







LLM非常擅长将输入转换成不同的格式,例如多语种文本翻译、拼写及语法纠正、语气调整、格式转换等。
文章目录
1、文本翻译
1.1、中文转西班牙语
prompt = f"""
将以下中文翻译成西班牙语: \
```您好,我想订购一个搅拌机。```
"""
输出:
Hola, me gustaría ordenar una batidora.
1.2、识别语种
prompt = f"""
请告诉我以下文本是什么语种:
```Combien coûte le lampadaire?```
"""
输出:
这是法语。
1.3、多语种翻译
prompt = f"""
请将以下文本分别翻译成中文、英文、法语和西班牙语:
```I want to order a basketball.```
"""
输出:
中文:我想订购一个篮球。
英文:I want to order a basketball.
法语:Je veux commander un ballon de basket.
西班牙语:Quiero pedir una pelota de baloncesto.
1.4、翻译+正式语气
prompt = f"""
请将以下文本翻译成中文,分别展示成正式与非正式两种语气:
```Would you like to order a pillow?```
"""
输出:
正式语气:请问您需要订购枕头吗?
非正式语气:你要不要订一个枕头?
1.4、通用翻译器
- 随着全球化与跨境商务的发展,交流的用户可能来自各个不同的国家,使用不同的语言,因此我们需要一个通用翻译器,识别各个消息的语种,并翻译成目标用户的母语,从而实现更方便的跨国交流。
user_messages = [
"La performance du système est plus lente que d'habitude.", # System performance is slower than normal
"Mi monitor tiene píxeles que no se iluminan.", # My monitor has pixels that are not lighting
"Il mio mouse non funziona", # My mouse is not working
"Mój klawisz Ctrl jest zepsuty", # My keyboard has a broken control key
"我的屏幕在闪烁" # My screen is flashing
]
for issue in user_messages:
prompt = f"告诉我以下文本是什么语种,直接输出语种,如法语,无需输出标点符号: ```{issue}```"
lang = chatgpt(prompt)
print(f"原始消息 ({lang}): {issue}\n")
prompt = f"""
将以下消息分别翻译成英文和中文,并写成
中文翻译:xxx
英文翻译:yyy
的格式:
```{issue}```
"""
response = chatgpt(prompt)
print(response, "\n=========================================")
输出:
原始消息 (法语): La performance du système est plus lente que d'habitude.
中文翻译:系统性能比平时慢。
英文翻译:The system performance is slower than usual.
=========================================
原始消息 (西班牙语): Mi monitor tiene píxeles que no se iluminan.
中文翻译:我的显示器有一些像素点不亮。
英文翻译:My monitor has pixels that don't light up.
=========================================
原始消息 (意大利语): Il mio mouse non funziona
中文翻译:我的鼠标不工作了。
英文翻译:My mouse is not working.
=========================================
原始消息 (波兰语): Mój klawisz Ctrl jest zepsuty
中文翻译:我的Ctrl键坏了
英文翻译:My Ctrl key is broken.
=========================================
原始消息 (中文): 我的屏幕在闪烁
中文翻译:我的屏幕在闪烁。
英文翻译:My screen is flickering.
=========================================
2、语气 / 风格调整
写作的语气往往会根据受众对象而有所调整。
prompt = f"""
将以下文本翻译成商务信函的格式:
```小老弟,我小羊,上回你说咱部门要采购的显示器是多少寸来着?```
"""
输出:
尊敬的XXX(收件人姓名):
您好!我是XXX(发件人姓名),在此向您咨询一个问题。上次我们交流时,您提到我们部门需要采购显示器,但我忘记了您所需的尺寸是多少英寸。希望您能够回复我,以便我们能够及时采购所需的设备。
谢谢您的帮助!
