







python安装seaborn
seaborn库是什么
import seaborn as sns
seaborn的常用别名为sns。
Seaborn是一个用Python制作统计图形的库。它建立在matplotlib之上,并与pandas数据结构紧密集成。
Seaborn可帮助探索和理解数据。它的绘图功能在包含整个数据集的数据框和数组上运行,并在内部执行必要的语义映射和统计汇总,以生成有用的图。
代码1:
import seaborn as sns
import matplotlib
#应用默认的主题,当然还有其他主题可以自由选择
sns.set_theme()
#载入一个范例数据集,这个数据库默认是没有的,需要自己github到下载
tips = sns.load_dataset("tips")
#创建数据可视化图片
sns.relplot(
data=tips,
x="total_bill", y="tip", col="time",
hue="smoker", style="smoker", size="size",
)
#如果在matplotlib模式下使用Jupyter / IPython接口展示那就不需要这一条
#其他情况都请加上这一句,要不然图片不会在窗口展示,后面会说到原理
matplotlib.pyplot.show()

安装seaborn
可以从PyPI安装seaborn的正式版本:
pip install seaborn
如果使用的是Anaconda,还可以用conda:
conda install seaborn
最后看到这样的图片就下载成功啦!

保险起见还是测试一下比较好。
#控制台测试.下载好了是应该没啥反应,没下载好会报错
>>>import seaborn as sns
代码2:
import seaborn as sns
import matplotlib.pyplot as plt
df = sns.load_dataset("penguins")
sns.pairplot(df, hue="species")
plt.show()

