







Classification Saliency-Based Rule for Visible and Infrared Image Fusion
(基于分类显著性的可见光和红外图像融合规则)
我们提出了一种基于像素的分类显着性融合规则。
首先,我们使用分类器对两种类型的源图像进行分类,以捕获两个类之间的差异和唯一性。
然后,将每个像素的重要性量化为其对分类结果的贡献,重要性以分类显着性图的形式显示。
最后,根据显著性图对特征图进行融合,生成融合结果。而且,由于不需要手动决定要保留的特征,因此它是一种无人监督的方法,人工参与较少。
介绍
在过去的几十年中,已经提出了许多方法来解决可见光和红外图像融合 (VIF) 问题。它们包括一些传统方法,例如基于多尺度变换的方法 ,稀疏表示,子空间,混合方法和其他融合方法 。此外,由于深度学习受到了广泛关注,因此在过去几年中,许多方法将深度学习应用于VIF。他们使用深度网络提取特征或重建融合图像,这打破了传统特征提取方式的局限性。在此基础上,为了在更大程度上保留源图像中的信息,一些方法应用了生成对抗网络 (GANs)。但是,它们依赖于手动设计的融合规则来生成融合结果。即使某些模型是端到端的,它们仍然手动设置要保留的特征,并依靠这些特征来训练模型。这些情况是由于VIF中缺乏基本真相以及卷积神经网络 (CNNs) 的不可解释性引起的。如前所分析,有限融合规则仍然限制了深度学习在VIF中的应用。为了突破融合规则在深度学习应用中的局限性,我们提出了一种新的基于深度学习的高可解释性融合规则。
贡献
1)我们设计了一种新颖的基于深度学习的融合规则,为深度学习在VIF中的应用带来了新的可能性。通常,我们使用分类器对可见光和红外特征图进行分类。然后,我们依靠特征图中每个像素对分类结果的贡献/显着性来评估其重要性/唯一性。因此,它突破了将深度学习应用于融合规则的瓶颈。
2)现有的基于深度学习的方法需要手动定义要保留的特征。否则,它们执行简单的融合规则,而不考虑特征的重要性或重要性。相比之下,我们的方法依赖于预先训练的分类器来自动保留重要/独特的功能。因此,所提出的方法是一种无监督的模型,人工参与较少。
