










安装Aanconda
一般两个选择,一个是官网,另一个是国内镜像网站(大家自行选择)。前者大家都懂,速度感人,所以国内一般选择后者镜像下载。
1)官网,进去都是英文,不懂直接点翻译。
https://www.anaconda.com/download
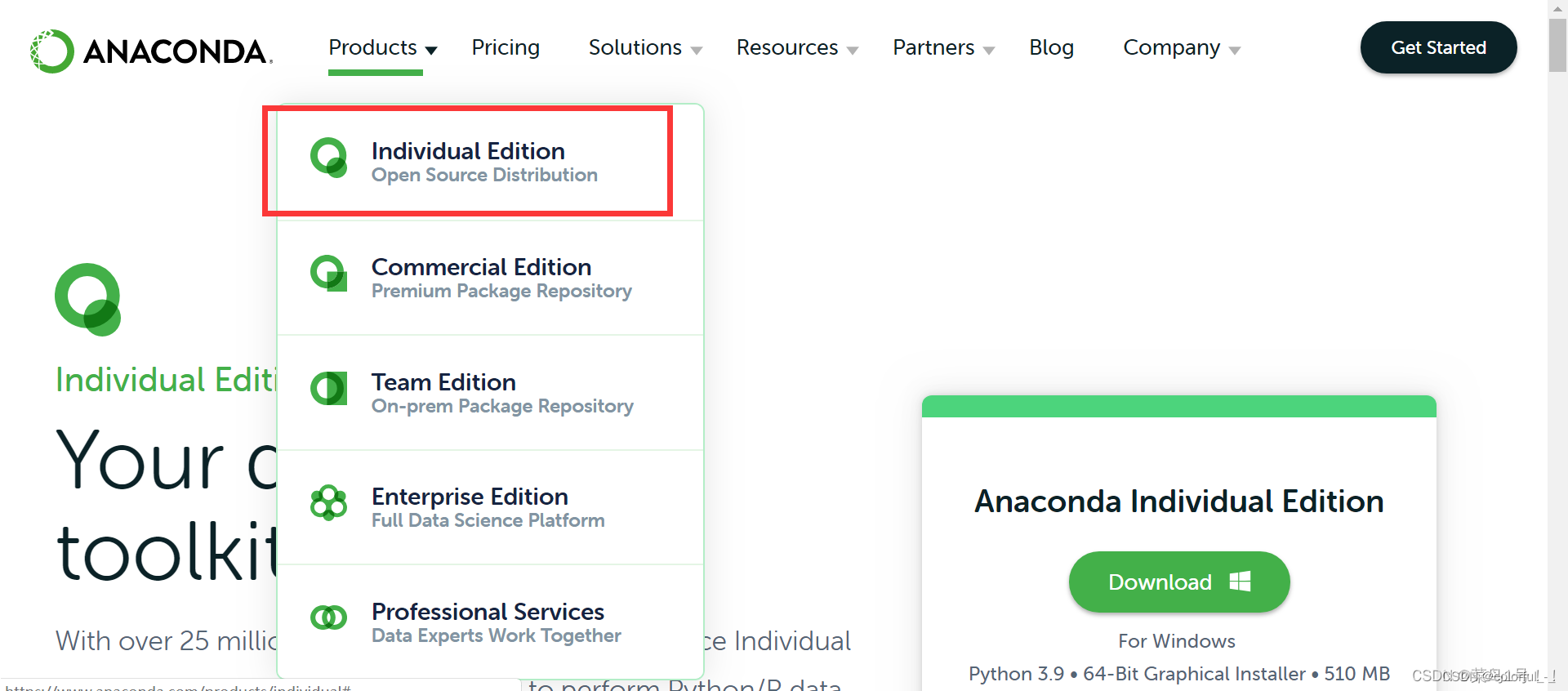
看红色框子里面,选择这个就🆗。

2)我比较推荐大家用这种方法,自己使用的也是这种方法。(清华大学开源镜像网站)
