一组新的提案。每个提案代表一个架构修改,它比上一步的架构减少至少δ的延迟。 (b) 对于每个提案,我们使用上一步的预训练模型,并填充新的提案架构,适当地截断并随机初始化缺失的权重。微调每个提案T步,以获得准确度的粗略估计。 (c) 根据某些度量标准选择最佳提案。
-
重复上述步骤,直到达到目标延迟。在[48]中,度量标准是最小化准确度变化。我们修改了这个算法,最小化延迟变化与准确度变化的比率。也就是说,对于每一步生成的所有提案,我们选择一个最大化:∆Acc / |∆latency| 的提案,其中∆latency满足2(a)中的约束。其直觉是,由于我们的提案是离散的,我们更倾向于选择最大化折中曲线斜率的提案。这个过程一直重复,直到延迟达到目标,然后我们从头开始重新训练新的架构。
我们使用与[48]中用于MobileNetV2相同的提案生成器。具体来说,我们允许以下两种类型的提案:
-
减小任何扩展层的大小;
-
减少所有共享相同瓶颈大小的块中的瓶颈,以保持残差连接。
在我们的实验中,我们使用了T = 10000,发现虽然这增加了提案初步微调的准确度,但在从头开始训练时,它不会改变最终准确度。我们设置δ = 0.01|L|,其中L是种子模型的延迟。
精读
主要介绍了NetAdapt技术在神经网络架构优化中的应用。该方法与平台感知NAS相结合,能够逐步优化架构的每一层。具体过程包括:
-
从平台感知NAS得到初始网络架构。
-
为每个提案生成新的架构修改,确保能够减少延迟,并进行微调。
-
选择最佳提案,并继续迭代直到达到目标延迟。
-
最后,从头训练优化后的架构。
与传统方法不同,本文通过修改优化标准,选择那些在延迟变化与准确度变化之间最大化比率的提案,从而提升了模型的性能。
五、Network Improvements—网络改进
5.1 Redesigning Expensive Layers—重新设计昂贵的层
翻译
一旦通过架构搜索找到模型,我们观察到一些最后的层以及一些较早的层比其他层更耗时。我们提出了一些修改架构的方法,以在保持准确性的同时减少这些慢层的延迟。这些修改超出了当前搜索空间的范围。第一个修改重新设计了网络最后几层的交互方式,以更高效地生成最终特征。目前基于MobileNetV2倒残差结构及其变体的模型,使用1x1卷积作为最后一层来扩展到更高维度的特征空间。这一层对于获得丰富的特征用于预测至关重要。然而,这也带来了额外的延迟。为了减少延迟并保持高维特征,我们将这一层移到最后的平均池化层之后。现在,这一组特征是在1x1空间分辨率下计算,而不是7x7空间分辨率下计算。这个设计选择的结果是,特征计算的代价在计算和延迟上几乎是免费的。一旦解决了这个特征生成层的成本,之前的瓶颈投影层就不再需要来减少计算。这一观察使我们能够移除之前瓶颈层中的投影和过滤层,进一步减少计算复杂度。原始和优化后的最后阶段可以在图5中看到。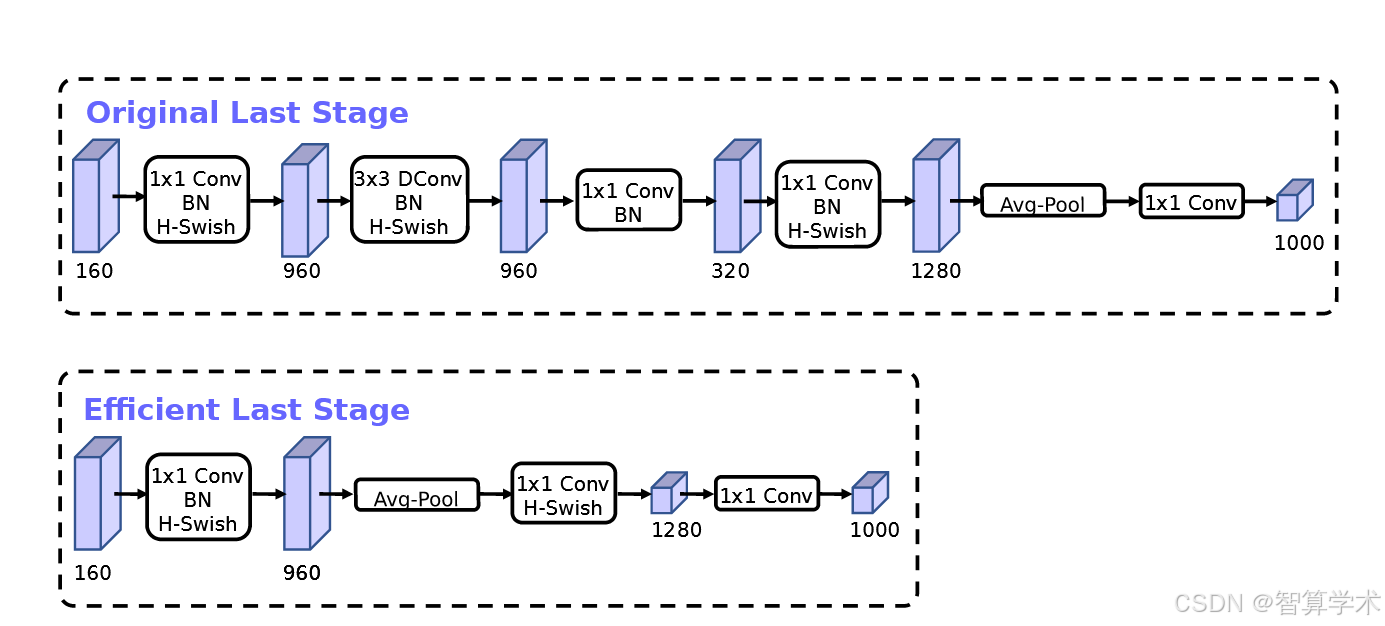
