







DeepFuse: 一种深度无监督的方法,用于与极端曝光图像对进行曝光融合
DeepFuse: A Deep Unsupervised Approach for Exposure Fusion with Extreme Exposure Image Pairs
传统手工进行的MEF(多曝光融合),对输入条件变化大的鲁棒性不强(需要改变参数)----->可以利用深度表示----->深度学习用在MEF上的难点在于:缺乏足够的训练数据和事实依据----->采用的方法:1、收集大量多曝光图像;2、用无参考质量度量作为损失函数;同时为了防止伪影:从每个图像中提取一组常见的低级特征
introduce
高动态范围成像 (High Dynamic Range Imaging (HDRI)) 是一种摄影技术,有助于在困难的光照条件下捕获外观更好的照片。它有助于存储人眼可感知的所有范围的光 (或亮度),而不是使用相机实现的有限范围。由于此属性,场景中的所有对象在HDRI中看起来都更好,更清晰,而不会饱和 (太暗或太亮)。
HDR图像生成的流行方法称为多曝光融合 (MEF),其中,具有不同曝光的一组静态LDR图像 (进一步称为曝光堆栈) 被融合到单个HDR图像中。当曝光堆栈中每个LDR图像之间的曝光偏差差异最小时,大多数MEF算法效果更好1。因此,它们需要曝光堆栈中的更多LDR图像 (通常超过2张图像) 来捕获场景的整个动态范围。它导致更多的存储需求、处理时间和功率。原则上,长曝光图像 (高曝光时间拍摄的图像) 在暗区域具有更好的颜色和结构信息,而短曝光图像 (曝光时间更少的图像) **在亮区域具有更好的颜色和结构信息。**虽然长短曝光不同的图像有很多信息,但是在所及时,很难在两者之间找一个均衡的图像收集(在捕获时要考虑捕获时间、计算时间等)
所以建议使用带有曝光括号的图像对作为算法的输入。在实验中提出了一种数据驱动的学习方法,用于融合曝光方括号内的静态图像对。
初始层由一组滤波器组成,用于从每个输入图像对中提取常见的低级特征。这些输入图像对的低级特征被融合以重建最终结果。使用无参考图像质量损失函数对整个网络进行端到端训练。此外,我们的模型不需要针对变化的输入条件进行参数微调。
创新点
• A CNN based unsupervised image fusion algorithm
for fusing exposure stacked static image pairs.
• A new benchmark(基准、参照) dataset that can be used for comparing various MEF methods.
• An extensive experimental evaluation and comparison
study against 7 state-of-the-art algorithms for variety
of natural images.
Related Works
目前许多多曝光图像算法都是按局部或按像素计算每个图像的权重。然后,融合图像将是输入序列中图像的加权和。
极限学习机 (Extreme Learning Machine (ELM) ) 的回归方法,该方法将饱和度,曝光率和对比度馈送到回归器中,以估计每个像素的重要性。Instead of using hand crafted features, we use the data to learn a representation right from the raw pixels.
Proposed Method
