







文章目录
总结(Federated Forest):
1. 每文三问
-
文章在解决什么问题?
大多数真实世界的数据分散在不同的公司或政府机构,无法轻松整合。这种 数据孤岛状况 和 数据隐私与安全 是人工智能应用 面临的两大挑战。
-
用了什么方法 (创新方法) ?
-
提出一个 可以提供隐私保护 的机器学习模型,联邦森林
-
提出一种 新的预测算法 ,极大地降低了通信开销,提高了预测效率。
-
-
效果如何?
实现与非隐私保护方法相同的准确性。在 UCI数据集 中验证了系统的有效性和鲁棒性。
2. Introduction
2.1 本文的贡献
- 保护隐私。通过 重新设计树构造算法 \color{RED}{重新设计 树构造算法} 重新设计树构造算法 ,应用加密方法和建立第三方可信服务器,充分保护数据隐私。信息交换的内容和数量被限制在最低限度,每个参与者都无法获取其他方的数据。
- 无损(精度)。我们的模型 基于 CART 和 bagging(装袋模型) 的方法,适用于纵向联邦学习。实验表明,我们的模型可以达到 与将数据集中到一个地方的非联邦方法 相同的精度。
- 效率。采用 MPI 方法 实现了一种高效的中间值共享通信机制 ( 文中没有提及 ) \color{RED}{实现了一种高效的中间值共享通信机制(文中没有提及)} 实现了一种高效的中间值共享通信机制(文中没有提及)。 设计了一种快速预测算法 \color{RED}{设计了一种快速预测算法} 设计了一种快速预测算法,该算法与参与者和树的数量、最大树深度和样本量弱相关(无标度)。
- 实用性和可伸缩性。我们的 模型支持分类和回归任务 ,并且对于现实应用具有很强的实用性、可扩展性、可伸缩性。
3. Problem Formulation
3.1 Data Distribution
各参与者数据的特点:
-
所有参与者有相同数量的样本空间且样本ID已跨域对齐
-
所有参与者有不同的特征空间且不同方的特征空间没有交集
系统组成:
- 1台参数服务器 m a s t e r {master} master(中心服务器)
- 多台客户端
3.2 Problem Statement
Given:数据拥有者 i {i} i 的数据集 D i {D_i} Di 、 每个客户端 i , 1 < = i < = M {i, 1<=i<=M} i,1<=i<=M 上的加密样本标签
Learn:联邦森林,对于森林中的每一棵树:
- 在 m a s t e r {master} master 上保存完整的树模型 T , T = T 1 ⋃ T 2 ⋃ . . . ⋃ T M {T, T=T_1 \bigcup T_2 \bigcup ... \bigcup T_M} T,T=T1⋃T2⋃...⋃TM
- 在 c l i e n t i {client_i} clienti 上 保存 partial 树模型 T i {T_i} Ti 。(解释 partial: T i {T_i} Ti 有与 T {T} T 相同的树结构,但 T i {T_i} Ti 的 node without full split info、split threshold)