失败的原因以及解决方法
conda下起来比pip要稳定很多,但是我用的是pycharm,懒得下载conda。用pip下载果然失败了,垃圾pip,你还能下个啥!!!
下面列举了很多的原因,有的是一个原因,有的是多个叠加导致的。
网络原因
出现read timeout之类的,或者rerty之类的提示就是网络超时了。
有三个方法:
一、电脑网络信号不好,换个网络或者连热点试试吧。seaborn的官网下载路径在国外,对网络的质量要求很高。
二、科学上网。挂个梯子下载快且稳定。
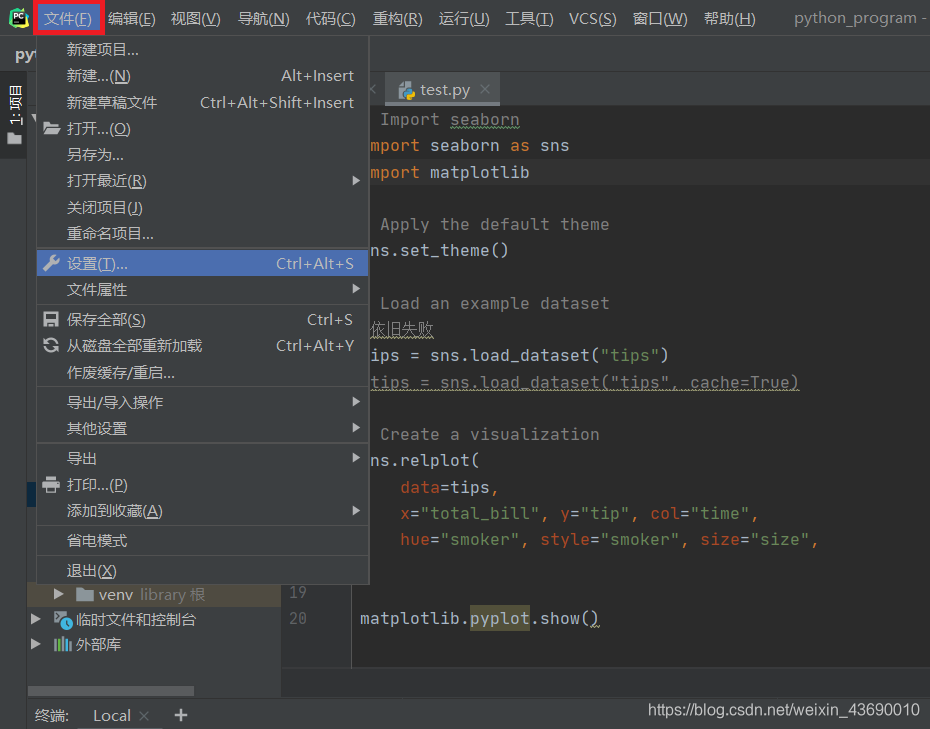
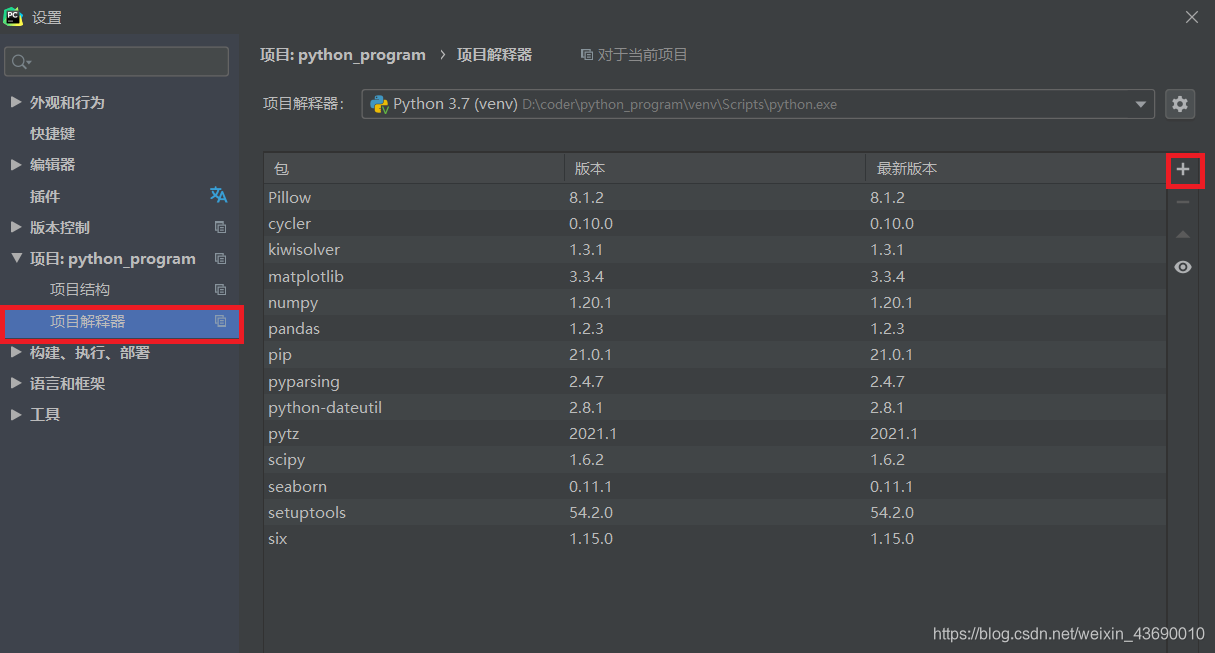
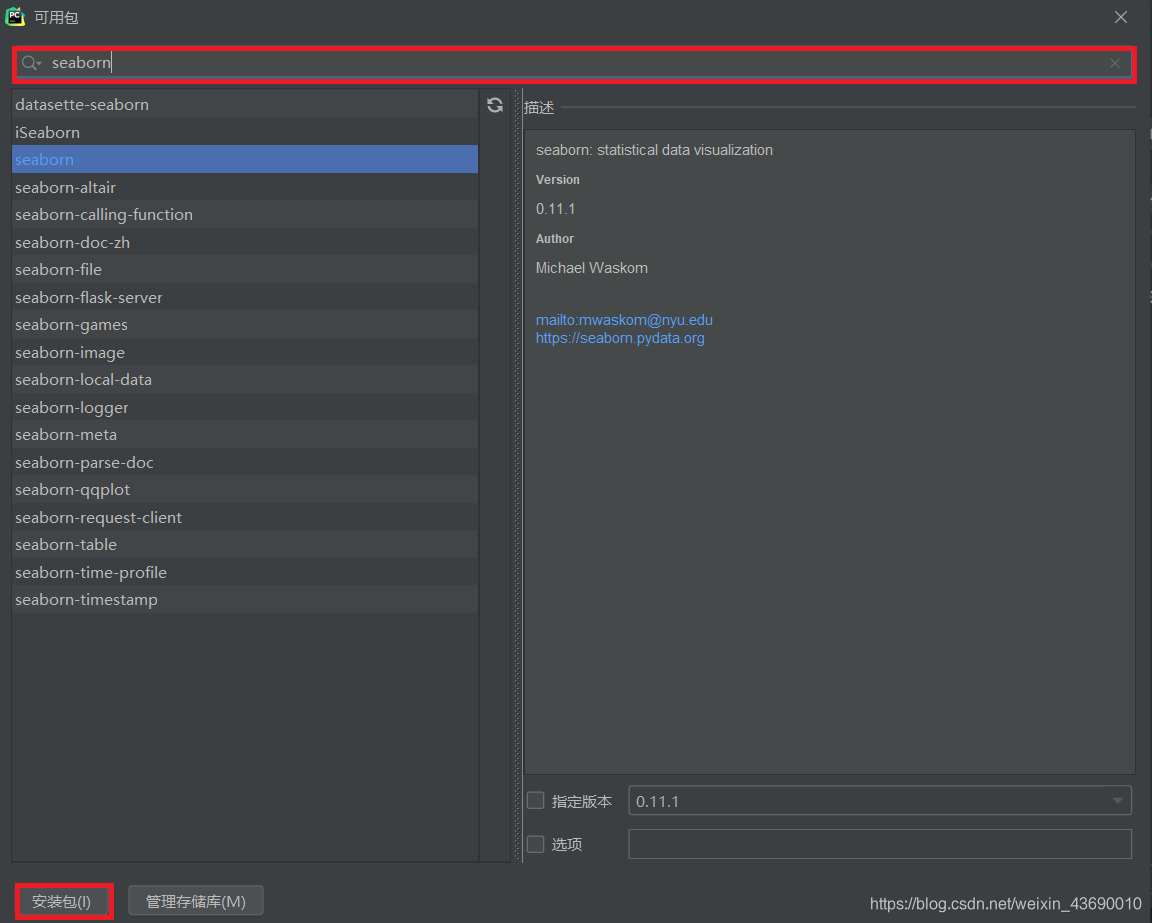
三、最靠谱的方法。pycharm上直接下载扩展包。点击文件->设置->项目解释器->右边那个加号->直接搜seaborn->安装包,等一会儿就可以了。Anaconda上也是同理。
python版本
官方最新的版本要求python3.6以上,查看一下python版本。
#终端输入
>>>python

