







题目
Estimation–Action–Reflection: Towards Deep Interaction Between Conversational and Recommender Systems
简介
目前,推荐系统正在采用会话技术来获取用户动态偏好。本文认为一个好的会话推荐系统需要正确处理会话和推荐之间的交互,其中就有三个基本问题需要解决:
1)关于item attributes要问什么问题;
2)什么时候推荐items;
3)如何利用用户的在线反馈;
但是目前,没有一个统一的框架来解决这些问题。在这项工作中,本文通过提出一个名为Estimation–Action–Reflection或EAR的新CRS框架:
(1)Estimation,其构建预测模型来估计user对items和item attributes的偏好;
(2) Action,基于Estimation阶段和会话历史,学习对话策略以确定是询问attributes还是recommdend items;
(3)Reflection,当user拒绝由action阶段做出的recommendations时,其更新recommdend model
本文提出了两个关于binary和enumerated问题的对话场景,并在Yelp和LastFM的两个数据集上分别对每个场景进行了广泛的实验。实验表明,与其他最先进的方法相比,本文的模型框架对应于更少的对话次数和更高的推荐点击量
what
本文认为CRS模型本应该采用多轮设置:与用户交谈并根据他的点击历史推荐项目。在每一轮,CRS被允许选择两种类型的动作——要么明确询问用户是否喜欢某个项目属性,要么推荐一个项目列表
所以,执行这种计划的关键在于对话组件(CC;负责与用户交互)和推荐器组件(RC;负责估计用户偏好–例如,生成推荐列表)。本文还将CC与RC深度互动的三个基本问题总结如下:
- What attributes to ask?
- When to recommend items?
- How to adapt to users’ online feedback?
本文提出了一个新的解决方案,为Estimation–Action-Reflection(EAR),它由三个阶段组成
(a)Estimation,离线建立预测模型,估计用户对物品和物品属性的偏好
(b)Action,学习决定问还是推荐,问什么属性的对话策略,该阶段使用了强化学习训练policy
©Reflection,根据用户的在线反馈调整CRS,具体来说,当用户拒绝推荐项目时,通过将items视为负面实例来构建新的训练三元组,并以在线方式更新FM
总之,这项工作的主要贡献如下:
(1)综合考虑了比以前的工作更现实的多轮CRS
(2)提出了一个三阶段解决方案,EAR,整合并修改了几种RC和CC技术,以构建一个适用于对话式推荐的解决方案
(3)通过模拟用户对话来构建两个CRS数据集,以使任务适合离线学术研究
- MULTI-ROUND CONVERSATIONAL RECOMMENDATION SCENARIO
本文将会话式推荐视为一种内在的多轮场景,CRS通过多次询问属性和推荐项目与用户进行交互,直到任务成功或用户离开

整个过程自然形成了一个交互循环,在这个循环中,如果用户接受推荐或由于不耐烦而离开,会话将终止。本文将CRS的主要目标设定为在尽可能少的回合内提出期望的建议
how
EAR由一个推荐和对话组件(RC和CC)组成,这两个组件在三阶段对话过程中紧密交互
(1)系统在Estimation阶段开始工作,RC为user对候选items和attributes进行排序,以支持CC的action policy
(2)在Estimation阶段之后,系统移动到action阶段,在action阶段,CC根据排序后的candidates,attributes以及对话历史来决定是选择attributes去询问,还是进行推荐。如果用户喜欢RC询问的属性,CC将该属性反馈给RC再次进行新的Estimation;否则,系统停留在action阶段:更新对话历史并选择另一个action
(3)一旦推荐被user拒绝,CC将拒绝的items发送回RC,触发reflection阶段,RC调整其Estimation。之后,系统再次进入Estimation阶段
- Estimation
CC与用户u交互并积累关于user的preferred attributes,表示为Pu= {p1,p2,…,pn},接下来需要充分利用Pu来准确预测user的preferred items和preferred attributes。其中第一个目标直接有助于推荐的成功率,第二个目标引导CC选择更好的属性来询问用户,从而缩短对话。在下面,本文首先介绍推荐方法的基本形式,然后详细介绍如何调整本文提出的方法来同时实现这两个目标- Basic Recommendation Method.
选择因式分解机(FM) 作为预测模型,FM是输入特征之间的成对交互,但是本文只保留对任务有用的交互,而删除其他的。给定用户u、用户在对话中的preferred attributes Pu和target item v,预测用户在对话中喜欢v的可能性: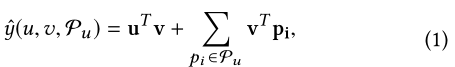
为了训练FM,使用成对贝叶斯个性化排名(BPR)优化目标。具体来说,给定一个user,与user交互的items(例如,参观的餐馆,听的音乐)应该比没有和user交互的items得分更高,损失函数是:
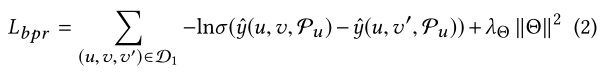
- Attribute-aware BPR for Item Prediction
但是,在本文的场景中,CRS的重点应该是对那些也包含了用户偏好属性的items进行排名。因此,首先定义了两个集合:

然后,又重新改了了损失函数
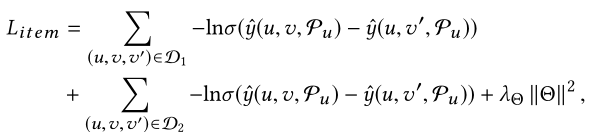
其中第一个损失学习了user的一般偏好,第二个损失基于当前的候选项学习了user的特定偏好(因为候选项目会随着用户在对话中的反馈而动态变化) - Attribute Preference Prediction
本文还制定了第二个预测任务,这种对属性偏好的预测主要用于CC中,以确定在action阶段对哪个属性进行询问
首先,本文考虑了user在当前会话中的preferred attributes:

它给出了u当前偏好的属性Pu,在此基础上估计了u对属性p的偏好
为了训练模型,本文同样使用了BPR损失,并假设(会话的)基本事实项目的属性应该比其他属性排名更高:

- Multi-task Training
对以上两个任务进行联合训练直至模型收敛,损失函数为:
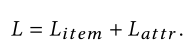
- Basic Recommendation Method.
- Action
Estimation阶段之后,Action阶段是寻找最佳策略解决何时推荐的问题- State Vector
状态向量是CC和RC之间相互作用的桥梁。本文将来自RC和对话历史的信息编码成状态向量,提供给CC选择actions。状态向量具体分为四个分量向量:
1)S(ent):该向量对当前候选项的属性中每个属性的熵信息进行编码
2 这个向量对每个属性的u偏好进行编码
3 这个向量对会话历史进行编码
4 这个向量对当前候选列表的长度进行编码
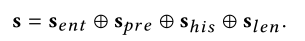
- Policy Network and Rewards
具体来说,CC每回合采取一个动作后,将立即获得用户(或用户模拟器)的奖励。这将引导CC学习优化长期奖励的最优策略。在EAR中,我们设计了四种奖励,即:(1) rsuc,推荐成功时的正奖励,(2) rask,用户对被问属性给出正反馈时的正奖励,(3) rquit,用户退出对话时的负奖励,(4) rprev,负奖励,每个回合都有一个负奖励来阻止过长的对话。中间报酬rt是以上四个奖励的总和: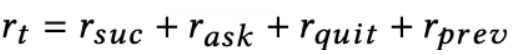
- State Vector
- Reflection
这个阶段还实现了CC和RC之间的交互。当CC将推荐项目推送给用户但被拒绝时触发,以便更新RC模型以在未来回合中获得更好的推荐。具体来说,本文将被拒绝的项目视为负样本,构建更多的训练示例来更新FM。在离线训练过程之后,本文还优化了BPR损失:
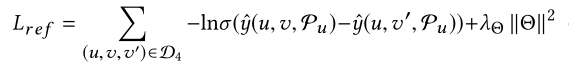
Result
成功率对比:

auc效果对比:

各个状态向量对模型效果的影响:

在线更新对模型效果的影响:

Conclusion
在这项工作中,本文重新定义了会话式推荐任务,其中RC和CC紧密地相互支持,从而以更少的轮次达到精确推荐的目标。而且,本文将任务分解为三个关键问题,即问什么、什么时候推荐、如何适应用户反馈。然后,又提出了EAR——一个新的三阶段解决方案,在一个统一的框架中解决这三个问题















 1208
1208











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