Constraint:联邦森林的性能(准确度、f1-score … )与非联邦森林相当 auc
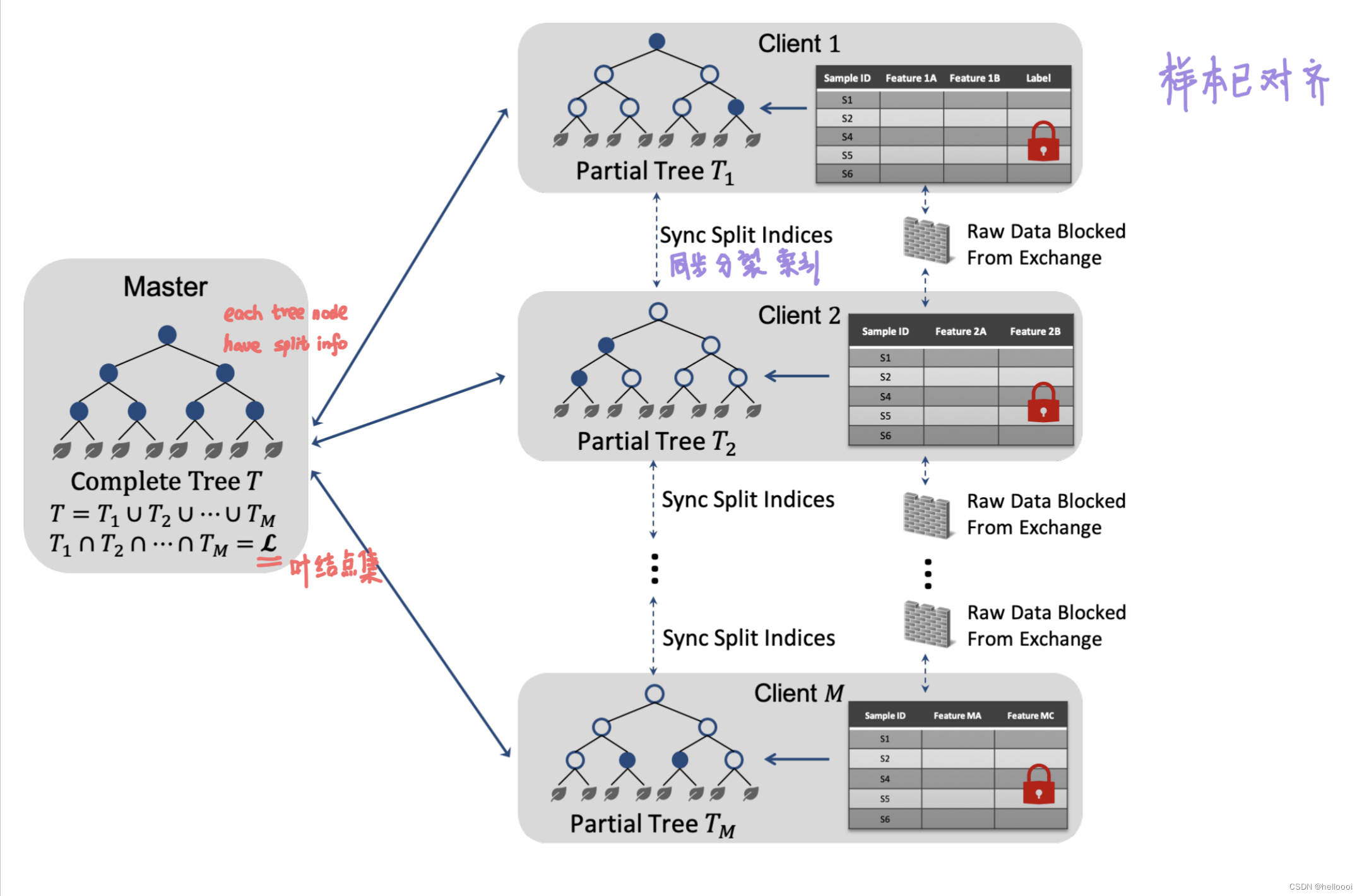
4. Methodology
4.1 Model Building
算法步骤:
1)master node 从整个数据中随机选择特征和样本的子集
2)master node 私下通知每个客户端所被选择的特征和样本IDs
3)client 在构建树过程中,需要频繁检查预剪枝条件(在训练开始前规定的条件,比如树达到某一深度就停止训练)。如果达到了预剪枝条件,将会把新创建的节点标记为叶节点。否则客户端进入分裂状态,通过比较 impurity improvements (基尼值) 来选择当前树节点的最佳分裂特征
3.1)首先,每个客户端 i {i} i 找到局部最优分割特征 f i ∗ {f_i^*} fi∗
3.2)然后,master 收集所有的局部最优特征和 impurity improvements,从而找到全局最优特征
3.3)master 通知客户端谁提供了全局最佳特征,相应的客户端将对样本进行分割,并将数据分区结果(left and right subtrees的sample IDs )发送给 master ;只有提供最佳分割特征的客户端才会保存本次的 split information ,其他客户端只保存 node structure。
3.4)最后,递归地创建子树并返回当前树节点。


4.2 Model Prediction
经典预测方法的问题:在纵向联邦中,经典的预测方法涉及主服务器和客户端之间的多轮通信,即使只有一个样本。当树数、最大树深度和样本量较大时,预测的通信需求将成为严重的负担。
新的预测方法:利用 distributed model storage strategy 的优势。只需要 对每棵树甚至整个森林进行一轮集体通信 。
c l i e n t {client} client 端预测算法步骤:
首先,每个客户端使用本地存储的模型来预测样本。对于 c l i e n t i {client_i} clienti 上的 T i {T_i} Ti ,每个样本从 root node 进入 T i {T_i} Ti ,最后落入一个或几个 leaf nodes。其中 当预测样本遍历每个节点时,
-
如果 split information 存储在该 node 上,则通过split threshold 确定该预测样本 enter the left or right subtree。
-
如果 split information 不存储在该 node 上,则该预测样本同时 enter both left and right subtree。
当这个过程结束时, c l i e n t i {client_i} clienti 中的每个叶节点将会 keep batch of samples,我们使用 S i l {S_i^l} Sil to 表示 the samples that fall into the leaf node l {l} l of the tree model T i {T_i} Ti 。