https://mirrors.tuna.tsinghua.edu.cn/anaconda/archive/
根据自己电脑选择对应版本:下载还是挺快的。
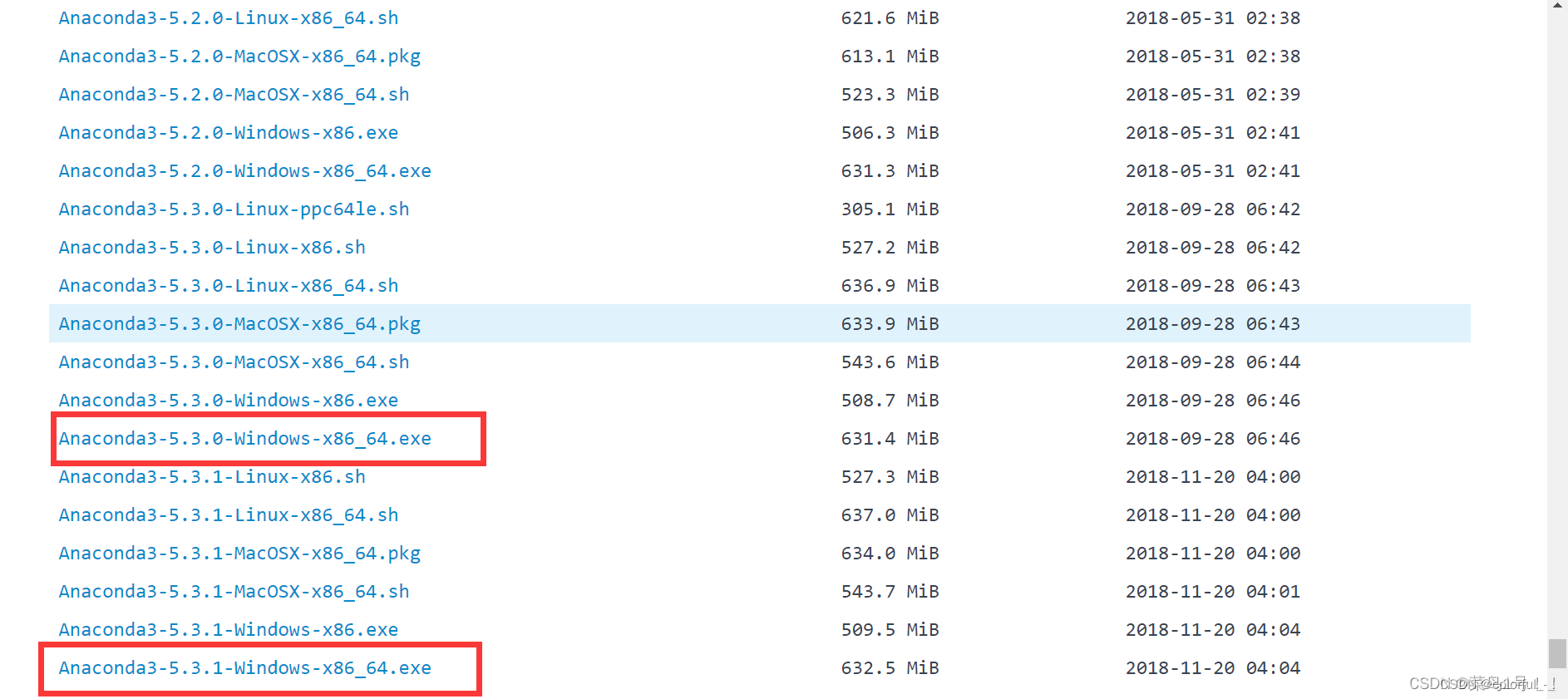
Anaconda的安装:
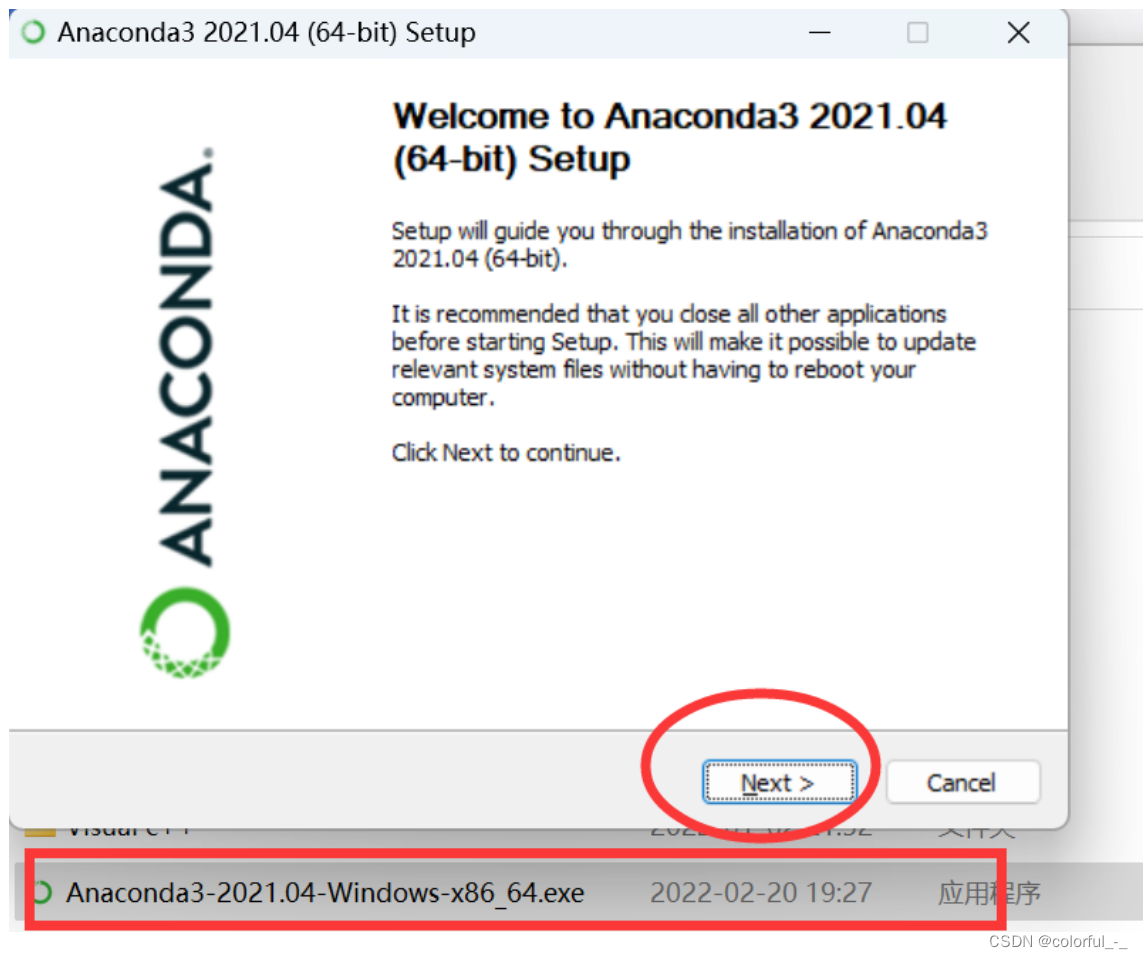
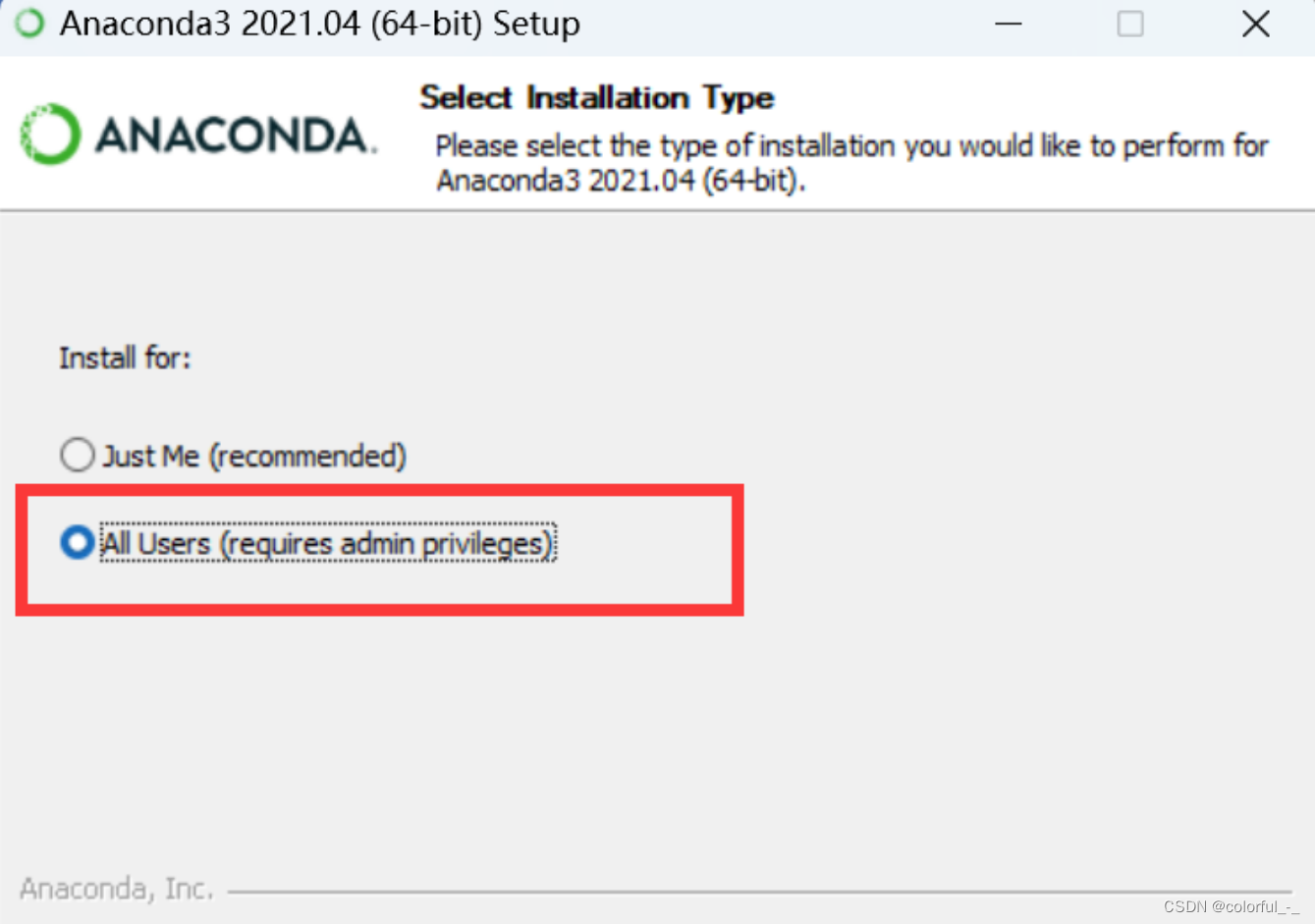
这里跳了一个“I agree”我想大家都知道,然后是注意这里:它默认是第一个!!!你选择All Users,然后next。
