









这篇文章主要记录对**Aspect level Sentiment Classification with HEAT ( HiErarchical ATtention )**论文的理解,主要说明其模型。
该模型提出了一个双层的Attention网络基于aspect word做分类,双层的Attention首先从句子中学习aspect信息,然后基于aspect和从句子中提取的aspect信息,关注特定的情感信息。如句子:
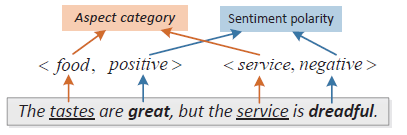
给定aspect词food,双层的Attention模型首先基于“food”关注单词“tastes”(aspect terms),之后基于aspect词"food"和“tastes”,找到词"great"。这样基于aspect terms,能更好的确定给定aspect的情感倾向。
一 Model
1.1 HEAT 网络结构
其结构图如下所示:

Input Model:输入模块将句子和aspect词编码为向量的形式
Hierarchical Attention Model:使用两层attenton获取aspect information(aspect attention层)和aspect-specfic sentiment information(sentiment attention层)
Sentiment Classfication Model:情感分类
1.2 Input Model
使用双向GRU模型学习句子的向量表示,其主要定义如下:

我们令:
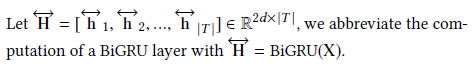
1.3 Hierarchical Attention Model
Aspect Attention
Aspect Attention找到可能的aspect terms,其输入是
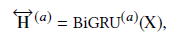
attention机制基于给定的aspect表示和句子的特征表示计算每个词的权重:
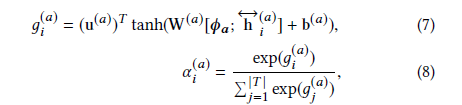

故最终句子的aspect information是对特征的权重累加:
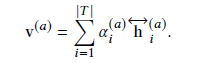
Sentiment attention
Sentiment attention基于aspect词和aspect information提取句子的情感特征。与aspect attention类似,其输入是BiGRU的输出
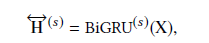
由于aspect information和sentiment information需要不同的特征,所以这两个GRU模型不共享参数。
之后基于句子的特征向量、aspect特征以及句子的aspect特征计算每个词的attention分数:
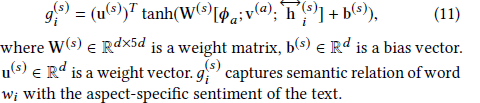
为了更好的计算attention权重,文章中考虑了aspect terms的局部信息(离aspect terms更近的情感词比远的要更重要)。使用location mask layer关注aspect terms的局部信息。用一个局部矩阵来实现:

这样离aspect term更近的词会有更大的权重,故sentiment attention分数计算为:
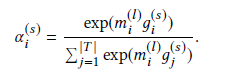
基于给定aspect句子的情感特征是句子特征的权重累加:
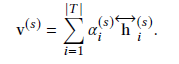
1.4 Setiment Classfication Model

二 核心代码
class HEAT(nn.Module):
def __init__(self, word_embed_dim, output_size, vocab_size, aspect_size, args=None):
super(HEAT, self).__init__()
self.input_size = word_embed_dim if (args.use_elmo == 0) else ( word_embed_dim + 1024 if args.use_elmo == 1 else 1024)
self.hidden_size = args.n_hidden
self.output_size = output_size
self.max_length = 1
self.lr = 0.0005
self.word_rep = WordRep(vocab_size, word_embed_dim, None, args)
self.rnn_a = nn.GRU(self.input_size, self.hidden_size // 2, bidirectional=True)
self.AE = nn.Embedding(aspect_size, word_embed_dim)
self.W_h_a = nn.Linear(self.hidden_size, self.hidden_size)
self.W_v_a = nn.Linear(word_embed_dim, self.input_size)
self.w_a = nn.Linear(self.hidden_size + word_embed_dim, 1)
self.W_p_a = nn.Linear(self.hidden_size, self.hidden_size)
self.W_x_a = nn.Linear(self.hidden_size, self.hidden_size)
self.rnn_p = nn.GRU(self.input_size, self.hidden_size // 2, bidirectional=True)
self.W_h = nn.Linear(self.hidden_size, self.hidden_size)
self.W_v = nn.Linear(word_embed_dim+self.hidden_size, word_embed_dim+self.hidden_size)
self.w = nn.Linear(2*self.hidden_size + word_embed_dim, 1)
self.W_p = nn.Linear(self.hidden_size, self.hidden_size)
self.W_x = nn.Linear(self.hidden_size, self.hidden_size)
self.decoder_p = nn.Linear(self.hidden_size+word_embed_dim, output_size)
self.dropout = nn.Dropout(args.dropout)
self.optimizer = torch.optim.Adam(self.parameters(), lr=self.lr)
def forward(self, input_tensors):
assert len(input_tensors) == 3
aspect_i = input_tensors[2]
#得到句子的特征表示
sentence = self.word_rep(input_tensors)
#句子的长度
length = sentence.size()[0]
#两个GRU:一个用于Aspect attention;一个用于Sentiment attention
output_a, hidden = self.rnn_a(sentence)
output_p, _ = self.rnn_p(sentence)
#[length,128]
output_a = output_a.view(output_a.size()[0], -1)
output_p = output_p.view(length, -1)
#主题词的特征向量表示[1,200]
aspect_e = self.AE(aspect_i)
aspect_embedding = aspect_e.view(1, -1)
#[length,200]把主题词扩大成句子的向量
aspect_embedding = aspect_embedding.expand(length, -1)
#得到aspect对于句子中每一词的权重[length,428]
M_a = F.tanh(torch.cat((output_a, aspect_embedding), dim=1))
#[1,length]
weights_a = F.softmax(self.w_a(M_a), dim=0).t()
# 得到基于主题词的句子aspect information[1,128]
r_a = torch.matmul(weights_a, output_a)
#sentiment attention
#[length,128]
r_a_expand = r_a.expand(length, -1)
#[length,328]
query4PA = torch.cat((r_a_expand, aspect_embedding), dim=1)
#[length,456]
M_p = F.tanh(torch.cat((output_p, query4PA), dim=1))
#[length,1]
g_p = self.w(M_p)
# print(g_p)
weights_p = F.softmax(g_p, dim=0).t()
#sentiment feature
r_p = torch.matmul(weights_p, output_p)
r = torch.cat((r_p, aspect_e), dim=1)
#输出
decoded = self.decoder_p(r)
ouput = decoded
return ouput















 1396
1396











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