m a s t e r {master} master 端协调各个 c l i e n t {client} client 来实现最终的预测 算法步骤:
m a s t e r {master} master 取 S i l ∣ i = 1 M {S_i^l|}_{i=1}^M Sil∣i=1M 的交集,the result will be S l {S^l} Sl 。Then the sample sets S l {S^l} Sl 由 . S 1 、 S 2 . . . . 组成 {由. S^1 、S^2 ....组成} 由.S1、S2....组成 owned by each leaf node on complete tree T ,are already associated with final prediction。
也就是说 对 each example 在 all trees 上 obtain the label values 后,我们就可以很容易的实现最终的预测。

5. Experimental Studies
5.1 Experimental Setup
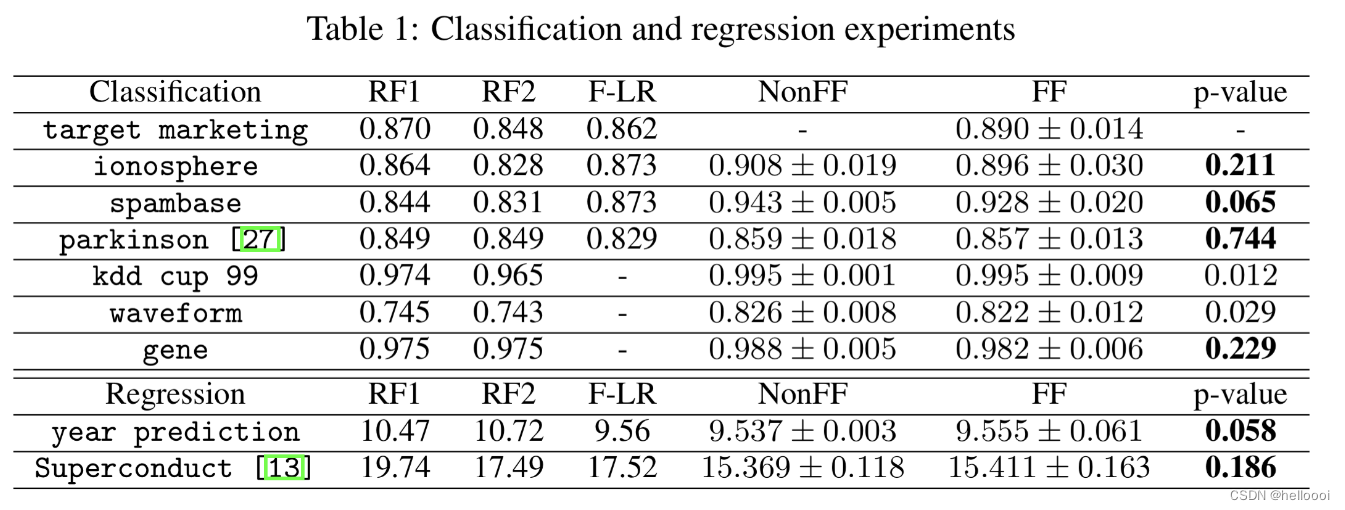
我们使用了9个基准数据集。如表所示,考虑了不同的样本量和特征空间,并对提出的框架进行了分类和回归问题的准确性、效率和健壮性的测试。
主要进行了三个系列的实验,包括 two data providers 的实验、multiple data providers 的实验、预测效率的分析。
5.2 Experimental with Two-Party Scenarios
在这一部分中,公开的 UCI 数据集按照特征维数 vertically and randomly separate,放置在两个不同的 client 上,每个 client 包含原始数据一半的特征空间。
本节的实验总结如下:
- Federated Logistic/Linear Regression (F-LR):我们联合训练 logistic / linear regression models,其中数据保存在本地,partial tree model 存储在 each client。
- Non-Federated Forest (NonFF):所有数据 集成在一起用于随机森林建模。
- Random Forest 1 (RF1):使用来自 1 s t {1^{st}} 1st client 的 partial data 来 build a random forest model。不使用 2 s t {2^{st}} 2st client 的 data 。
- Random Forest 2 (RF2):使用来自 2 s t {2^{st}} 2st client 的 partial data 来 build a random forest model。不使用 1 s t {1^{st}} 1st client 的 data 。