高效的最后阶段减少了7毫秒的延迟,占运行时间的11%,并减少了3000万个MAdds操作,几乎没有损失准确性。第6节包含了详细的结果。另一个昂贵的层是初始的一组滤波器。目前的移动模型倾向于使用32个滤波器在完整的3x3卷积中构建用于边缘检测的初始滤波器库。这些滤波器通常是彼此的镜像。我们尝试减少滤波器的数量并使用不同的非线性函数来减少冗余。我们最终决定使用硬Swish非线性函数,因为它的表现与其他测试的非线性函数相当。我们成功将滤波器的数量减少到16个,同时保持了与使用ReLU或Swish的32个滤波器相同的准确性。这节省了额外的2毫秒和1000万个MAdds。
精读
遇到的问题及解决方式:
-
问题:最后几层的高计算和延迟:最后几层,特别是用于特征生成的1x1卷积层,计算量大且延迟高。 解决方法:将1x1卷积层移到最后平均池化之后,减少计算和延迟,同时保持特征的高维度,去掉不必要的瓶颈投影层,进一步降低计算复杂度。
-
问题:初始滤波器数量多且冗余:初始滤波器使用32个,且很多滤波器冗余。 解决方法:减少滤波器的数量,使用硬Swish非线性函数,在保持准确性的同时将滤波器数量减少到16个,从而节省计算资源和延迟。
5.2 Nonlinearities—非线性函数
翻译
在[36, 13, 16]中,引入了一种非线性函数叫做swish,当它作为ReLU的替代品使用时,能显著提高神经网络的准确性。该非线性函数的定义为: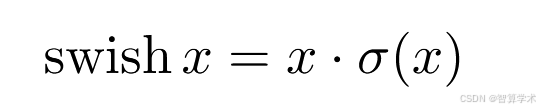
虽然这种非线性函数提高了准确性,但在嵌入式环境中,它带来了不可忽视的计算成本,因为在移动设备上计算sigmoid函数要比其他函数更昂贵。我们通过两种方式解决了这个问题。
我们用其分段线性硬模拟版本替换sigmoid函数:ReLU6(x+3) 6,类似于[11, 44]。唯一的不同是我们使用ReLU6,而不是自定义的剪裁常数。类似地,swish的硬版本变为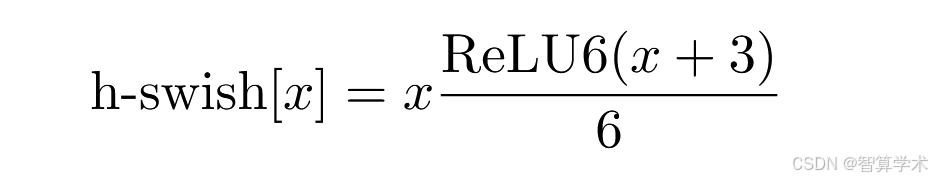
在[2]中也提出了一个类似的硬-swish版本。软版本和硬版本的sigmoid和swish非线性函数的对比如图6所示。我们选择常数的原因是简洁且与原始平滑版本匹配。在我们的实验中,我们发现所有这些函数的硬版本在准确度上没有明显差异,但从部署角度来看有多个优势。首先,ReLU6的优化实现几乎可以在所有软件和硬件框架上使用。其次,在量化模式下,它消除了不同实现近似sigmoid时可能造成的数值精度损失。最后,在实际应用中,h-swish可以作为分段函数实现,从而减少内存访问次数,显著降低延迟成本。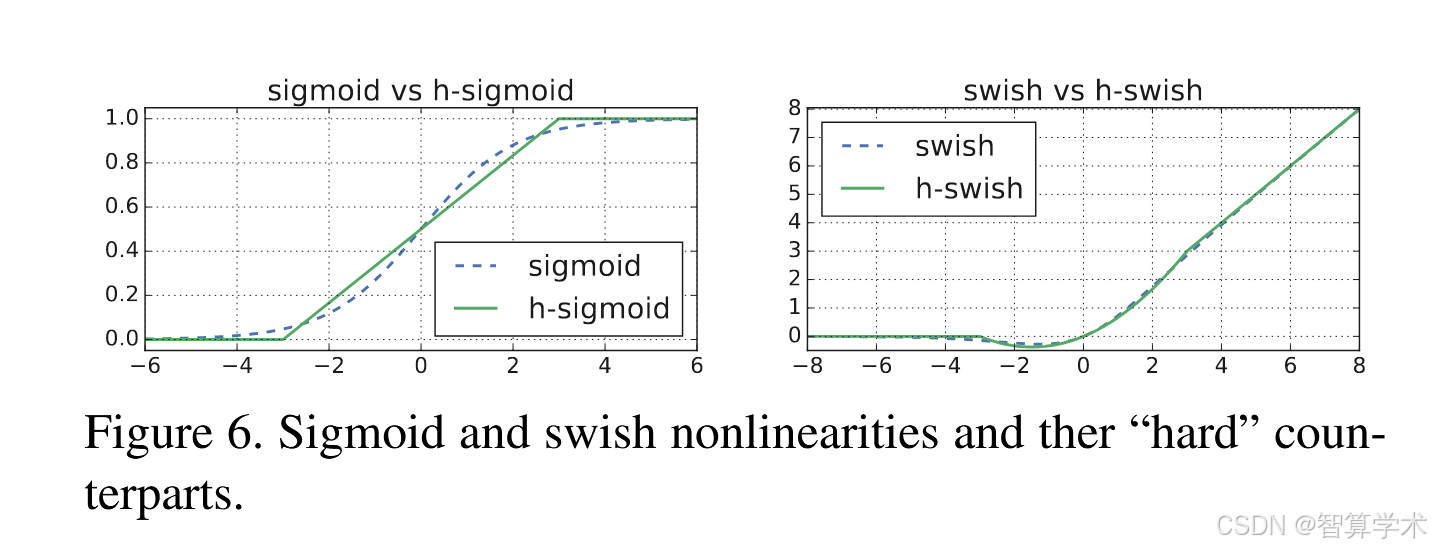
