







评价模型好坏
1. 数据拆分
数据拆分,即划分训练数据集&测试数据集
现在也多直接调用sklearn中的库
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=10)
"注意X_train, X_test, y_train, y_test顺序"
2. 评价分类结果
2.1 准确度(accuracy)
accuracy_score:函数计算分类准确率,返回被正确分类的样本比例(default)或者是数量(normalize=False)
from sklearn.metrics import accuracy_score

但是它在某些情况下并不一定是评估模型的最佳工具。比如一个经典例子—癌症预测系统,如果癌症的发病率只有百分之0.1,那么只要系统都预测成健康,那么准确就达到了99.9%,但是这样的系统基本上没有什么价值,因为我们关注的是比较少的那一部分样本,但是这一部分样本,并没有预测出来。
这是就需要使用混淆矩阵(Confusion Matrix)做进一步分析。
2.2 混淆矩阵(Confusion Matrix)
from sklearn.metrics import confusion_matrix
对于二分类问题来说,所有的问题被分为0和1两类,混淆矩阵是2*2的矩阵:
| 预测值0 | 预测值1 | |
|---|---|---|
| 真实值0 | TN | FP |
| 真实值1 | FN | TP |

- TN:真实值是0,预测值也是0,即我们预测是Negative,预测True
- FP:真实值是0,预测值是1,即我们预测是Positive,但是预测False
- FN:真实值是1,预测值是0,即我们预测是Negative,但预测False
- TP:真实值是1,预测值是1,即我们预测是Positive,预测True
现在假设有1万人进行预测,填入混淆矩阵如下:
| 预测值0 | 预测值1 | |
|---|---|---|
| 真实值0 | 9978 | 12 |
| 真实值1 | 2 | 8 |
对于1万个人中,有9978个人本身并没有癌症,我们的算法也判断他没有癌症;有12个人本身没有癌症,但是我们的算法却错误地预测他有癌症;有2个人确实有癌症,但我们算法预测他没有癌症;有8个人确实有癌症,而且我们也预测对了。
2.3 精确率(precision)
from sklearn.metrics import precision_score

| 预测值0 | 预测值1 | |
|---|---|---|
| 真实值0 | 9978 | 12 |
| 真实值1 | 2 | 8 |
根据混淆矩阵可求得精确率:$\ precision = \frac{11}{11+01}=\frac{TP}{TP+FP} $ ,即精准率为8/(8+12)=40%。所谓的精准率是:分母为所有预测为1的个数,分子是其中预测对了的个数,即预测值为1,且预测对了的比例。
在有偏的数据中,我们通常更关注值为1的特征,比如“患病”,比如“有风险”。在100次结果为患病的预测,平均有40次预测是对的。即精准率为我们关注的那个事件,预测的有多准。并且,当每一次将多数类判断错误的成本特别高时(例如大众召回车辆的例子),不希望有将多数类误判的情况,会追求高精确率。
2.4 召回率(recall)
from sklearn.metrics import recall_score

| 预测值0 | 预测值1 | |
|---|---|---|
| 真实值0 | 9978 | 12 |
| 真实值1 | 2 | 8 |
根据混淆矩阵也可求得召回率:$\ recall = \frac{11}{11+10}= \frac{TP}{TP+FN} $,即召回率为8/(8+2)=80%。所谓召回率是:所有真实值为1的数据中,预测对了的个数。每当有100个癌症患者,算法可以成功的预测出80个 。召回率也就是我们关注的那个事件真实的发生情况下,我们成功预测的比例是多少。而且,如果我们希望不计一切代价,找出少数类(比如找出潜在犯罪者的例子),那我们就会追求高召回率。
2.5 F1-measure
为了同时兼顾精确度和召回率,我们创造了两者的调和平均数作为考量两者平衡的综合性指标,称之为F1-measure。我们追求尽量高的F1 measure,能够保证我们的精确度和召回率都比较高。F1 measure在[0,1]之间分布,越接近1越好。
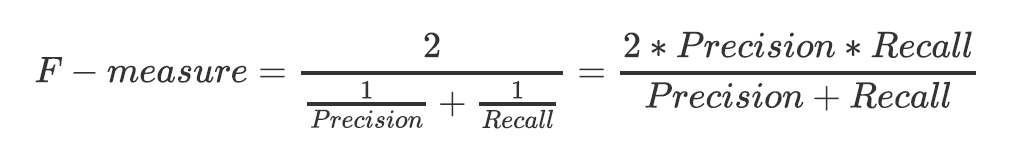
2.6 假负率(FNR)
从Recall延申出来的另一个评估指标叫做假负率FNR(False Negative Rate)$\ FNR = \frac{10}{11+10} $,它等于 1 - Recall,用于衡量所有真实为1的样本中,被我们错误判断为0的。
2.7 特异度(Specificity)

特异度(Specificity)$Specificity= \frac{00}{01+00} $表示所有真实为0的样本中,被正确预测为0的样本所占的比例,特异度衡量了一个模型将多数类判断正确的能力。
2.8 假正率(FPR)

假正率(False Positive Rate)$FPR= \frac{01}{01+00} $就是1 - specificity,为一个模型将多数类判断错误的能力。
2.9 ROC曲线
from sklearn.metrics import roc_curve
我们使用Recall和FPR之间的平衡,来替代Recall和Precision之间的平衡,让我们衡量模型在尽量捕捉少数类的时候,误伤多数类的情况如何变化,这就是我们的ROC曲线衡量的平衡。ROC曲线(Receiver Operation Characteristic Cureve),描述TPR(recall)和FPR之间的关系。x轴是FPR,y轴是TPR。
TPR就是所有正例(少数类)中,有多少被正确地判定为正(决策边界上方的所有红色点占全部样本中的红色点的比例);FPR是所有负例(多数类)中,有多少被错误地判定为正(决策边界上方的紫色点占所有紫色点的比例)。TPR越大越好,FPR越小越好,但这两个指标通常是矛盾的。为了增大TPR,可以预测更多的样本为正例,与此同时也增加了更多负例被误判为正例的情况。

2.10 AUC面积
from sklearn.metrics import roc_auc_score as AUC
一般在ROC曲线中,我们关注是曲线下面的面积, 称为AUC(Area Under Curve)。ROC和AUC的主要应用:比较两个模型哪个好?主要通过AUC能够直观看出来。















 664
664











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