- Federated Forest (FF):这是我们提出的模型。双方共同学习一个 random forest model。数据保存在本地,partial tree model 存储在 each client。
发现:
-
RF1 和 RF2 的性能明显比 NonFF 和 FF 差。
原因:RF1 和 RF2 可以看作是仅用一个业务领域的数据建模,特征空间不足从而导致对 global knowledge 的学习不完善。
-
在大多数测试中,回归模型表现不是很好。FF 实现了更好的精度通过 building models on different domains。
-
对于大多数数据集,NonFF 和 FF 的表现优于其他方法。我们使用 Z-Test 来验证 NonFF 和 FF 的无损性。
- if p − v a l u e ≥ 0.05 {p-value \geq 0.05} p−value≥0.05 ,NonFF 和 FF 的输出无显著差异
- if 0.01 ≤ p − v a l u e < 0.05 {0.01 \leq p-value < 0.05 } 0.01≤p−value<0.05 ,在统计学上我们认为在该范围内存在一个轻微但可接受的差异
- if p − v a l u e < 0.01 { p-value < 0.01 } p−value<0.01 ,NonFF 和 FF 的输出显著差异
观察表中数据可以发现,其中有6个数据集被证明在 NonFF 和 FF 的结果之间没有显著差异,其余数据集的差异很小。
// TODO:学习 Z-Test
总的来说,我们有把握确认,联邦森林对于分类和回归问题都是无损的解决方案,它实现了与非联邦随机森林相同的性能。
5.3 Experimental with Multi-Party Scenarios
目的:验证联邦森林是否能够有效地连接两个以上的 domains;以及是否可以对精确度有所提升。
在实验时,我们每次向 federated model 中 add one domain。
如图所示,随着加入 federated model 的 domain 越来越多,
- Federated Forest 的 accuracy 不断提高;
- 训练执行时间与 domain 的数量成线性关系。
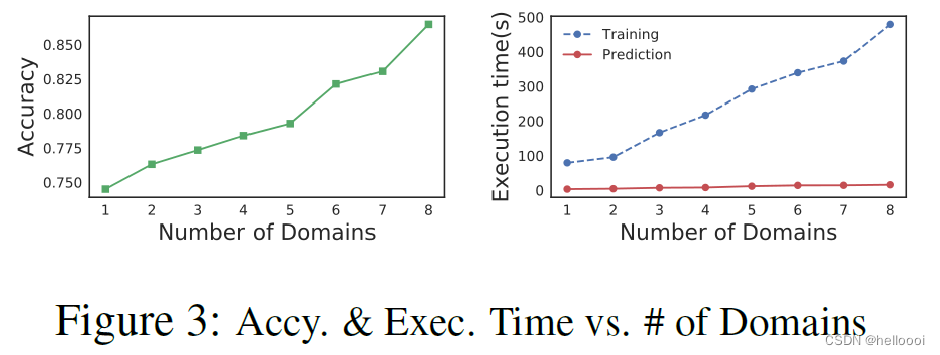
结果表明,我们的算法在处理多个 domain 时 very effective。
5.4 Prediction Efficiency
目的:比较 FF 与经典预测方法的 efficiency 。
5.4.1 Prediction Time vs. Number of Estimators
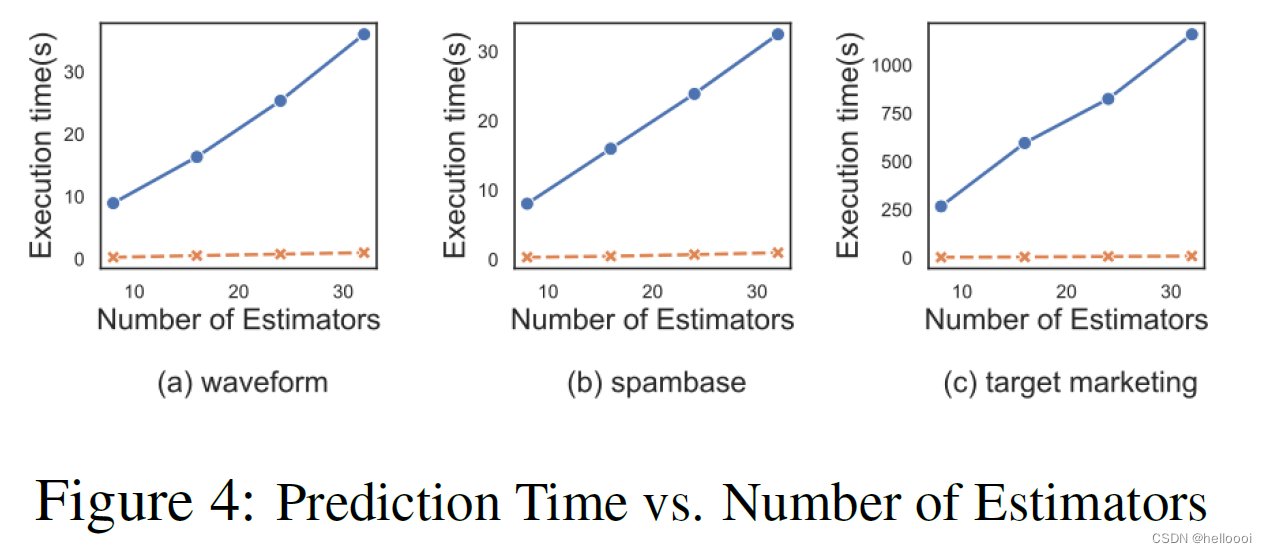
步骤:we set the maximum tree depth to 4 and changed the number of estimators from 8 to 32.