应用非线性的成本随着网络层数的加深而减少,因为每层的激活内存通常在分辨率降低时会减半。顺便提一下,我们发现swish的多数好处仅在使用于更深层时才能实现。因此,在我们的架构中,我们仅在模型的后半部分使用h-swish。具体布局请参见表1和表2。即使有这些优化,h-swish仍然会引入一些延迟成本。然而,正如我们在第6节中展示的,准确度和延迟的净效应是积极的,并且在使用基于分段函数的优化实现时效果显著。
精读
主要讨论了在神经网络中使用swish非线性激活函数的优化方法。Swish函数作为ReLU的替代品,可以显著提高神经网络的准确性。然而,swish在移动设备等嵌入式环境中的计算成本较高,因为它依赖于sigmoid函数,而计算sigmoid函数在这些环境中相对昂贵。为了克服这个问题,文章提出了两种优化方法:
-
版本替代:使用swish的硬版本(h-swish),通过将sigmoid函数替换为一个分段线性函数——ReLU6(x+3) 6来减少计算成本。与原始的平滑版本相比,这个硬版本在准确性上没有显著差异,但在嵌入式设备上更易于实现,h-swish可以通过分段函数实现,减少内存访问,从而显著降低延迟。
-
优化应用位置:随着网络深度的增加,每层的激活内存会逐渐减小,因此应用非线性的计算成本也会减少。文章发现swish的效果主要体现在网络的较深层,因此它们只在模型的后半部分使用h-swish,这样能更高效地发挥其优势。
5.3 Large squeeze-and-excite—大型SE
翻译
在[43]中,压缩与激励瓶颈的大小是相对于卷积瓶颈的大小的。相反,我们将它们都固定为扩展层通道数的1/4。我们发现这样做可以提高准确性,同时参数数量的增加较为适中,并且没有明显的延迟成本。
精读
原本压缩和激励层的大小是根据卷积层的大小来定的。我们改变了这种做法,把压缩和激励层的大小固定为扩展层通道数的1/4。这样做的结果是,模型的准确性提高了,虽然参数数量有点增加,但延迟几乎没有变化。
5.4 MobileNetV3 Definitions—MobileNetV3 定义
翻译
MobileNetV3 定义了两种模型:MobileNetV3Large 和 MobileNetV3-Small。这些模型分别针对高资源和低资源的应用场景。通过应用平台感知的神经架构搜索(platform-aware NAS)和 NetAdapt 进行网络搜索,并结合本节中定义的网络优化来创建这些模型。具体的网络规格请参见表格 1 和 2。
精读
应用NAS和Netdapt方法并结合本论文网络优化方法定义了两个模型结构MobileNetV3Large 和 MobileNetV3-Small