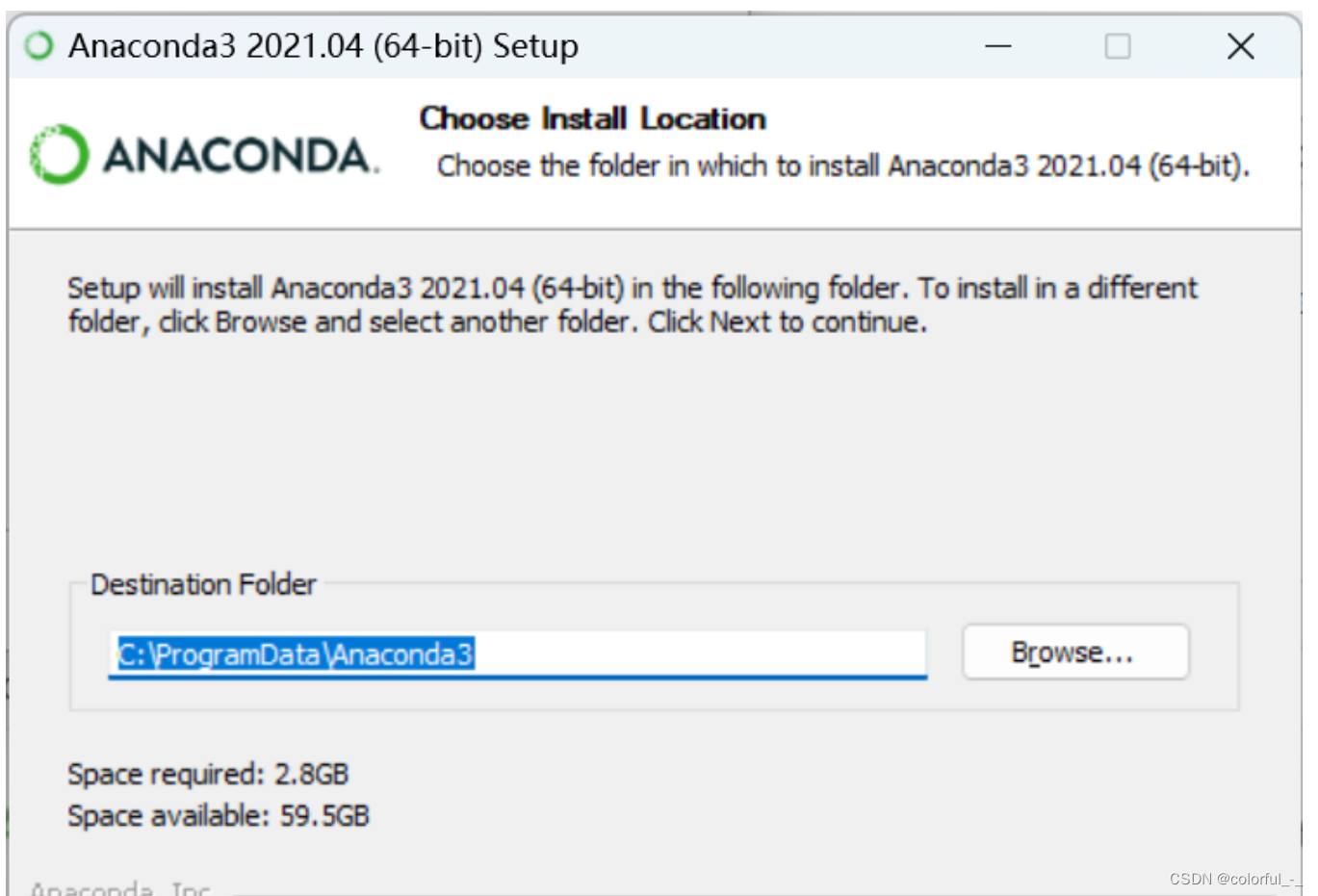
**!!!这里也是要注意的一个点:**第一个选项意思就是自动配置环境变量(觉得手动配置有难度的当然也可以直接勾选第一个,自动配置)
第二个选项是自己手动配置环境变量(后面有教程)。
第二个勾选默认的不用管。直接点击 Install
安装通义千问-1.8B
本想按照教程进行安装,执行到命令
pip install transformers==4.32.0 