3)此外,与现有的融合规则相比,所提出的基于分类显着性的融合规则具有更高的可解释性,尤其是在CNN提取的特征图不可解释性的情况下。
相关工作
Existing Infrared and Visible Image Fusion Methods
在一些基于深度学习的方法中,特征提取是通过CNNs实现的。然后,通过一些手动设计的融合规则来融合功能。最后,作为特征提取的逆过程,使用特征重建来生成融合结果。例如,在IFCNN中,共享相同权重的两个卷积层用于从源图像中提取特征。然后,它们通过一些人工选择的融合规则 (包括max,min和mean) 进行融合,并馈入后续的卷积层以重建融合结果。因此,可以得出结论,融合的关键在于两个因素: 特征提取和融合规则。
此外,还提出了一些端到端方法,这些方法在不设计融合规则的情况下打破了这一传统框架,包括基于GAN的方法。融合过程不是设计融合规则,而是在整个过程中端到端实现.但是,他们手动设置要保留的特征 (源图像中的部分信息),并依靠这些特征来训练网络。例如,一些方法试图保留可见图像中红外图像和梯度的强度分布。一些方法旨在保留两幅源图像中的光线、对比度和结构信息。例如,VIF-Net 采用修正的结构相似性 (M-SSIM) 和总变化 (total variation (TV)) 的组合作为无监督损失函数。 M-SSIM测量融合图像和源图像之间的相似性,TV 损耗实现梯度变换并消除一些噪声。因此,尽管不需要手动设计融合规则,但在设计整体约束时仍然存在很强的主观性。也就是说,整体的制约因素仍然依赖于人类视觉感知的主观判断。
Existing Infrared and Visible Image Fusion Rules
对于特征提取和融合规则这两个因素,研究人员非常重视设计适当的特征提取方法来从源图像中提取代表性信息。然而,很少有类型的研究专注于设计融合规则,而它确实发挥了关键作用。直到今天,融合规则的选择仍然是限制和手动设计的,包括choose-max 、addition 、average 、Max-l1和l1-Norm规则。其中,**Max-l1规则用于融合源图像的稀疏编码系数。