MobileNetV3Large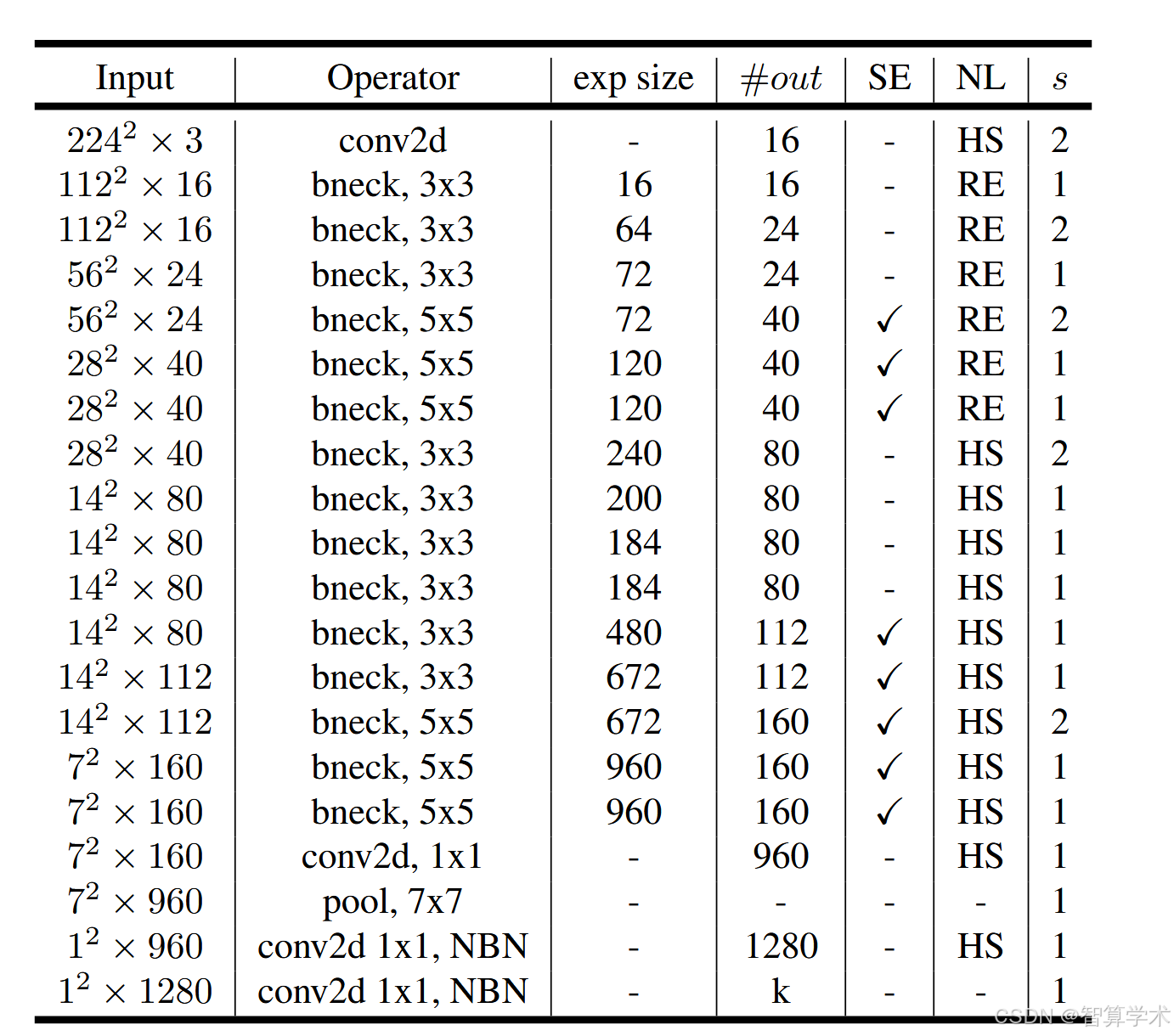
input: feature map输入尺寸大小 operator: 表示的是模块操作 NBN: 最后两个卷积的operator提示NBN,表示这两个卷积不使用BN结构 exp size 代表的是第一个升维的卷积,exp size多少,我们就用第一层1x1卷积升到多少维 #out: 代表的是输出特征矩阵的channel,我们说过在v3版本中第一个卷积核使用的是16个卷积核 NL: 代表的是激活函数,其中HS代表的是hard swish激活函数,RE代表的是ReLU激活函数 s: 代表的DW卷积的步距 beneck: 对应的是下图中的结构 SE: 表示是否使用注意力机制,只要表格中标√所对应的bneck结构才会使用我们的注意力机制,对没有打√就不会使用注意力机制
MobileNetV3-Small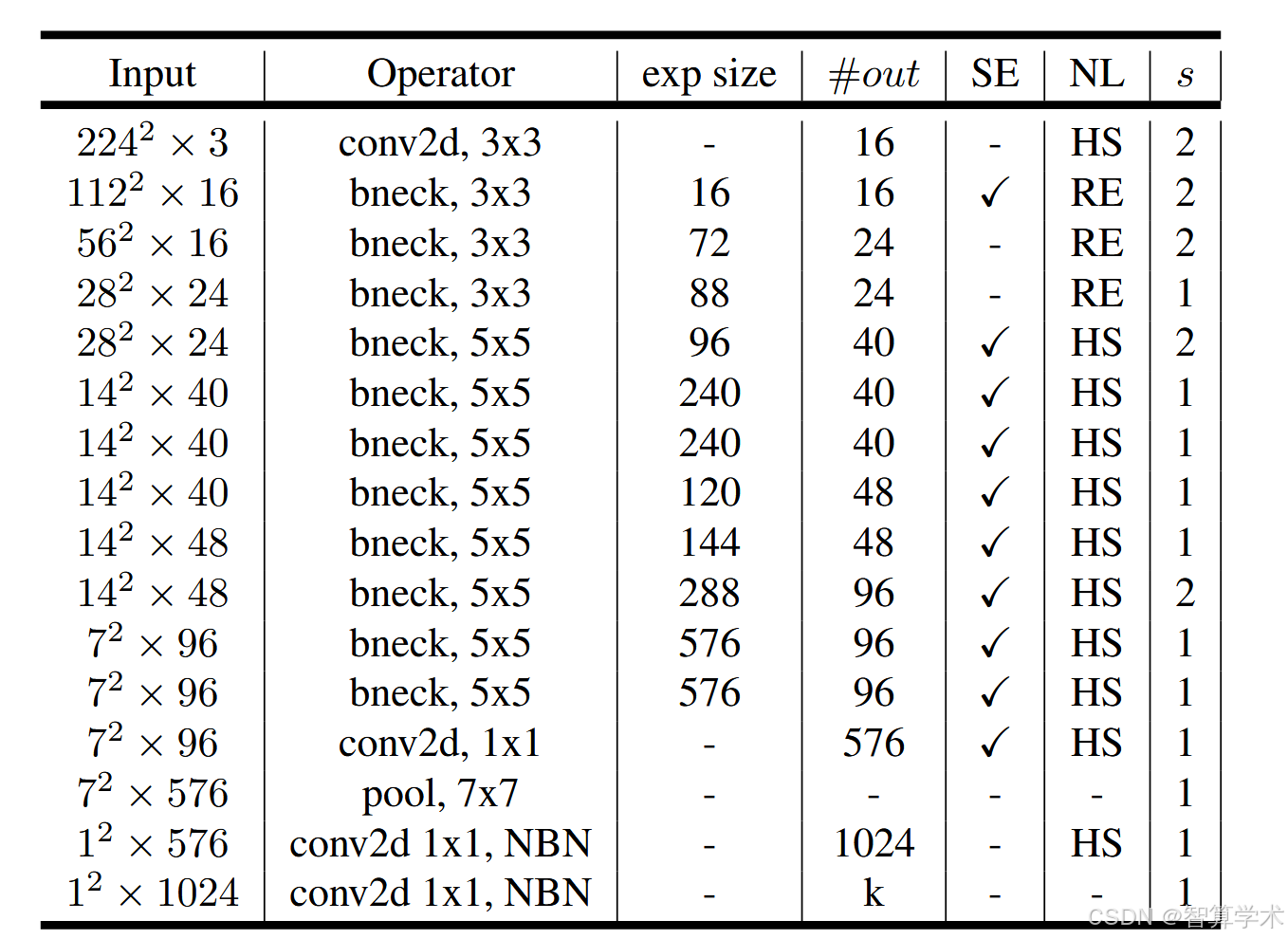
参数和MobileNetV3Large 表的一致
六、Experiments—实验
6.1 Classification—分类
6.1.1 Training setup—训练设置
翻译
我们使用同步训练设置,在 4x4 TPU Pod 上训练我们的模型 [24],并采用标准的 TensorFlow RMSPropOptimizer,动量为 0.9。初始学习率为 0.1,批量大小为 4096(每个芯片 128 张图像),学习率衰减率为 0.01,每 3 个 epoch 衰减一次。我们使用 0.8 的 dropout,l2 权重衰减为 1e-5,并采用与 Inception [42] 相同的图像预处理。最后,我们使用衰减为 0.9999 的指数移动平均。所有的卷积层都使用批量归一化层,平均衰减为 0.99。
精读
优化器:使用 TensorFlow 的 RMSPropOptimizer,动量为 0.9。
初始学习率:0.1。
批量大小:4096(每个芯片 128 张图像)。
学习率衰减:每 3 个 epoch 衰减率为 0.01。
Dropout:0.8。
L2 权重衰减:1e-5。
图像预处理:与 Inception 模型使用相同的预处理方式。
指数移动平均:衰减率为 0.9999。
批量归一化:所有卷积层使用批量归一化,平均衰减为 0.99。
6.1.2 Measurement setup—测量设置
翻译
为了测量延迟,我们使用标准的 Google Pixel 手机,并通过标准的 TFLite 基准工具运行所有网络。在所有测量中,我们使用单线程的大核心。我们没有报告多核推理时间,因为我们认为这种设置对移动应用程序来说并不实用。我们为 TensorFlow Lite 提供了一个原子 h-swish 操作符,并且它已经成为最新版本中的默认操作符。我们在图 9 中展示了优化后的 h-swish 的影响。