accelerate tiktoken einops scipy transformers_stream_generator==0.0.4 peft deepspeed
控制台提示需要cuda环境
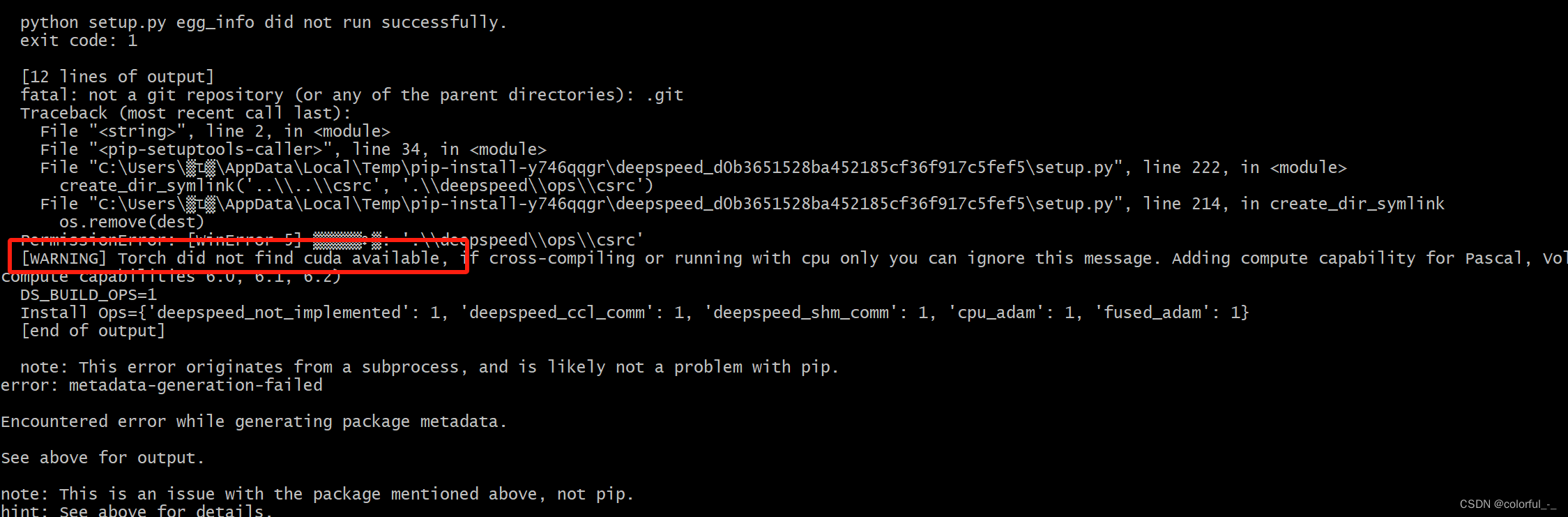
于是尝试以下方案。
为了避免其他的环境受影响,使用conda创新一个新环境。
创建环境
conda create -n chat python==3.9
激活环境
conda activate chat
配置环境
pip3 install torch torchvision torchaudio
pip3 install modelscope
pip3 install -U transformers
pip3 install accelerate
跑代码
from modelscope import AutoModelForCausalLM, AutoTokenizer
# 根据自己的设备调整device为cpu 或 cuda
device = "cpu" # the device to load the model onto
model = AutoModelForCausalLM.from_pretrained(
"qwen/Qwen1.5-0.5B-Chat",
device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained("qwen/Qwen1.5-0.5B-Chat")
prompt = "Give me a short introduction to large language model."