**它比较两个稀疏码的l1-Norm,并依赖于比较结果生成二进制掩码来融合相应的图像补丁。特征图的l1-Norm被用作活动水平度量。在此基础上,利用基于块的平均运算符来计算最终的活动水平图。作为一个整体,它们依靠值本身来确定融合规则,而不考虑对后续任务或重要性的影响。因此,在这些融合规则中,主观确定了活动水平度量的方式,并且这些融合规则缺乏明确的物理含义。
即使融合方法的总体框架相同,不同的融合规则也会对融合性能产生决定性的影响。但是,当两种类型的特征相反时,融合结果中会丢失一些信息。然而,一些信息由于不可更改而被截断。相比之下,我们的融合规则可以保留更多独特的信息并提高融合结果的质量。
现有的融合规则对于融合特征是粗糙的原因如下。由于CNN的不可解释性和不可理解性,特征图中表示的特定特征是不可知的。例如,一些卷积核提取明亮的区域,一些提取黑暗的区域,而一些可能提取线。如果是这种情况,则max规则可以很好地保留明亮的区域,而亮度低的信息将遭受失真。由于未知和可变性,很难衡量特征图不同区域的重要性。因此,通过分配像素权重图来设计融合规则是没有根据的,该权重图考虑了特征图的像素重要性。在这种情况下,融合规则的有限选择及其粗糙度限制了融合结果的改进。由于融合规则的限制,即使是设计良好的特征提取方法也可能无法达到其最佳性能。
为了解决这个问题,我们提出了一种新颖的基于分类显着性的融合规则。考虑到可解释神经网络的可行性,我们依靠二进制分类器来评估特征图中每个像素的贡献/显着性,指示是否需要将该像素融合到结果中。然后,生成分类显着性图以融合两种类型的特征图。此方法称为基于分类显着性的融合方法 (CSF)。
方法
Problem Formulation
给定一对对齐的可见图像V和红外图像I,目标是合成融合图像F。在F中,可以整合并显示互补或重要信息。因此,我们的目标是学习一个函数,该函数学习 {V,I} 和F之间的映射。
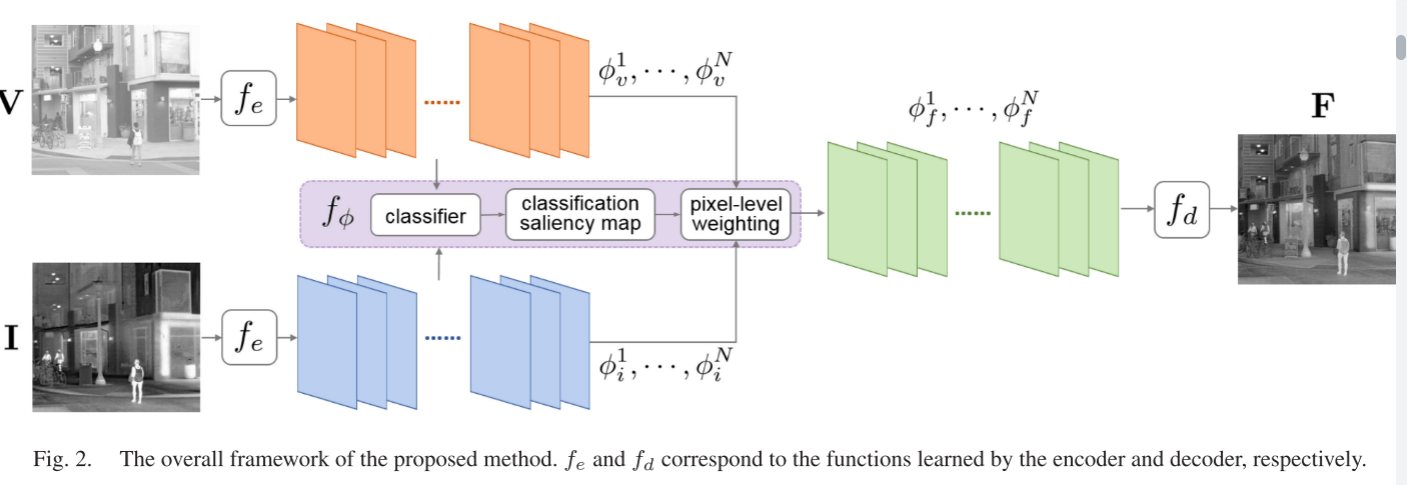
基于上述融合框架,我们首先使用编码器提取特征图作为源图像的综合描述。它是图2所示的整体框架的第一步:

然后,我们设计一个融合规则,这是这项工作的主要贡献。在这里,我们暂时将这一步定义为:

Feature Extraction and Reconstruction
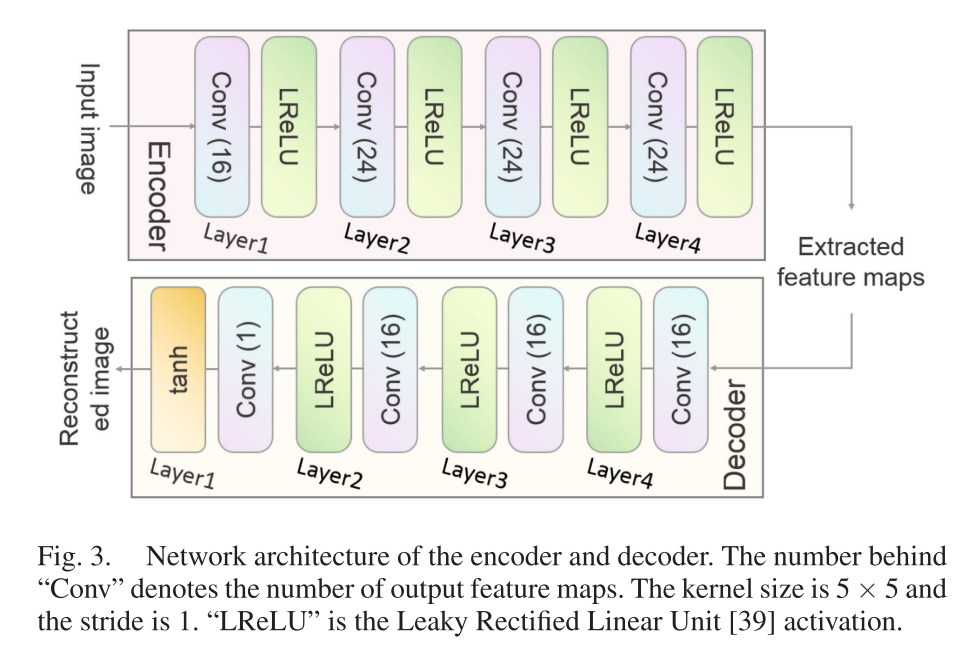
为了学习fe和fd,我们使用标准的编码器-解码器来实现它们。网络架构如图3所示。可见光和红外图像依次用作原始输入。从每个输入中提取N个特征图。由于fd是fe的逆变换,因此解码器有望重建原始输入。因此,通过最小化输入和输出之间的相似性损失来优化编码器-解码器中的参数,其定义为:

Classification Saliency Evaluation
在本节中,我们讨论f φ 的解。VIF的目标是保留重要和互补的信息,因此融合特征图的关键是评估其重要性。重要部分应保留,冗余部分应压缩。一种直观的评估方法是将可见特征图的一部分替换为红外特征图 (反之亦然),然后观察替换后结果的变化。如果这部分是多余的,替换后,重建的图像看起来仍然像原来的可见图像。否则,当该部分包含红外图像中的唯一信息时,替换后,重建的图像将类似于红外图像。
为了量化图像样式,我们使用二进制分类器来测量图像属于特定样式的概率。此外,分类器通常侧重于根据输入的整个区域捕获每个类的最显着特征以及不同类之间最明显的差异。由于它可以比较不同类型的信息并帮助识别重要且值得保留的信息,因此其功能类似于融合的目标。因此,我们使用分类器来帮助定量设计融合规则。由于解码器是固定的,因此重建的图像直接由特征图确定。此外,fφ 执行特征级融合,这是特征图的重要性,而不是需要测量的图像。因此,分类器的输入是由预先训练的编码器提取的特征图,而不是原始源图像。
分类器的特点:
一方面,分类器可以量化输入是红外特征图还是可见特征图的可能性。另一方面,特征图某些部分的变化会对分类结果产生影响。根据它,重要性/唯一性可以被定量评估。
1) 按通道替换以进行直观验证: 为了进行直观验证,我们以图像对为例,首先执行按通道替换。输入红外特征图时,红外概率 (属于红外类的输入) 接近1。然后,我们用按通道顺序排列的相应可见特征图替换二十四个红外特征图之一。替换策略如图4所示,在不同通道中替换特征图时红外概率的变化也如图4所示。