精读
延迟测量:使用标准的 Google Pixel 手机和 TFLite 基准工具来测量网络的延迟,采用单线程的大核心进行所有测量。
多核推理不报告:没有报告多核推理时间,因为多核设置对移动应用不实用。
h-swish优化:为 TensorFlow Lite 提供了优化后的 h-swish 操作符,并且该操作符已经成为最新版本的默认操作符。优化后的 h-swish 的影响在图9中展示。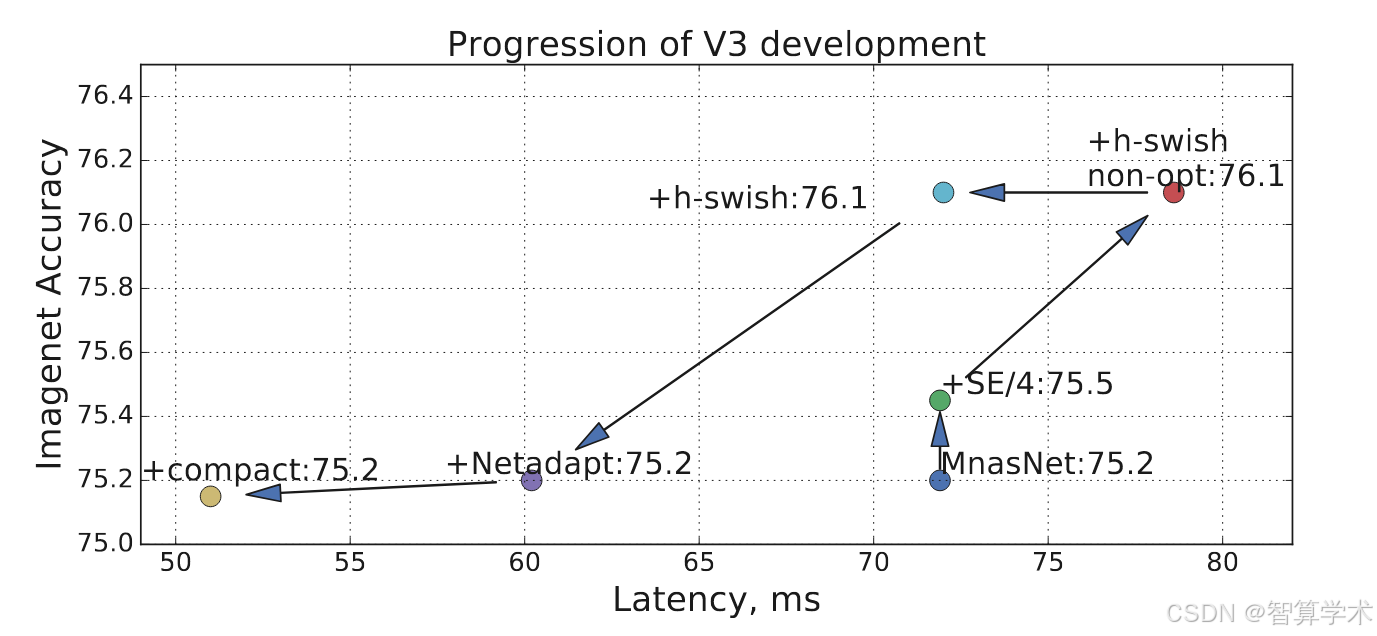
6.2 Results—结果
翻译
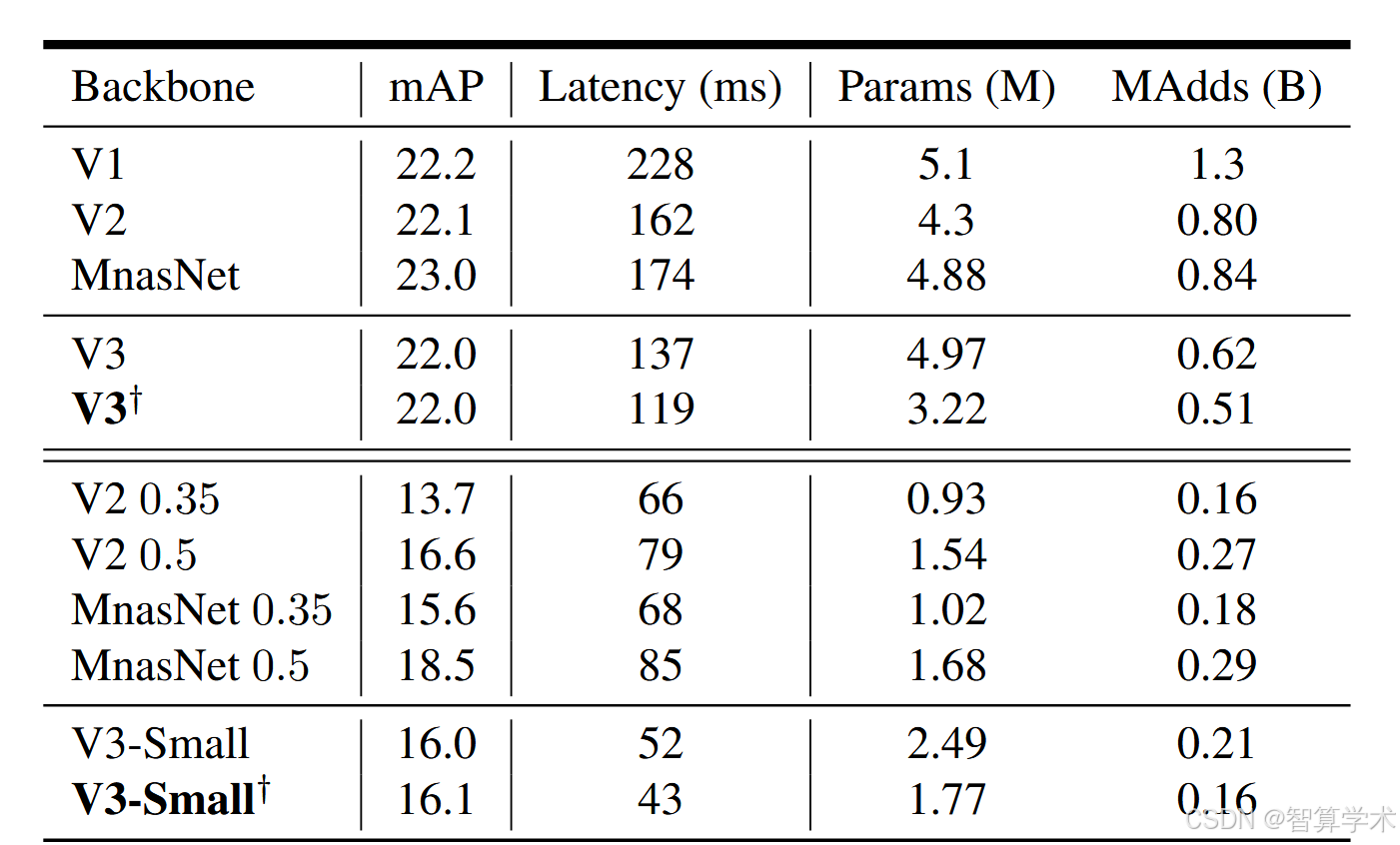
如图1所示,我们的模型在性能上超过了当前的主流模型,如 MnasNet [43]、ProxylessNas [5] 和 MobileNetV2 [39]。我们在表3中报告了不同 Pixel 手机上的浮动点性能,并在表4中提供了量化结果。在图7中,我们展示了 MobileNetV3 在乘法器和分辨率变化下的性能权衡。可以看到,当将 MobileNetV3-Small 的乘法器调整到与 MobileNetV3Large 相匹配时,它的性能提高了近3%。另一方面,分辨率提供了比乘法器更好的权衡。然而,需要注意的是,分辨率通常由问题决定(例如,分割和检测问题通常需要更高的分辨率),因此不能总是作为可调参数使用。
精读
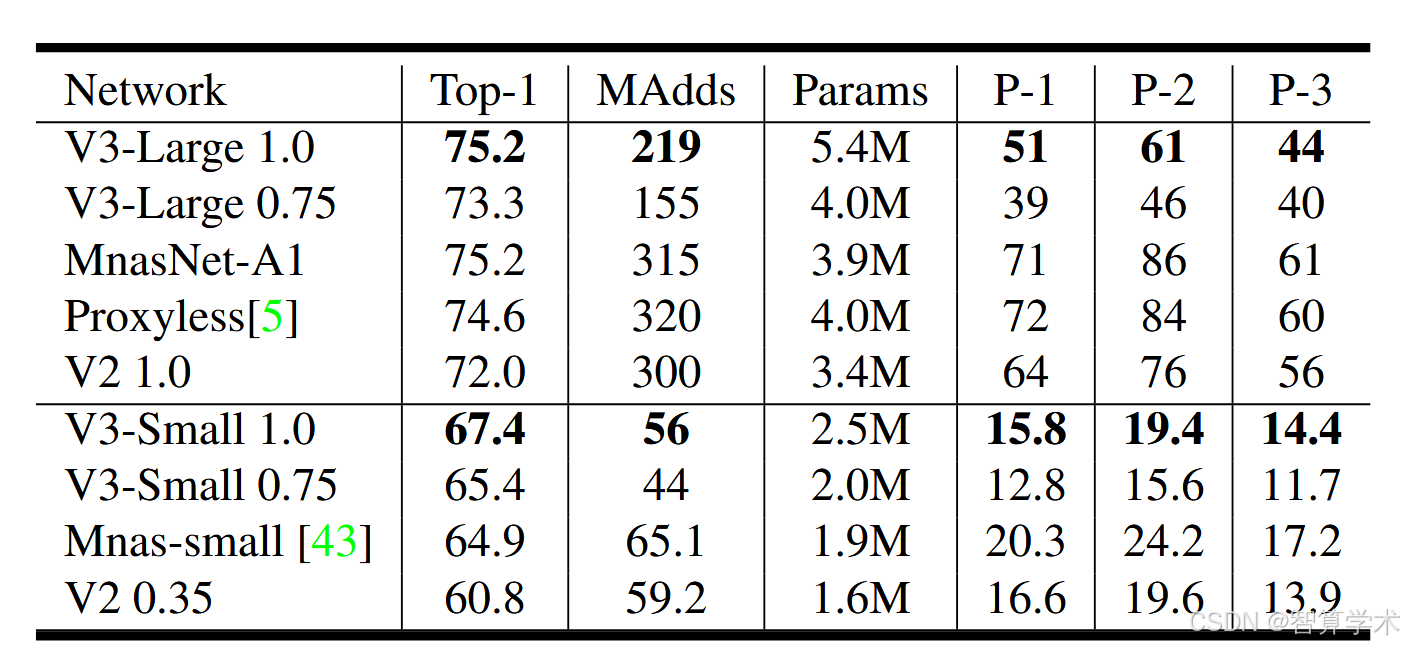
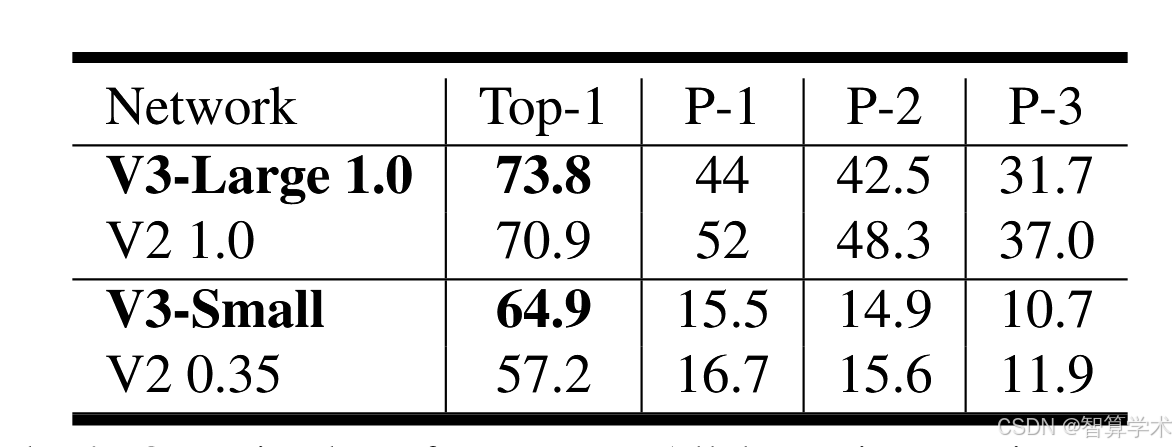
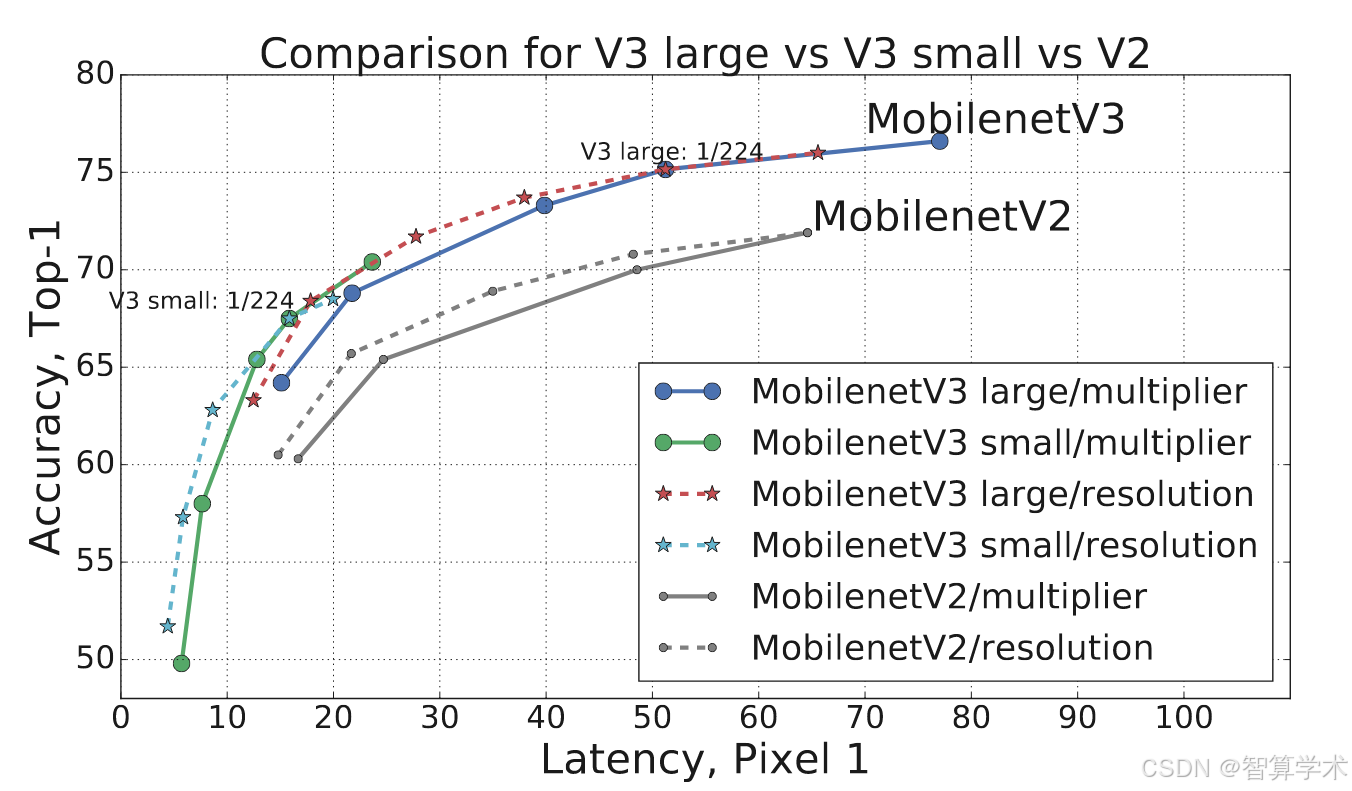
展示了MobileNetV3模型在性能上优于一些现有的主流模型,比如MnasNet、ProxylessNas和MobileNetV2。文章还提供了在不同Pixel手机上的性能表现,并讨论了量化后的效果。在展示的图表中,MobileNetV3-Small版本在调整参数后,性能比MobileNetV3-Large版本提高了约3%。另外,调整分辨率对于性能提升更有效,比调整乘法器(网络参数)效果更好。不过,分辨率的选择通常依赖于具体任务,比如图像分割和物体检测就需要更高的分辨率,所以并不是每个任务都可以灵活调整分辨率。
6.2.1 Ablation study—消融实验
翻译
在表5中,我们研究了插入h-swish非线性函数的位置选择,以及使用优化版实现相比于简单实现所带来的改进。可以看出,使用优化版的h-swish节省了6毫秒(超过10%的运行时间)。与传统的ReLU相比,优化版的h-swish仅增加了1毫秒。图8展示了基于非线性选择和网络宽度的高效前沿。MobileNetV3在网络中部使用h-swish,明显优于ReLU。值得注意的是,将h-swish应用于整个网络的效果略优于通过增加网络宽度进行插值的前沿。图9展示了不同组件引入后,如何推动延迟/准确度曲线的变化。