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(device)
generated_ids = model.generate(
model_inputs.input_ids,
max_new_tokens=512
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
print(response)
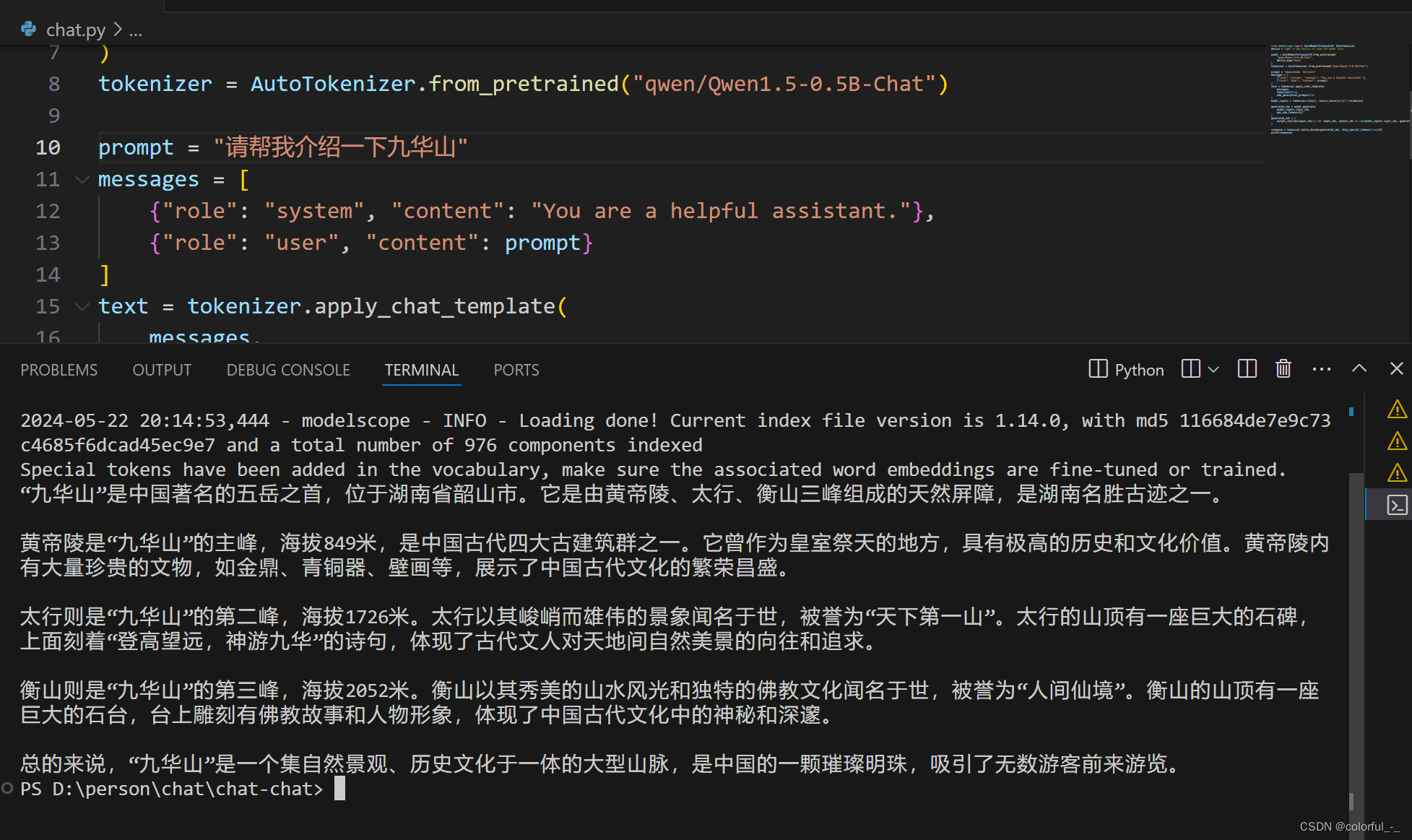
运行结果















 594
594











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