结论:
-
FF 与 classical method 的执行时间都随着 estimator 的数量线性增加,但 classical method 的斜率更大。
-
在预测过程中, classical method 每个节点都有多轮通信。FF 对于每个树只有一轮通信。
5.4.2 Prediction Time vs. Max Depth
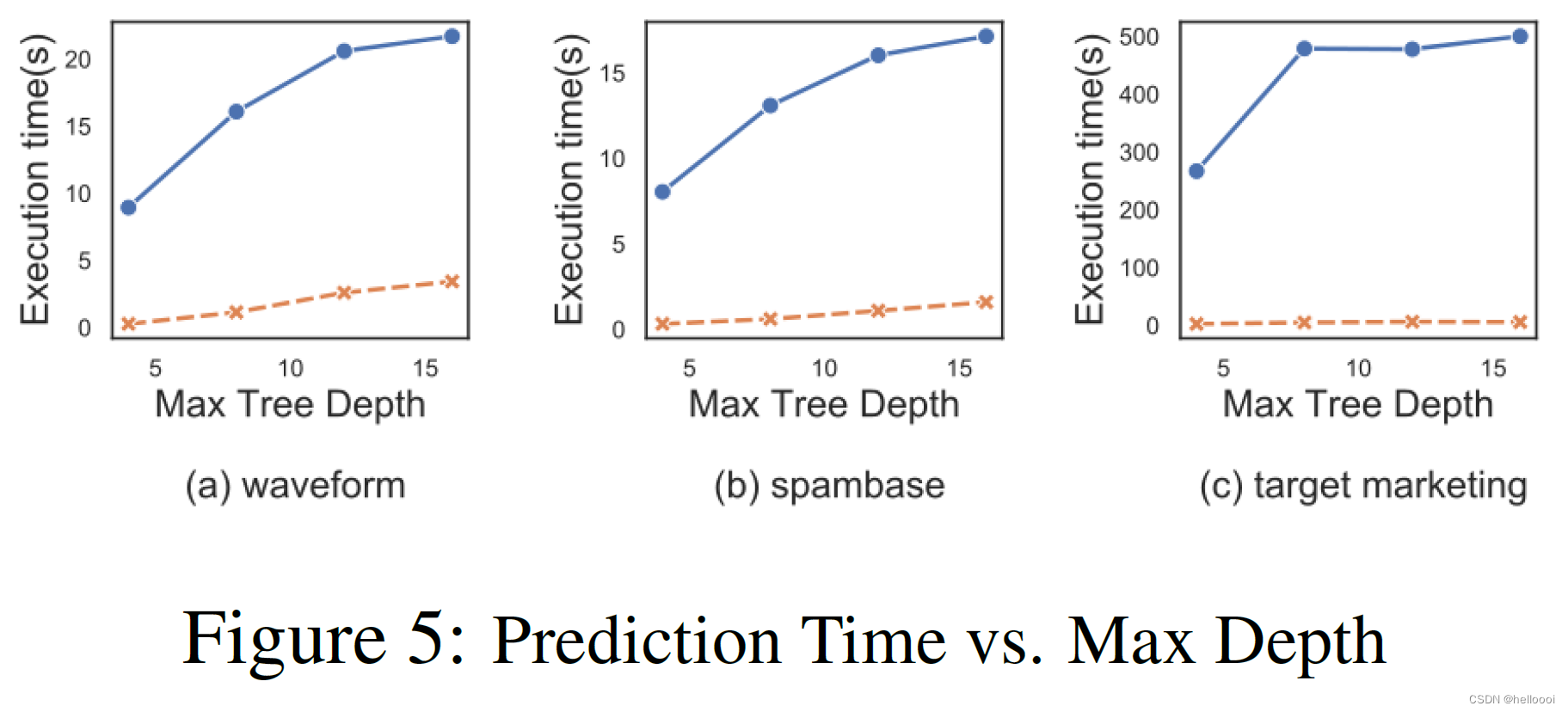
步骤:we set the number of estimators to 8, and adjusted the maximum tree depth from 4 to 16.
