







监督学习
监督学习:监督学习的数据集一般含有许多特征和属性,数据集中的样本都带有标签和目标值。监督学习的任务就是根据这些标签,学习和调整分类器的参数,使其达到所要求性能的过程,换而言之,由已知推出未知。
1. 线性模型
线性模型的任务:对于给定的数据集,学习到一个模型或者函数f(x),使对于任意输入特征向量x=(x1,x2,…)T,f(x)能表示为xi的线性函数,即满足:

线性模型用于分类和回归等任务,包括线性回归和逻辑回归等下面介绍线性回归和逻辑回归的区别以及联系
1.1线性回归
线性回归:是回归学习其中的一种,其任务就是在给定的数据集D中,通过学习得到一个线性模型或线性函数f(x)。输入数据集一般为D={(x1,y1),(x2,y2)…(xn,yn)}。

根据数据集可以画出很多线,线性回归的目的是寻到一个最优的直线,使代价函数误差最小。
代价函数:其中f(xi)=w*x^i+b;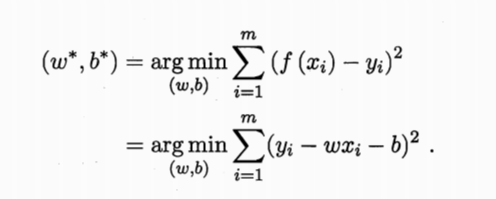
求解代价函数的解法:
1)利用迭代法,使用梯度下降算法找到最优解;
2)利用最小二乘法,直接求出参数w,b。
1.2 逻辑回归
上面介绍的线性回归是利用线性回归来拟合一条直线,根据这条直线,我们可以对输入的x进行预测f(x),即根据输入x,预测输出y。线性模型用于回归,也可以用于分类。逻辑回归就是分类,将数据集划分成几类。

逻辑回归的任务是在数据集D中,找到一条直线或曲线,把这两类分开。
通常采用sigmoid函数:
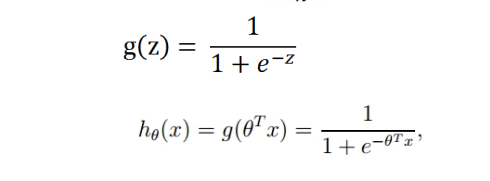
对应函数曲线如图所示:
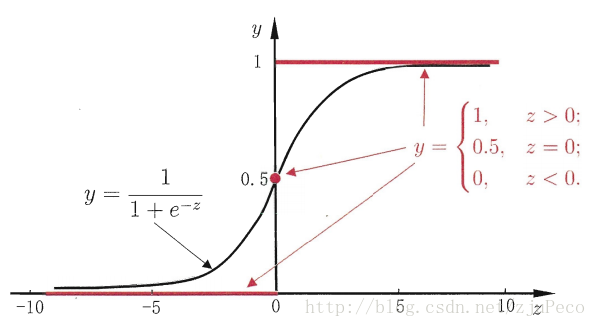
该函数将输出数据压缩在0-1的范围内,这也是概率的取值范围。对于二分类问题,我们就可以用预测y=1或0的概率表示为:
p(y=1|x;w,b,)=f(z),p(y=0|x;w,b,)=1-f(z)。
模型的函数表达式确定之后,如何去求模型中的参数。逻辑回归虽然也是线性模型,但是逻辑回归属于分类,不能使用上式中的代价函数。若使用上式的代价函数,因为L(w,b)为非凸函数,此时存在很多局部极值点,无法使用梯度迭代得到最终参数,因此分类问题采用对数最大似然代价函数:
L(w,b)=∑ log(p(yi|xi;w,b))
2.支持向量机SVM
SVM在处理线性数据集,非线性数据集都有较好的效果。用支持向量机进行分类,目的是为了得到一个分类器或者分类模型。不过它分类的是一个超平面(数据集是二维,超平面是一条直线,三维数据就是平面),这个超平面把样本分成两个部分,需要使正例和反例之间的间隔最大。间隔越大,泛化能力就越强。
2.1最优间隔分类器
如何获得最大化分类间隔?分类算法的优化目标通常是最小化分类误差,但对SVM而言,优化的目标时最大化分类间隔。所谓分类间隔是指两个分离的超平面的距离,其中最靠近超平面的训练样本称为支持向量机。


上图选自周志华老师的《机器学习》
以上为机器学习中线性模型的基础,从线性回归到逻辑回归。














 630
630











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