精读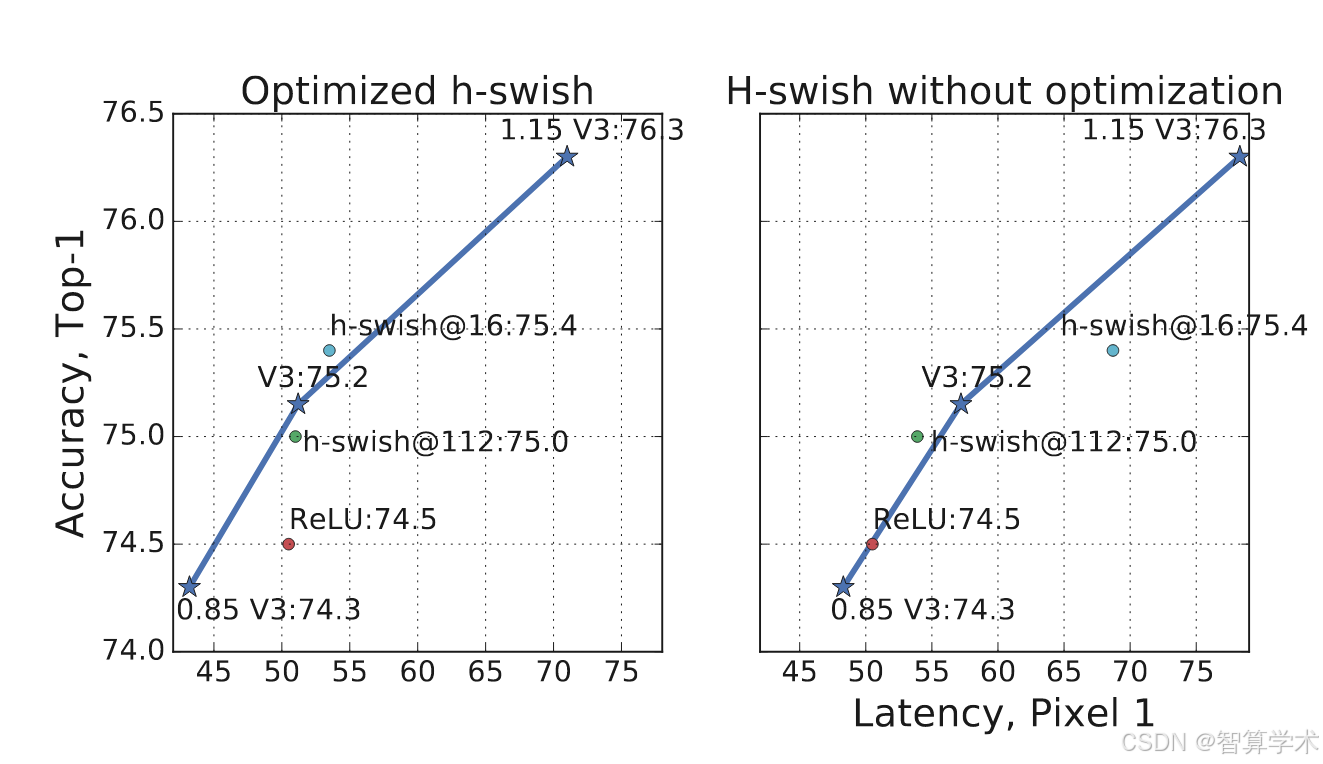
图8(非线性选择与网络宽度的高效前沿):
-
h-swish的效果:在网络中部使用优化版的h-swish非线性函数,比传统的ReLU有更好的性能,显著提升了效率。
-
宽度与性能的权衡:将h-swish应用到整个网络的性能略优于仅通过增加网络宽度(即插值方式)来提升性能。这表明,选择适当的非线性函数比单纯增加网络宽度带来更好的性能提升。
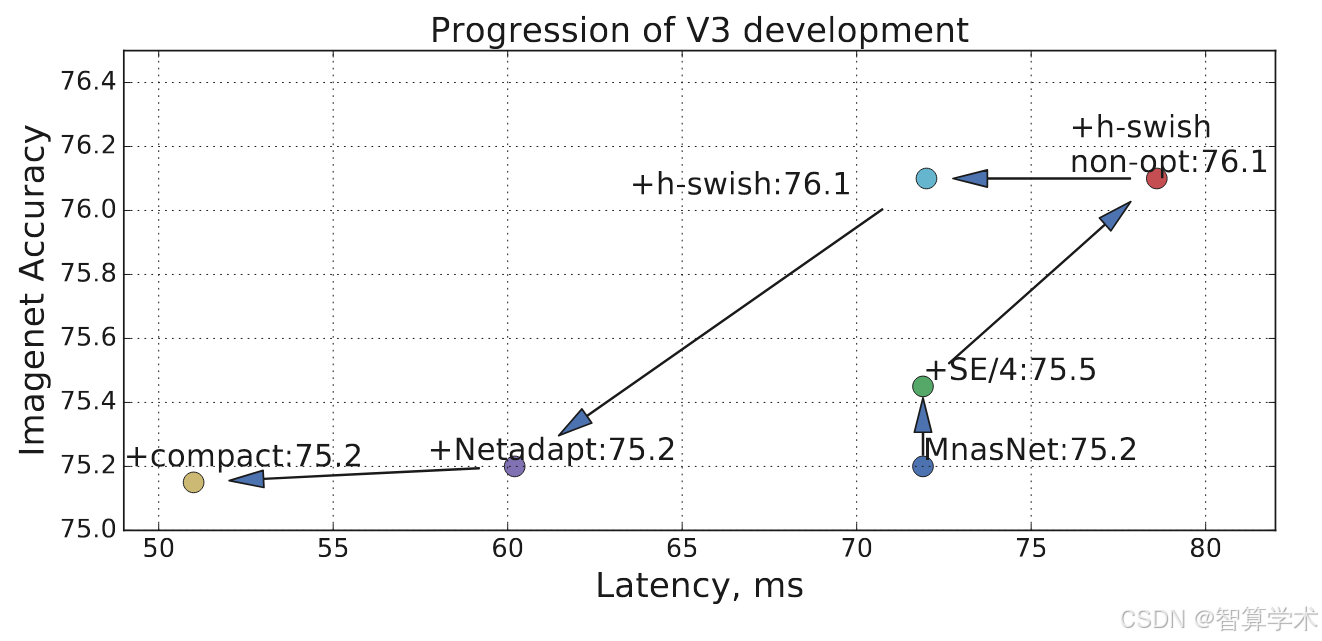 图9(不同组件引入对延迟/准确度曲线的影响):
图9(不同组件引入对延迟/准确度曲线的影响):
-
通过引入不同的组件,MobileNetV3的延迟与准确度之间的权衡得到了优化,推动了性能曲线的改善。
-
不同的组件(例如h-swish、网络架构优化等)的引入,推动了模型在延迟和准确度之间取得更好的平衡,从而提升了整体性能。
6.3 Detection—检测
翻译
我们使用MobileNetV3作为SSDLite [39] 中的特征提取器的替代,并与其他主干网络在COCO数据集[26]上进行比较。按照MobileNetV2 [39] 的做法,我们将SSDLite的第一层连接到输出步长为16的最后一个特征提取层,并将第二层连接到输出步长为32的最后一个特征提取层。根据目标检测文献,我们将这两层特征提取器分别称为C4和C5。对于MobileNetV3-Large,C4是第13个瓶颈块的扩展层;对于MobileNetV3-Small,C4是第9个瓶颈块的扩展层;对于这两个网络,C5是池化前的层。我们还将C4和C5之间的所有特征层的通道数减少了2倍。原因是MobileNetV3的最后几层被调整为输出1000个类别,在转换到具有90个类别的COCO时,可能存在冗余。COCO测试集上的结果见表6。通过通道数减少,MobileNetV3-Large比MobileNetV2快27%,而mAP几乎相同。经过通道数减少的MobileNetV3-Small相比MobileNetV2和MnasNet的mAP分别高出2.4和0.5,同时速度提高了35%。对于这两个MobileNetV3模型,通道数减少技巧贡献了大约15%的延迟降低,而没有损失mAP,这表明Imagenet分类和COCO物体检测可能需要不同的特征提取器形状。
精读