结论:随着最大树深度的增加,FF 和 classical mothod 预测时间的增长速度逐渐放缓并趋于稳定(原因:将最大树深度设置为较大的数字,树的构建可能会因为预剪枝条件而提前终止)。但是 FF 的预测时间远远低于 classical mothod。
并且在 FF 中,无论树有多深或创建了多少叶节点,对每棵树都只执行一次通信。
5.4.3 Prediction Time vs. Test Sample Size
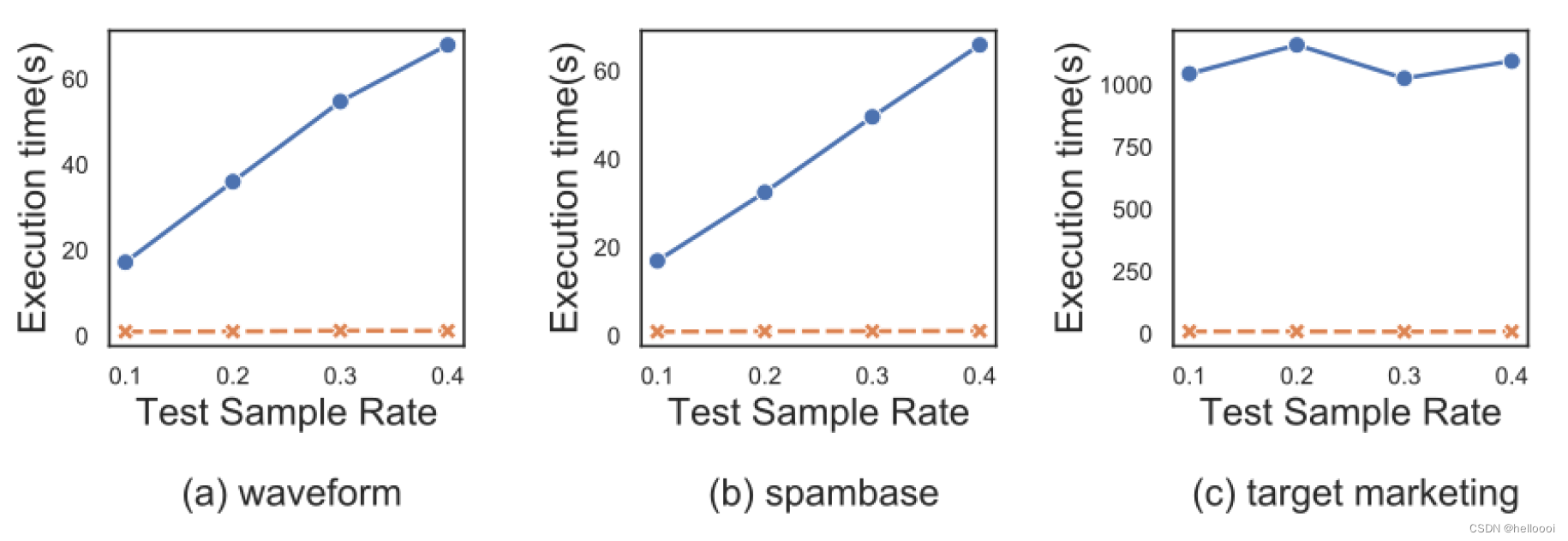
步骤:we fixed the number of estimators and maximum tree depth, and changed the test sample rate(样本率:决定 sample size) from 0.1 to 0.4.
结论:
- classical mothod 与 sample size 有很强的线性相关性,所有 classical method 呈现线性增长的趋势。
- FF 的执行时间变化非常缓慢,表明 FF 对预测 sample size 具有鲁棒性。
6. Conclusion
FF 允许在具有相同用户样本但属性集不同的 client 之间联合训练学习模型。(纵向联邦学习)
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