我们提出使用CNNs 的图像融合框架。CNN通过优化损失函数来学习模型参数,以便预测结果与地面真相尽可能接近。例如,让我们假设输入x通过一些复杂的变换f映射到输出y。可以训练CNN来估计使期望输出y与获得的输出 “y” 之间的差最小化的函数f。使用损失函数 (例如均方误差函数) 计算y和 “y” 之间的距离。最小化此损失函数可更好地估计所需的映射函数。
让我们将输入曝光序列和融合算子表示为I和O(I)。假定输入图像使用现有的配准算法进行配准和对齐,从而避免了相机和物体的运动。我们用前馈过程FW(I) 建模O(I)。这里,F表示网络体系结构,w表示通过最小化损失函数学习的权重。由于MEF问题没有预期的输出O(I),因此无法使用平方误差损失或任何其他完全参考误差度量。所以我们使用无参考度量---->MEF-SSIM基于结构相似性指标 (SSIM) 框架 。它利用输入图像序列中各个像素周围的补丁的统计信息与结果进行比较。它测量结构完整性的损失以及在多个尺度上的亮度一致性;
将输入曝光堆栈转换为YCbCr彩色通道数据。CNN用于融合输入图像的亮度通道。这是由于以下事实: 图像结构细节存在于亮度通道中,并且亮度变化在亮度通道中比色度通道显着。所获得的亮度通道与使用色度 (Cb和Cr) 通道组合。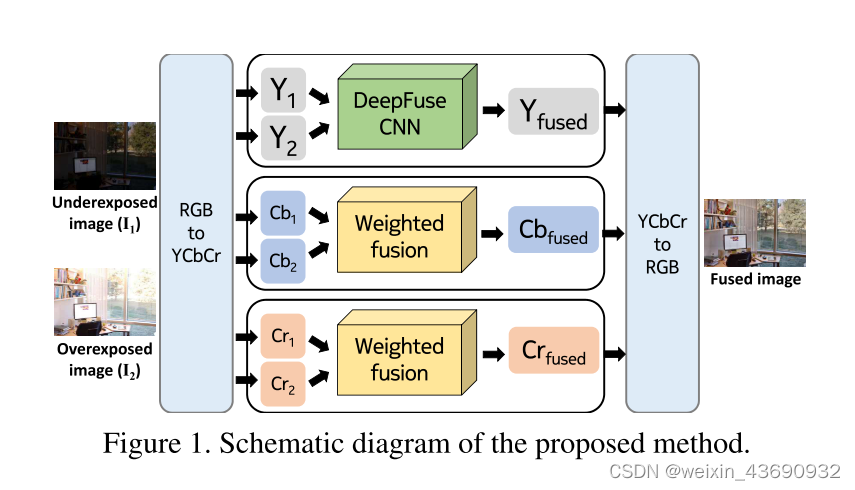
DeepFuse CNN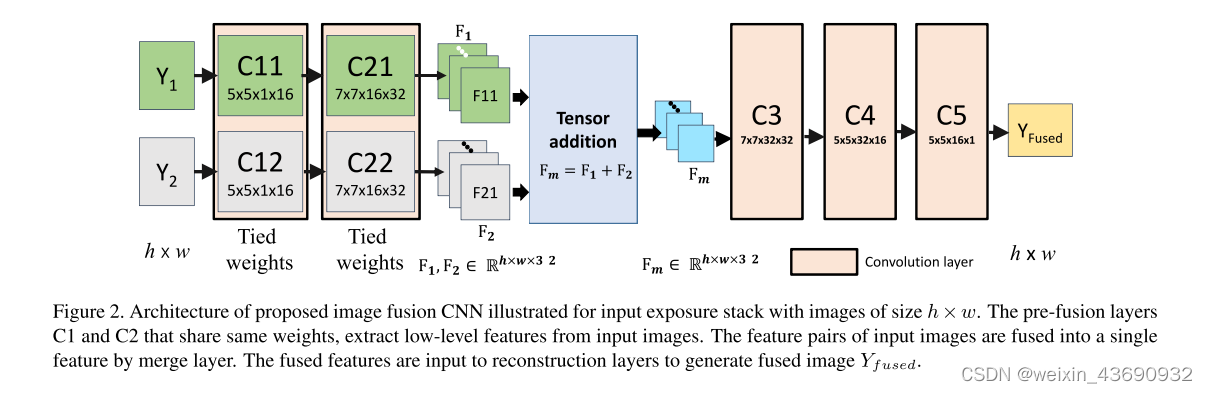
由三个组成部分: 特征提取层,融合层和重新构造层
具有大小为h × w的图像的输入曝光堆栈。
共享相同权重的预融合层C1和C2从输入图像中提取低级特征。
通过合并层将输入图像的特征对融合为单个特征。
将融合的特征输入到重建层以生成融合的图像。
如图所示,曝光不足和曝光过度的图像 (Y1和Y2) 被输入到单独的通道 (通道1由C11和C21组成,通道2由C12和C22组成)。第一层 (C11和C12) 包含5 × 5滤镜,以提取诸如边缘和角落之类的低级特征。融合前通道的权重是并列的,C11和C12 (C21和C22) 共享相同的权重。
这种架构的优势有三个方面: 首先,我们强制网络学习输入对的相同功能。也就是说,F11和F21是相同的特征类型。因此,我们可以通过融合层简单地组合各自的特征图。也就是说,添加图像1的第一特征图 (F11) 和图像2的第一特征图 (F21),并且该过程也应用于剩余的特征图。此外,两个图像中的相似特征类型被融合在一起。可以选择连接特征,通过这样做,网络必须计算出合并它们的权重。在我们的实验中,我们观察到特征串联也可以通过增加训练迭代次数,增加c3之后的过滤器和层数来获得类似的结果。这是可以理解的,因为网络需要更多的迭代次数来计算适当的融合权重。在此权重设置中,我们正在强制执行网络以学习对亮度变化不变的滤波器。这是通过可视化学习的过滤器观察到的 (参见图8)。在捆绑重量的情况下,很少有高激活过滤器具有中心周围的感受野 (通常在视网膜中观察到)。这些滤波器已经学会了从邻域中去除均值,从而有效地使特征亮度不变。其次,可学习过滤器的数量减少了一半。最后,由于网络的参数数量少,因此收敛速度快。
从C21和C22获得的特征通过合并层融合。然后将熔丝层的结果通过另一组卷积层 (C3,C4和C5),以从融合特征重建最终结果 (Yfused)。
依旧是在YCbCr通道,图像的关键结构细节往往主要存在于Y通道中,所以对颜色程度不太关注。















 6584
6584











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