表6(COCO测试集结果):MobileNetV3在与MobileNetV2和其他网络的比较中展现了出色的性能,特别是在速度和准确度的平衡上。通过对通道数的减少,MobileNetV3-Large相比MobileNetV2速度提升了27%,而MobileNetV3-Small则在速度提升35%的同时,比MobileNetV2和MnasNet的mAP高出2.4和0.5。通道数减少不仅减少了延迟,而且没有牺牲mAP,表明对于目标检测任务,网络的特征提取器形状需要根据任务进行调整。
6.4 Semantic Segmentation—语义分割
翻译
在本小节中,我们使用MobileNetV2 [39]和提议的MobileNetV3作为移动语义分割任务的网络骨干,并比较了两种分割头。第一个被称为R-ASPP,这是[39]中提出的设计,R-ASPP是Atrous Spatial Pyramid Pooling模块[7, 8, 9]的简化版,采用了两个分支,其中一个是1×1卷积,另一个是全局平均池化操作[29, 50]。在本工作中,我们提出了另一种轻量级分割头,称为Lite R-ASPP(或LR-ASPP),如图10所示。Lite R-ASPP在R-ASPP的基础上进行了改进,采用了类似于Squeeze-and-Excitation模块[20]的全局平均池化方式,其中使用了较大的池化核和较大的步幅(以节省一些计算),并且在模块中只有一个1×1卷积。我们对MobileNetV3的最后一个块应用了空洞卷积[18, 40, 33, 6]以提取更密集的特征,并进一步加入了从低级特征到高层特征的跳跃连接[30],以捕捉更多细节信息。我们在Cityscapes数据集[10]上进行实验,并使用mIOU[14]作为度量,仅使用‘fine’标注。我们采用与[8, 39]相同的训练协议。所有模型从头开始训练,没有在ImageNet[38]上进行预训练,并且仅使用单尺度输入进行评估。类似于目标检测,我们发现可以将网络骨干最后一个块的通道数减少一半,而不会显著降低性能。我们认为这是因为骨干网络是为1000类的ImageNet图像分类[38]设计的,而Cityscapes只有19个类,意味着骨干网络中存在一些通道冗余。我们在表7中报告了我们的Cityscapes验证集结果。根据表中的数据,我们观察到:(1)将网络骨干最后一个块的通道数减少一半显著提高了速度,同时保持了相似的性能(行1与行2,以及行5与行6);(2)提议的分割头LR-ASPP比R-ASPP[39]稍快,并且性能有所提升(行2与行3,以及行6与行7);(3)将分割头中的过滤器从256减少到128,提高了速度,但性能略有下降(行3与行4,以及行7与行8);(4)在相同设置下,MobileNetV3模型变体的性能与MobileNetV2相似,同时稍微快一些(行1与行5,行2与行6,行3与行7,以及行4与行8);(5)MobileNetV3-Small的性能与MobileNetV2-0.5相似,但速度更快;(6)MobileNetV3-Small显著优于MobileNetV2-0.35,同时保持相似的速度。