







Video captioning的定义
为一张图片产生一个描述被称为image caption任务,为一个视频产生一个描述成为vedio caption,但视频可以理解为在时间上有连续性的一组图片,因此可以理解成为一组图片产生一个描述。
vedio caption是属于对vedio analysis的高层语义分析。
描述一般描述两个方向,属性和相互关系。
三种基本方法:
- 基于模版的方法,较为简单,caption质量在很大程度上取决于句子的模板,句子用句法结构生成,多样性较差。
- 基于检索的方法,一般来说,这个方法在固定场景内的视频中是有效的,因为嵌入空间可以很好地推广,并且更丰富的模型结构提高了性能。 然而,当遇到以前从未见过的情况的视频时,效果会很差。 此外,由于嵌入是固定长度的,因此它限制了视频和文本描述可以携带的信息量。
- 基于编码的方法, 更正式地说,这些工作提出的框架是一个编码器 - 解码器结构,它将视频编码为语义表示特征向量,然后解码为自然语言。
主要技术(attention,3D conv)
双流法
光流表达了图像的变化,由于它包含了目标运动的信息,因此可被观察者用来确定目标的运动情况,每张图像中每个像素的运动速度和运动方向找出来就是光流场。

采用双通道CNN的方式,对光流和图片同时处理得到结果,最后fusion一起。
一般的光流图为双通道的信息,分别为在X轴上的信息变化与Y轴上的信息变化。光流图是选择视频中的任意一帧的时间然后及其后面的N帧叠合成一个光流栈进入处理。
3D卷积
由于视频帧之间具有时间连续性,普通的2D卷积不能够充分表达这个特性,因此把相邻的几个帧合在一起组成一个具有三个维度的输入向量,同时在这三个维度进行卷积。
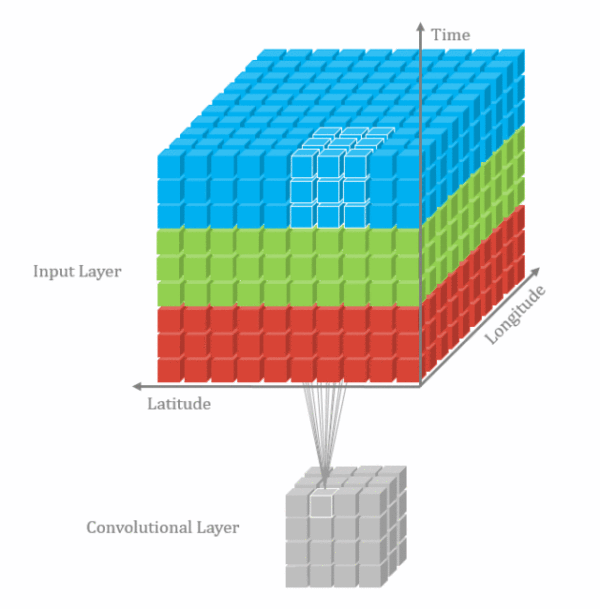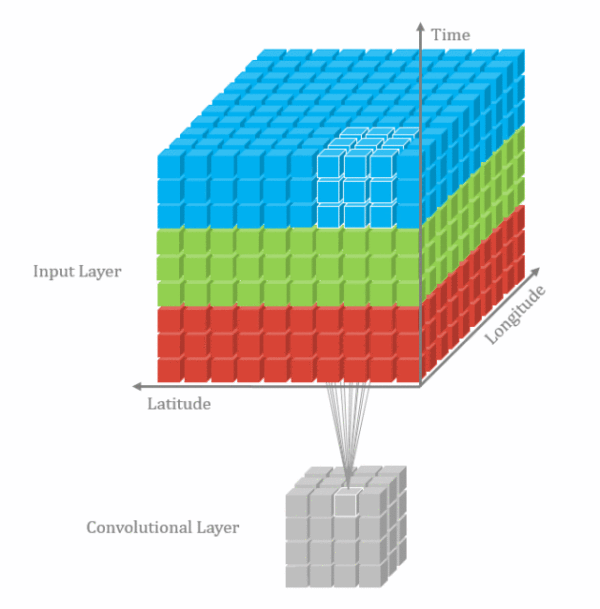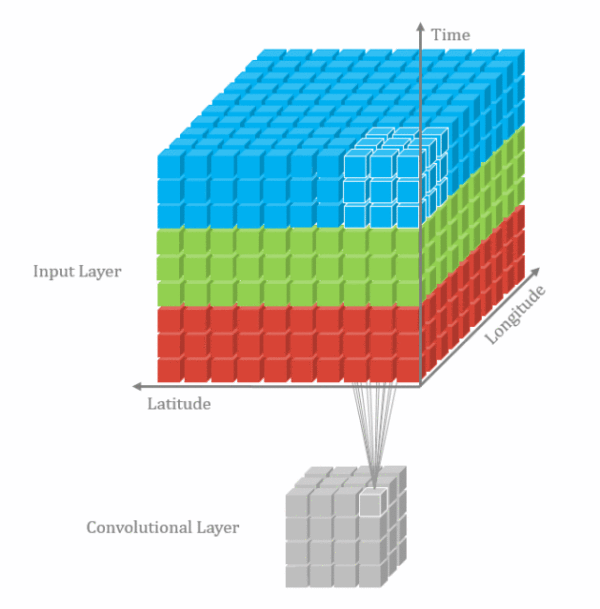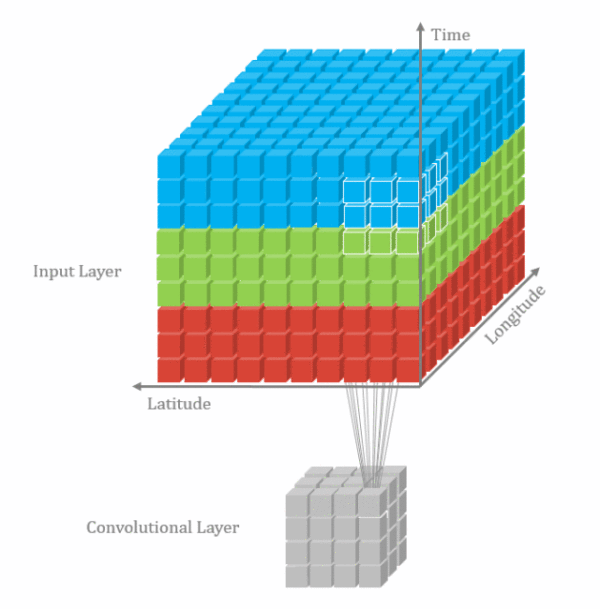
3D卷积也只是一种增加时间信息的补充手段,实际使用中2D卷积的结果+3D卷积结果fusion一起的效果更好。
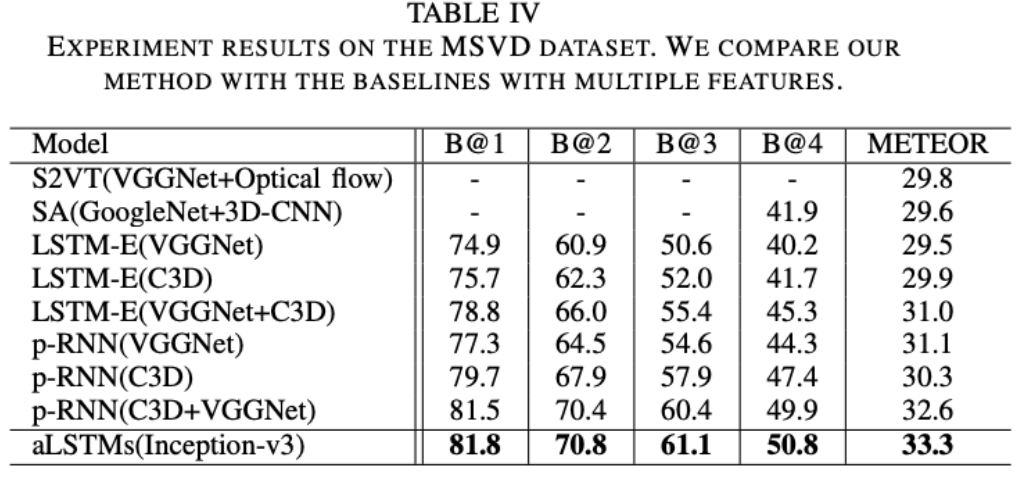
从LSTM-E和p-RNN的结果可以看出,视频处理中,3D卷积效果好于2D卷积,二者结合一起,效果更好。<
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