依赖库不完整
这四个库缺一不可,检查一下自己是否有以下的库吧。
numpy
pandas
matlibplot
scipy
按道理讲pip下载seaborn的时候如果缺少这些库应该自动下载的,但是,pip没有道理。
举numpy为例子,其他三个类似:
#控制台
>>>import numpy
没有的话会报错,有的话就啥反应。报错了就用pip下载
#终端
>>>pip install numpy
数据包不完整
代码1和代码2中都有 sns.load_dataset() 函数。如果程序是从这里报错,并且提示 远程终端拒绝了您的访问 或者 url error 之类。
解决方法:
1、从github上下载这个文件,这是官方给的范例数据库:
https://github.com/mwaskom/seaborn-data/
2、找到load_dataset()在本地的数据库地址。get_data_home()函数的作用就是获取load_dataset() 的数据库地址。
#python控制台(交互行)
>>>sns.utils.get_data_home()
之后就会出现已下形式的地址
<你的驱动器>:\Users<你的用户名>\seaborn-data
例如:‘C:\Users\user1\seaborn-data’
3、将下载的文件夹解压,然后把里面的内容复制到数据库地址下。

原理:
load_dataset(“tips”)函数默认首先从本地库调取tips.csv文件,失败。因为tips.csv文件在seaborn-data库中,但是这个库并没有被默认安装。
然后函数远程调取tips.csv文件,调取路径如下所示:
path = (“https://raw.githubusercontent.com/mwaskom/seaborn-data/master/{}.csv”)
调取失败。不知道为啥失败,手动搜是可以访问的,我猜是github拒绝没有经过验证的机器访问。
所以只能手动从github上将这个库下载到本地,然后再访问。
sns.load_dataset(“tips”, cache=True)
当然也可以自己设定访问方式
seaborn.load_dataset(name,cache = True,data_home = None)
name:数据集的名称。
cache:如果为True,请尝试首先从本地缓存加载,如果需要下载,请保存到缓存。
data_home:缓存数据的目录;可通过get_data_home()获取。

















 1776
1776

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