表8展示了我们的Cityscapes测试集结果。我们的分割模型以MobileNetV3作为网络骨干,在速度上比ESPNetv2[32]、CCC2[34]和ESPNetv1[32]更快,且性能分别提高了6.4%、10.6%、12.3%。当不使用空洞卷积提取MobileNetV3最后块中的密集特征图时,性能略微下降了0.6%,但速度提高到1.98B(对于半分辨率输入),比ESPNetv2、CCC2和ESPNetv1分别快1.36、1.59和2.27倍。此外,使用MobileNetV3-Small作为网络骨干的模型仍然比它们所有模型性能更好,至少提高了2.1%。
精读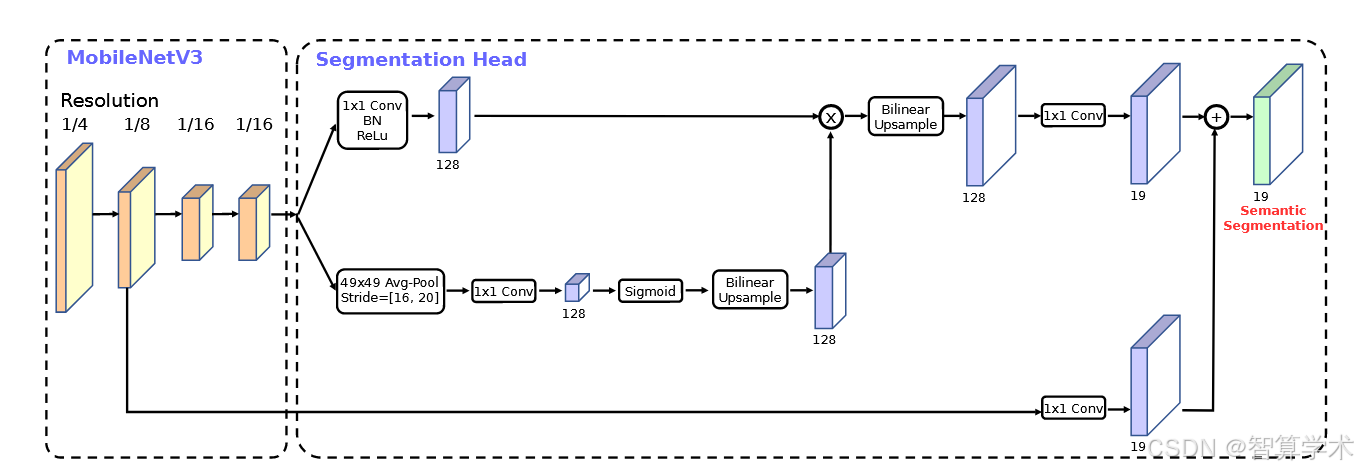
主要讲了使用MobileNetV3和MobileNetV2作为网络骨干进行移动端语义分割任务的实验。研究发现:
-
减少网络骨干最后一个块的通道数显著提升速度且几乎不影响性能。
-
提出的LR-ASPP分割头比R-ASPP稍快且性能更好。
-
将分割头的滤波器数减少会提高速度,但稍微降低性能。
-
MobileNetV3模型在速度和性能上优于MobileNetV2,尤其是MobileNetV3-Small比MobileNetV2-0.35更好。
-
MobileNetV3模型在Cityscapes测试集上表现优于ESPNetv2、CCC2和ESPNetv1,且速度更快。
七、Conclusions and future work—结论和未来工作
翻译
在本文中,我们介绍了MobileNetV3 Large和Small模型,展示了在移动端分类、检测和分割任务中取得的新一代最先进成果。我们描述了如何利用多种网络架构搜索算法和网络设计的最新进展,推出下一代移动端模型。我们还展示了如何以量化友好和高效的方式适配非线性激活函数(如swish)并应用squeeze-and-excite,成功将这些技术引入移动模型领域。我们还介绍了一种新的轻量级分割解码器LR-ASPP。尽管如何最好地将自动搜索技术与人类直觉结合仍是一个开放问题,但我们很高兴展示这些初步的积极成果,并将继续在未来的工作中完善这些方法。
精读
本文介绍了MobileNetV3 Large和Small模型,展示了在移动端分类、检测和分割任务中的最新成果。通过结合多种网络架构搜索算法和网络设计进展,我们推出了下一代移动端模型。我们还介绍了高效的非线性激活函数(如swish)和轻量级分割解码器LR-ASPP。


















 2246
2246

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