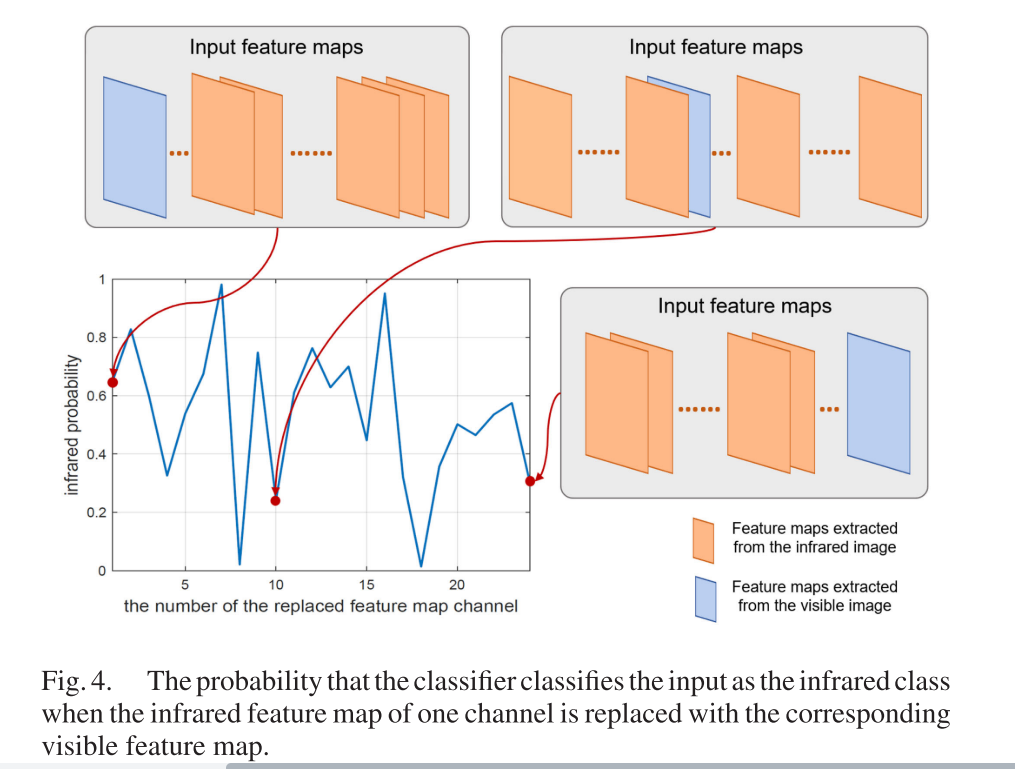
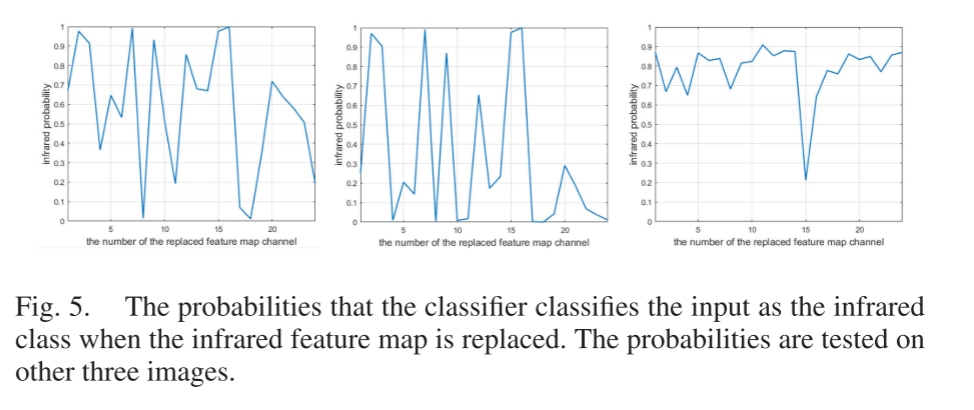
如图4所示,高概率表明这些通道中的特征图对分类结果无关紧要。换句话说,这些通道中的可见光和红外特征图包含类似的信息。相反,当某些红外特征图被替换时,红外概率小于0.5。它表明这些渠道携带重要/独特的信息。在其他图像中也存在相同的现象,如图5所示,基于对分类结果的影响,可以评估重要性以反映这些特征图是否包含生命信息。我们将其称为分类显着性。
2) 按通道和按像素的重要性评估: 按通道替换策略本质上是一种改变原始值的方法。在数学上,我们将二进制分类器的输出表示为y = {y1,y2}。y1表示可见类的概率,y2是红外类的概率。yk = max(y1,y2) 表示预测类的概率。我们将 φ i中的每个特征图与 φ v中的特征图顺序更改,并观察yk的变化,即△yk。
更准确地说,不仅不同的通道,而且同一通道中的不同像素对分类结果的影响不均匀。这里我们以红外特征图 φ i为例,以可见的为例。为了评估像素的重要性,
3) 重要性评估的积分梯度: 在此基础上,我们提出了一种基于梯度的评估方法,并进行了进一步的改进,以突破梯度方法的局限性。改进的评估方法用于生成最终分类显着性图。限制和改进的细节如下所示。
以前,我们假设公式(5) 中的梯度。可以直接用于量化分类重要性,尽管如此,当像素或特征图增强到一定程度时,其对分类决策的贡献可能达到饱和,称为梯度饱和。
为了说明这种现象,我们将输入特征图从 φ i逐渐更改为 φ v。输出可见概率的变化如图6所示,如图所示,当我们从 φ i开始逐渐改变输入时,可见概率迅速增加。但是,当输入超过中间值,即 (φ i φ v)/2时,可见概率的增长率变慢甚至不再增加。换句话说,输入对yk的影响达到饱和。因此,在图6的右半部分中,饱和区域中的梯度将对分类显著性评估做出误判。
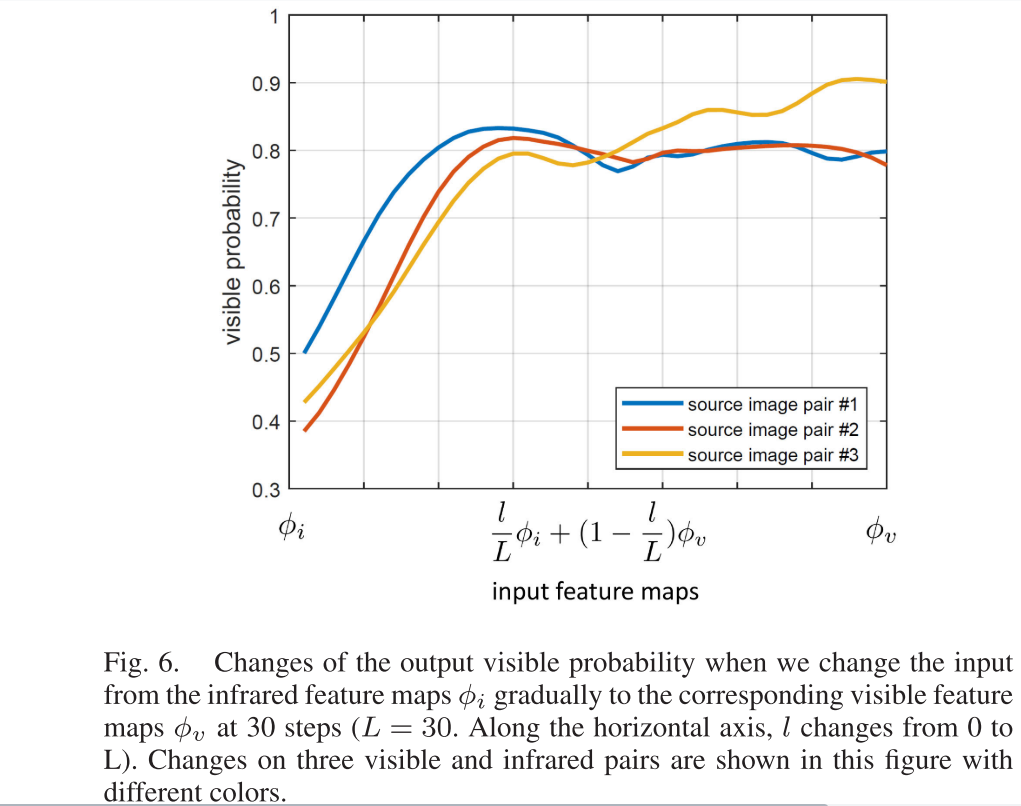
为了解决这个问题,我们更加关注不饱和区域中的非零梯度。为此,我们使用积分梯度,其优越性已在中得到验证。积分梯度的计算取决于两个因素: 积分路径和积分步骤。