此致
敬礼
XXX(发件人姓名)
3、格式转换
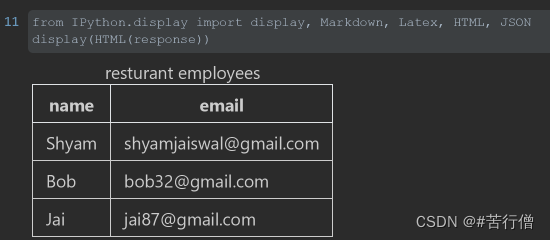
ChatGPT非常擅长不同格式之间的转换,例如JSON到HTML、XML、Markdown等。
json转html:
data_json = { "resturant employees" :[
{"name":"Shyam", "email":"shyamjaiswal@gmail.com"},
{"name":"Bob", "email":"bob32@gmail.com"},
{"name":"Jai", "email":"jai87@gmail.com"}
]}
prompt = f"""
将以下Python字典从JSON转换为HTML表格,保留表格标题和列名:{data_json}
"""
输出:
<table>
<caption>resturant employees</caption>
<thead>
<tr>
<th>name</th>
<th>email</th>
</tr>
</thead>
<tbody>
<tr>
<td>Shyam</td>
<td>shyamjaiswal@gmail.com</td>
</tr>
<tr>
<td>Bob</td>
<td>bob32@gmail.com</td>
</tr>
<tr>
<td>Jai</td>
<td>jai87@gmail.com</td>
</tr>
</tbody>
</table>
4、拼写及语法纠正
以下给了一个例子,有一个句子列表,其中有些句子存在拼写或语法问题,有些则没有,我们循环遍历每个句子,要求模型校对文本,如果正确则输出“未发现错误”,如果错误则输出纠正后的文本。
text = [
"The girl with the black and white puppies have a ball.", # The girl has a ball.
"Yolanda has her notebook.", # ok
"Its going to be a long day. Does the car need it’s oil changed?", # Homonyms
"Their goes my freedom. There going to bring they’re suitcases.", # Homonyms
"Your going to need you’re notebook.", # Homonyms
"That medicine effects my ability to sleep. Have you heard of the butterfly affect?", # Homonyms
"This phrase is to cherck chatGPT for spelling abilitty" # spelling
]
for i in range(len(text)):
prompt = f"""请校对并更正以下文本,注意纠正文本保持原始语种,无需输出原始文本。
如果您没有发现任何错误,请说“未发现错误”。
例如:
输入:I are happy.
输出:I am happy.
```{text[i]}```"""
response = chatgpt(prompt)
print(i, response)
输出:
0 The girl with the black and white puppies has a ball.
1 未发现错误。
2 It's going to be a long day. Does the car need its oil changed?
3 Their goes my freedom. They're going to bring their suitcases.
4 输出:You're going to need your notebook.
5 That medicine affects my ability to sleep. Have you heard of the butterfly effect?
6 This phrase is to check chatGPT for spelling ability.
5、一个综合样例:文本翻译+拼写纠正+风格调整+格式转换
text = f"""
Got this for my daughter for her birthday cuz she keeps taking \
mine from my room. Yes, adults also like pandas too. She takes \
it everywhere with her, and it's super soft and cute. One of the \
ears is a bit lower than the other, and I don't think that was \
designed to be asymmetrical. It's a bit small for what I paid for it \
though. I think there might be other options that are bigger for \
the same price. It arrived a day earlier than expected, so I got \
to play with it myself before I gave it to my daughter.
"""
prompt = f"""
针对以下三个反引号之间的英文评论文本,
首先进行拼写及语法纠错,
然后将其转化成中文,
再将其转化成优质淘宝评论的风格,从各种角度出发,分别说明产品的优点与缺点,并进行总结。
润色一下描述,使评论更具有吸引力。
输出结果格式为:
【优点】xxx
【缺点】xxx
【总结】xxx
注意,只需填写xxx部分,并分段输出。
将结果输出成Markdown格式。
```{text}```
"""
输出:
【优点】 - 超级柔软可爱,女儿生日礼物非常受欢迎。 - 成人也喜欢熊猫,我也很喜欢它。 - 提前一天到货,让我有时间玩一下。
【缺点】 - 一只耳朵比另一只低,不对称。 - 价格有点贵,但尺寸有点小,可能有更大的同价位选择。
【总结】 这只熊猫玩具非常适合作为生日礼物,柔软可爱,深受孩子喜欢。虽然价格有点贵,但尺寸有点小,不对称的设计也有点让人失望。如果你想要更大的同价位选择,可能需要考虑其他选项。总的来说,这是一款不错的熊猫玩具,值得购买。
参考链接:
[1] OpenAI
[2] 吴恩达老师的:DeepLearning.AI
[3] DataWhale
[4] https://learn.deeplearning.ai/


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











