









AS-Net是2021年提出的一个HOI模型,就本人理解而言,是对HOTR的一个改进吧,HOTR用指针,将实例和动作联系起来了,并把三元组预测认为是一个集合预测问题。而AS-Net在介绍里说自己把HOI预测重构成一个自适应的集合预测。
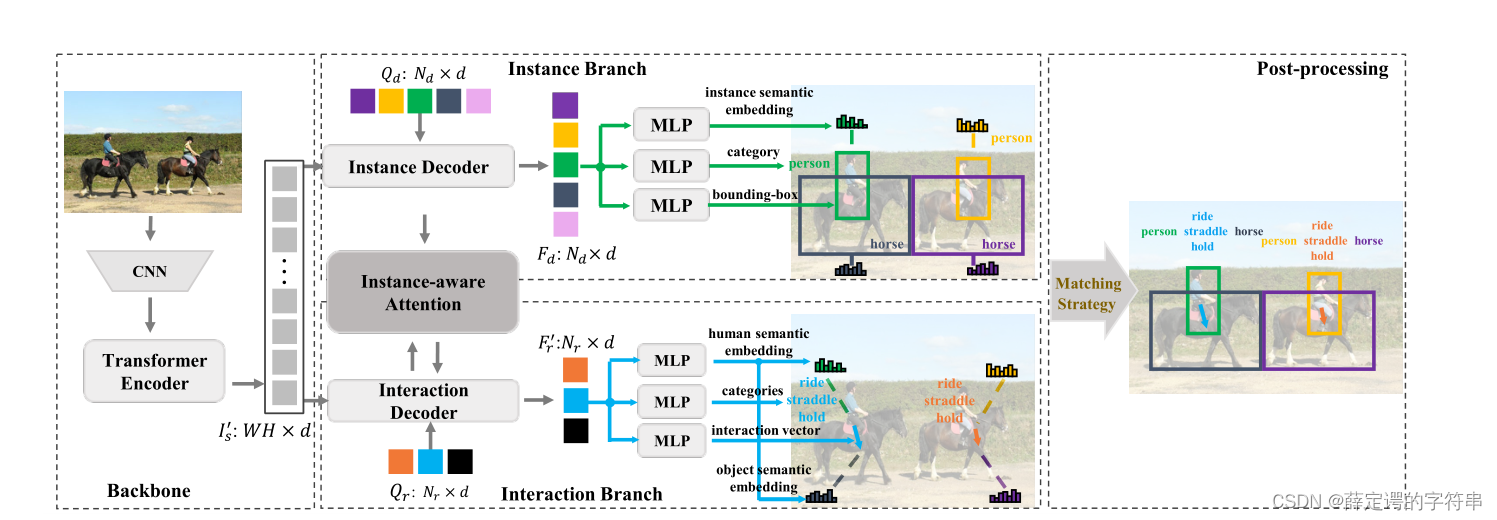 和HOTR类似,它为了将实例和动作联系起来,就在两个并行的解码器中间加了个实例感知注意力。其实现在的理解来看,就是通过这个实例感知注意力,将实例和动作对应的权重进行分配,来达到预测三元组类似的结果。
和HOTR类似,它为了将实例和动作联系起来,就在两个并行的解码器中间加了个实例感知注意力。其实现在的理解来看,就是通过这个实例感知注意力,将实例和动作对应的权重进行分配,来达到预测三元组类似的结果。
模型的同样是先将图片进行CNN得到特征,放入共享的编码器后,通过自注意力机制细化后,得到一组共享的向量I‘s。
1、实例层的组成
与DETR类似,以一组可以学习的位置嵌入序列作为query,以刚才经过编码器得到的向量I’s作为key经过co-attention,得到的pre为Fd,将Fd输入到3个感知层,得到实例的语义嵌入、类别和一个预测区域。
2、交互层
也是把经过编码器得到的向量I’s作为key,将一组可以学习的位置嵌入序列作为query,得到的Fr‘’输入到3个MLP,得到动作的类别预测,属于交互类别预测得到的人的语义嵌入和目标的语义嵌入。
动作感知注意力模块
首先计算一个亲和力得分图
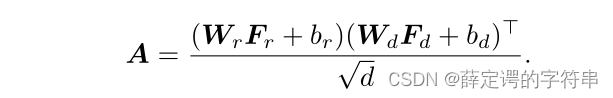
其中两个Wr,Wd和br、bd是一个可以学习的向量,第一个矩阵乘以另一个矩阵的转置,本质上还是算余弦值,算的是向量的相似度。得到的亲和力矩阵经过softmax把数值固定在【0,1】之间,就可以计算
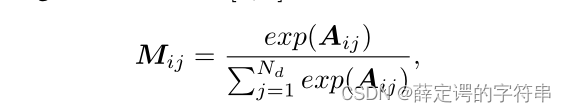
Mij代表的意思是第j个预测实例相对于第i个预测实例的关注度,即权重。有了权重,就可以计算最后的输出的交互向量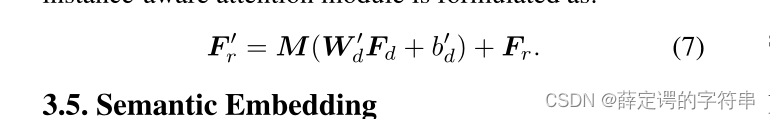
这个经过权重变换后的交互特征,实例和特定动作是相联系的。
这里在计算损失的时候,也用来计算了push损失和pull损失。
其中push损失定义是
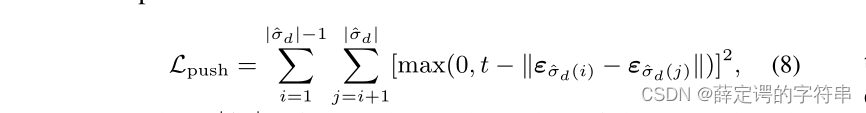
各个实例之间推开的距离,t是 超参数,是一个预定义的阈值,超过t,则push损失为0,相减的两个变量都是来自实例分支中的向量Fd。
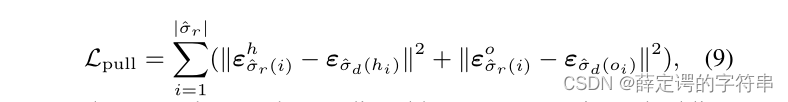
还要计算一个pull损失,其中第一个变量是交互分支中的人实例向量,第二个是实例分支中对应的人实例向量,第三个向量是交互分支的目标特征,第四个实例分支中的对应的目标特征。
最后的匹配策略:
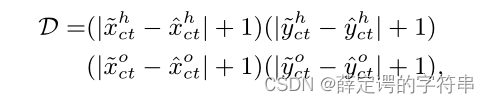
采用交互向量中对应位置减去交互分支预测的人和物体实例的中心点
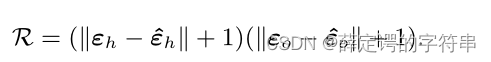
这个R是由上述的两个分支的val得到的 向量算出
最后分数是这个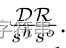














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









