







 文章探讨了基于用户生成内容(UGC)的推荐系统,指出简单算法存在的问题,如热门标签和物品权重过高影响个性化和新颖性。引入TF-IDF技术,通过计算标签的词频和逆文档频率,以平衡热门元素的影响,提高推荐的准确性和多样性。
文章探讨了基于用户生成内容(UGC)的推荐系统,指出简单算法存在的问题,如热门标签和物品权重过高影响个性化和新颖性。引入TF-IDF技术,通过计算标签的词频和逆文档频率,以平衡热门元素的影响,提高推荐的准确性和多样性。
基于 UGC 的推荐
用户用标签来描述对物品的看法,所以用户生成标签(UGC)是联系用户和物品的纽带,也是反应用户兴趣的重要来源
一个用户标签行为的数据集一般由三元素(用户,物品,标签)的集合表示,其中一条记录(u,i,b)表示用户u给物品i打上了标签b;
一个最简单的算法
统计每个用户最常用的标签
对于每个标签,统计被打过这个标签次数最多的物品
对于一个用户,首先找到他常用的标签,然后找到具有这些标签的最热门的物品,推荐给他
所以用户u对物品i的兴趣公式为
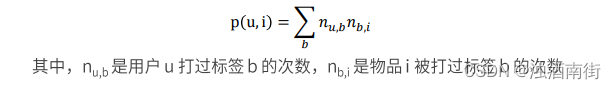
基于 UGC 简单推荐的问题
简单算法中直接将用户打出标签的次数和物品得到的标签次数相乘,可以简单地表现出用户对物品某个特征的兴趣
这种方法会倾向于给热门的标签、热门物品比较大的权重,如果一个热门物品同时对应着热门标签,那它就会霸榜,推荐的个性化、新颖度就会下降;
类似的问题,出现在新闻内容的关键字提取中。
TF-IDF
词频-逆文档频率(Term Frequency-Inverse Document Frequency,TF-IDF)是一种用于资讯检索与文本挖掘的常用加权技术;
TF-IDF是一种统计方法,用以评估一个字词对于一个文件集或一个语料库的其中一份文件的重要程度。字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降;
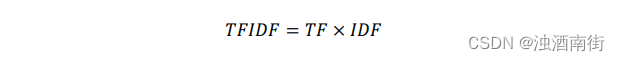
TF-IDF的主要思想是:如果某个词或短语在一篇文章中出现的频率TF高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类;
TF-IDF加权的各种形式被搜素引擎应用,作为文件与用户查询之间相关程度的度量或评级;
词频(Term Frequency,TF):
指的是某一个给定的词语在该文件中出现的频率。这个数字是对词数的归一化,以防止偏向更长的文件。(同一个词语在长文件里可能会比短文件有更高的词数,而不管该词语是否重要)

逆向文件频率(Inverse Document Frequency,IDF)
是一个词语普遍重要性的度量,某一特定词语的IDF,可以由总文档数目除以包含该词语之文档的数目,再将得到的商取对数得到

TF-IDF 对基于 UGC 推荐的改进
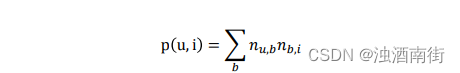
为了避免热门标签和热门物品获得更多的权重,我们需要对‘热门’进行惩罚
借鉴TF-IDF的思想,以一个物品的所有标签作为‘文档’,标签作为‘词语’,从而计算标签的‘词频’(在物品所有标签中的频率)和‘逆文档频率’(在其他物品标签中出现的频率)
由于‘物品i的所有标签’应该对标签权重没有影响,而‘所有标签总数’ N对于所有标签是一定的,所以这两项可以略去。在简单算法的基础上,直接加入对热门标签和热门物品的惩罚项:


















 1698
1698

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









