









这篇文章主要记录对Aspect Based Sentiment Analysis with Gated Convolutional Networks论文的理解,主要记录其模型和核心代码。
作者认为使用RNN和Attention会使模型的训练过程难以并行计算,影响了训练速度。本文提出了使用使用CNN和门控单元来提高速度,作者将Aspect Based Sentiment Analysis任务分为了两类Aspect-Term Sentiment Analysis(ATSA)任务和Aspect-Category Sentiment Analysis(ACSA)任务。
第一种叫做ACSA任务,即aspect-category sentiment analysis。该种任务的aspect是事先确定的一些类别,并且可能该aspect在句子中不出现,比如service,price这些,“这件衬衫居然要1000块钱!”就是针对“价格”的情感句,但是价格这个词并不会直接出现。
第二种叫做ATSA任务,即aspect-term sentiment analysis。与第一种相反,这种ABSA任务的aspect不是事先确定的,而是从句子中提取出来的,因此该种任务的aspect必然在句子中出现。比如评论“这些泰国菜非常好吃,但是配送太慢了!”。对于ACSA来说,这两个短句的aspect可能分别是“口感”、“服务”。对于ATSA来说,则是“泰国菜”,“配送”。
一 Model
对于ACSA任务来说,其模型如下图所示:

其实现主要如下所示:
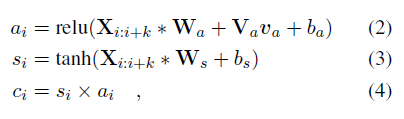
向量v_a是在ACSA中给定的aspect category特征或者是在ATSA中通过CNN得到的式aspect terms。(2)和(3)是两个卷积操作,式(2)多加了aspect information,并使用ReLU激活函数。
使用Tanh-ReLU门结构单元根据给定的aspect或者entity选择性输出情感信息。对于ReLU门来说对于负数其输出是0,正值没有上界。
之后通过一个最大池化层产生一个固定大小的向量
最后是全连接层使用softmax分类器输出预测值。使用交叉熵损失训练模型。
ATSA模型:

二 核心代码
class GCAE(nn.Module):
def __init__(self, word_embed_dim, output_size, vocab_size, aspect_size, args=None):
super(GCAE, self).__init__()
self.args = args
self.input_size = word_embed_dim if (args.use_elmo == 0) else ( word_embed_dim + 1024 if args.use_elmo == 1 else 1024)
V = vocab_size
D = self.input_size
#3
C = output_size
#10
A = aspect_size
Co = 100
Ks = [2,3,4]
self.word_rep = WordRep(V, word_embed_dim, None, args)
self.AE = nn.Embedding(A, word_embed_dim)
#[300,100,Ks]
self.convs1 = nn.ModuleList([nn.Conv1d(D, Co, K) for K in Ks])
self.convs2 = nn.ModuleList([nn.Conv1d(D, Co, K) for K in Ks])
self.fc1 = nn.Linear(len(Ks) * Co, C)
self.fc_aspect = nn.Linear(word_embed_dim, Co)
def forward(self, input_tensors):
# 将句子表示为嵌入的形式[length,1,300]
feature = self.word_rep(input_tensors)
#主题嵌入
aspect_i = input_tensors[2]
#将主题表示为嵌入的形式[1,300]
aspect_v = self.AE(aspect_i) # (N, L', D)
#展开为一维向量的形式[1,length,300]
feature = feature.view(1, feature.size()[0], -1)
#feature.transpose(1, 2):[1,300,length]
#self.convs:[[[300,100,2],[[300,100,3],[[300,100,4]]]
# print(self.convs1[0](feature.transpose(1,2)).size())[1,100,8]
# print(self.convs1[1](feature.transpose(1,2)).size())[1,100,7]
# print(self.convs1[2](feature.transpose(1,2)).size())[1,100,6]
x = [F.tanh(conv(feature.transpose(1, 2))) for conv in self.convs1] # [(N,Co,L), ...]*len(Ks)
# self.fc_aspect(aspect_v):[1,100]
# self.fc_aspect(aspect_v).unsqueeze(2)[1,100,1]
#[[1,100,8],[1,100,7],[1,100,6]]
y = [F.relu(conv(feature.transpose(1, 2)) + self.fc_aspect(aspect_v).unsqueeze(2)) for conv in self.convs2]
#[[1,100,8],[1,100,7],[1,100,6]]
x = [i * j for i, j in zip(x, y)]
# pooling method
x0 = [F.max_pool1d(i, i.size(2)).squeeze(2) for i in x] # [(N,Co), ...]*len(Ks)
x0 = [i.view(i.size(0), -1) for i in x0]
x0 = torch.cat(x0, 1)
print("x0:",x0.size())
logit = self.fc1(x0) # (N,C)
return logit















 2877
2877











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









