







机器学习
没有免费午餐定理和三大机器学习任务
如何对模型进行评估
K-Means(K均值聚类)原理及代码实现
KNN(K最近邻算法)原理及代码实现
KMeans和KNN的联合演习
一、一些概念
- 错误率(error rate):在n个样本中有a个错误数据,则 E = a m E=\frac{a}{m} E=ma 。
- 精度(accuracy): A c = ( 1 − E ) × 100 Ac=(1−E)×100 Ac=(1−E)×100%。
- 训练误差/经验误差(training error/empirical error):在训练集上的误差。
- 泛化误差(generalization error):在新样本(测试集)上的误差。
- 过拟合(overfitting):把训练集自身的特点当作了所有潜在样本都会具有的特点。过拟合是机器学习的关键障碍,过拟合是无法避免只能缓解的。
- 欠拟合(underfitting):对训练集的一般性质尚未学习好。
二、评估方法
测试集和训练集应该尽可能互斥。
“没有免费午餐”定理对评估方法同样适用。
表示:
D-数据集
S-训练集
T-测试集
1. 留出法(hand-out): 将
D
D
D 划分为互斥的
S
S
S 和
T
T
T 。
即:
D
=
S
∪
T
,
S
∩
T
=
∅
D=S∪T, S∩T=∅
D=S∪T,S∩T=∅
E
=
T
(
e
r
r
)
s
i
z
e
(
T
)
E=\frac{T(err)}{size(T)}
E=size(T)T(err)
T
(
e
r
r
)
T(err)
T(err) 是在T中错误样本的数据。
注意:
(1) 划分时应尽可能保证数据分布的一致性,避免因数据划分引入额外的偏差(采用分层抽样法)。
(2) 单词使用留出法的结果并不可靠,应该采用若干次随机划分重复进行实验评估后取均值。
缺点:
(1)
S
S
S 越大,训练结果越接近
D
D
D,但是
T
T
T小,评估不够准确,稳定。
(2)
T
T
T 大一些,
S
S
S 的结果不接近
D
D
D,降低了保真性(fidelity)。常用
2
3
\frac{2}{3}
32~
4
5
\frac{4}{5}
54 用于
S
S
S。
2. 交叉验证法(cross validation): 将
D
D
D 划分为
k
k
k 个大小相似的互斥子集。
即:
D
=
D
1
∪
D
2
∪
D
3
∪
…
∪
D
k
,
D
i
∩
D
j
=
∅
(
i
≠
j
)
D=D_1∪D_2∪D_3∪…∪D_k, D_i∩D_j=∅ (i≠j)
D=D1∪D2∪D3∪…∪Dk,Di∩Dj=∅(i=j)
进行 k k k 次训练,每次用 k − 1 k−1 k−1 个子集作为 S S S,余下的一个子集作为 T T T。( k k k折交叉验证 k-fold cross validation)。
注意:
(1) 尽可能保证数据分布的一致性。
(2) 评估结果的稳定性和保真性在很大程度上取决于
k
k
k值,
k
k
k一般选用5、10、20。
(3) 单次不可靠,随机划分重复
p
p
p次,取
p
p
p次
k
k
k折交叉验证结果的均值。(10次10折=训练100次)
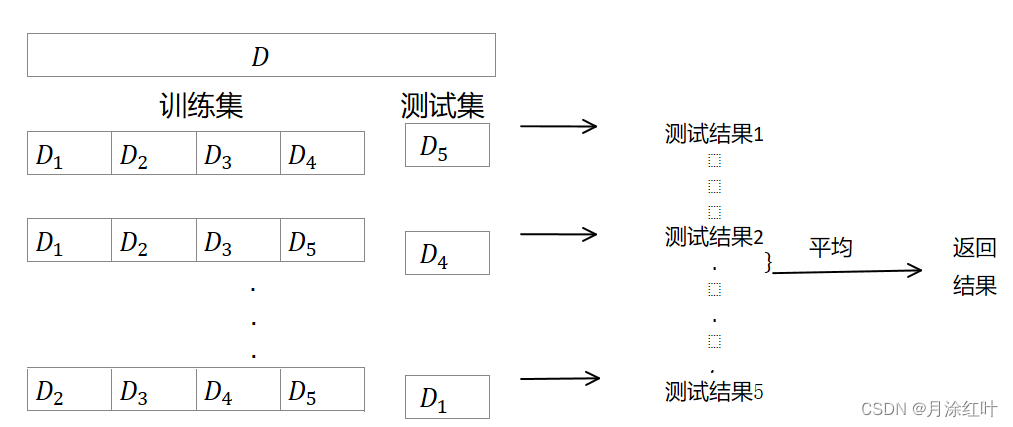
2.1. 留一法(leave-One-Out):
m
m
m 是
D
D
D 的大小,
k
=
m
k=m
k=m 时,得到留一法。
注意:它不受随机样本划分方式的影响。
优点:由于
S
S
S 接近
D
D
D,所以它的评估结果比较准确。
缺点:
m
m
m 越大,开销越大。
3. 自助法(bootstrapping): 从
D
D
D中多次随机可重复复制
m
m
m个样本组成数据集
D
′
D′
D′。(
D
D
D 中有一部分样本会在
D
′
D′
D′ 中多次出现,而一部分不会出现)样本在
m
m
m 次采样中,不被采集到的概率是:
lim
m
→
0
(
1
−
1
m
)
m
=
1
e
≈
0.368
\lim_{m\rightarrow 0}(1-\frac{1}{m})^m=\frac{1}{e}\approx0.368
m→0lim(1−m1)m=e1≈0.368即:
D
D
D 中约有36.8%的样本未出现在
D
′
D′
D′ 中。
S
=
D
′
,
T
=
D
−
D
′
S=D′, T=D−D′
S=D′,T=D−D′实际评估模型和期望评估模型都使用m个样本,而有约
1
3
\frac{1}{3}
31 的未出现在在
S
S
S 中的样本用于测试——外包估计(out-of-bag estimate)。
优点:
(1) 在
D
D
D 较小,难以划分
S
/
T
S/T
S/T 时很有用。
(2) 能从
D
D
D 中产生多个不同的
S
S
S。
缺点:
改变了
D
D
D 的分布,会引入估计偏差。
D
D
D 足量时,留出法和交叉验证法更常用。
三、调参:
(1) 常对每个调整的参数设定一个范围和变化步长。
(2) 在模型、算法和参数选定后,用
D
D
D 重新训练。















 439
439











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