对于积分路径,将起点设置为基线红外特征图 ψ i (要分配)。端点设置为 φ i。为了直观的解释,图6的水平轴可以看作是集成路径的示例。在积分步骤定义为L的情况下,积分路径中的特征图可以定义为:
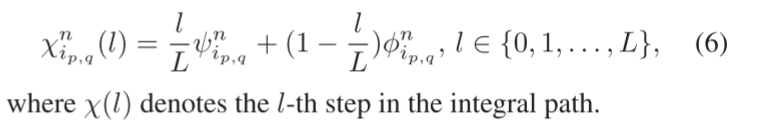
至于 ψ i的特定设置,我们期望沿着积分路径,yk具有最大变化范围。因为端点是固定的,所以起点 ψ i应该对应于最低的yk。由于 ∅v属于相反的类别,因此∅v对应于最低的红外概率。因此,我们设置 ψ i = ∅ v。然后,我们在积分路径中执行线性插值以近似积分过程。
根据积分梯度,我们使用yk对积分路径中所有步骤的梯度之和来表示相应的分类显着性:
其中 α ∈ [0,1] 是衰减系数。由于非饱和区域中的梯度比饱和区域中的梯度更准确地反映了重要性,因此我们使用 α 来分配不同的权重。可以看出,等式(5) 是L = 1而不衰减 (α = 1) 的特殊情况。最终的红外显着性图Ci可以通过Eq(7)获得。可以通过替换 χ i以相同的方式获得可见的显着性图Cv。
Pixel-Level Weighting
由于分类显着性图是通过梯度获得的,因此由于存在偏差,因此无法直接将它们用作权重图。为此,执行后续处理以消除偏差:
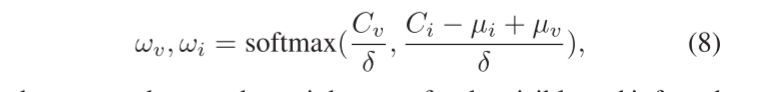
其中 ωv和 ωi分别是可见光和红外特征图的权重图。μ v和 μ i是Cv和Ci的平均值。它们用于减轻偏差对softmax结果的影响。δ 是一个温度参数。它控制着重量的间隙。当 δ 较小时,权重将分别接近0和1。相反,当 δ 较大时,两个权重都将在0.5左右。在这种情况下,权重图将失去其功能。采用softmax函数将 ω v和 ω i中的每个元素映射到0和1之间的实数,并保证相应位置的元素之和为1,即:















 3909
3909











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









