







 本文详细介绍了如何在YOLOv5/v7中添加多种注意力机制,包括SE、CBAM、ECA、CA等,并提供了相关原理和代码实现。通过添加注意力机制,可以提升模型的性能,同时文章还提供了详细的修改配置文件的步骤。此外,还更新了最新的注意力模块源码,适用于目标检测领域的研究和实践。
本文详细介绍了如何在YOLOv5/v7中添加多种注意力机制,包括SE、CBAM、ECA、CA等,并提供了相关原理和代码实现。通过添加注意力机制,可以提升模型的性能,同时文章还提供了详细的修改配置文件的步骤。此外,还更新了最新的注意力模块源码,适用于目标检测领域的研究和实践。
手把手带你 YOLOv5/v7 添加注意力机制
番外篇 | 20+ 种注意力机制及代码 适用于YOLOv5/v7/v8
感谢大家一路以来的支持和陪伴!为了回馈大家对我们的关注和信任,我特别赠送 50 算力券,您可以免费体验 4090 显卡 24 小时的强劲性能:点击领取。希望在您的项目或学习中助您一臂之力!
文章目录
- 手把手带你 YOLOv5/v7 添加注意力机制
- 注意力机制介绍
- 注意力机制的分类
- 1. SE 注意力模块🌟
- 2. CBAM 注意力模块🌟
- 3. ECA 注意力模块🌟
- 4. CA 注意力模块🌟
- 5. 添加方式💡
- 6. 添加方式的补充说明💡
- 7. SimAM 注意力模块 🍀
- 8. S2-MLPv2 注意力模块🍀
- 9. NAMAttention 注意力模块🍀
- 10. Criss-CrossAttention 注意力模块🍀
- 11. GAMAttention 注意力模块🍀
- 12. Selective Kernel Attention 注意力模块🍀
- 14. A2-Net 注意力模块🍀
- 15. DANPositional 注意力模块
- 16. DANChannel 注意力模块
- 17. RESNest 注意力模块
- 18. Harmonious 注意力模块
- 19. SpatialAttention 注意力模块
- 19. RANet 注意力模块
- 20. Co-excite 注意力模块
- 21. EfficientAttention 注意力模块
- 22. X-Linear 注意力模块
- 23. SlotAttention 注意力模块
- 24. Axial 注意力模块
- 25. RFA 注意力模块
- 26. Attention-BasedDropout 注意力模块
- 27. ReverseAttention 注意力模块
- 28. CrossAttention 注意力模块
- 29. Perceiver 注意力模块
- 30. Criss-CrossAttention 注意力模块
- 31. BoostedAttention 注意力模块
- 32. Prophet 注意力模块
- 33. S3TA 注意力模块
- 34. Self-CriticAttention 注意力模块
- 35. BayesianAttentionBeliefNetworks 注意力模块
- 36. Expectation-MaximizationAttention 注意力模块
- 37. GaussianAttention 注意力模块
- 本人更多 YOLOv5/v7 实战内容导航🍀🌟🚀
注意力机制介绍
注意力机制(Attention Mechanism)源于对人类视觉的研究。在认知科学中,由于信息处理的瓶颈,人类会选择性地关注所有信息的一部分,同时忽略其他可见的信息。为了合理利用有限的视觉信息处理资源,人类需要选择视觉区域中的特定部分,然后集中关注它。例如,人们在阅读时,通常只有少量要被读取的词会被关注和处理。综上,注意力机制主要有两个方面:决定需要关注输入的哪部分;分配有限的信息处理资源给重要的部分。这几年有关attention的论文与日俱增,下图就显示了在包括CVPR、ICCV、ECCV、NeurIPS、ICML和ICLR在内的顶级会议中,与attention相关的论文数量的增加量。下面我将会分享Yolov5 v6.1如何添加注意力机制;并分享到2022年4月为止,30个顶会上提出的优秀的attention.

注意力机制的分类

1. SE 注意力模块🌟
论文名称:《Squeeze-and-Excitation Networks》
论文地址:https://arxiv.org/pdf/1709.01507.pdf
代码地址: https://github.com/hujie-frank/SENet
1.1 原理
SEnet (Squeeze-and-Excitation Network)考虑了特征通道之间的关系,在特征通道上加入了注意力机制。
SEnet通过学习的方式自动获取每个特征通道的重要程度,并且利用得到的重要程度来提升特征并抑制对当前任务不重要的特征。SEnet 通过Squeeze模块和Exciation模块实现所述功能。

如图所示,首先作者通过squeeze操作,对空间维度进行压缩,直白的说就是对每个特征图做全局池化,平均成一个实数值。该实数从某种程度上来说具有全局感受野。作者提到该操作能够使得靠近数据输入的特征也可以具有全局感受野,这一点在很多的任务中是非常有用的。紧接着就是excitaton操作,由于经过squeeze操作后,网络输出了
1
∗
1
∗
C
1*1*C
1∗1∗C 大小的特征图,作者利用权重
w
w
w 来学习
C
C
C 个通道直接的相关性。在实际应用时有的框架使用全连接,有的框架使用
1
∗
1
1*1
1∗1 的卷积实现。该过程中作者先对
C
C
C 个通道降维再扩展回
C
C
C 通道。好处就是一方面降低了网络计算量,一方面增加了网络的非线性能力。最后一个操作时将exciation的输出看作是经过特征选择后的每个通道的重要性,通过乘法加权的方式乘到先前的特征上,从事实现提升重要特征,抑制不重要特征这个功能。
1.2 代码
import torch
import torch.nn as nn
class SE(nn.Module):
def __init__(self, c1, c2, ratio=16):
super(SE, self).__init__()
self.avgpool = nn.AdaptiveAvgPool2d(1)
self.l1 = nn.Linear(c1, c1 // ratio, bias=False)
self.relu = nn.ReLU(inplace=True)
self.l2 = nn.Linear(c1 // ratio, c1, bias=False)
self.sig = nn.Sigmoid()
def forward(self, x):
b, c, _, _ = x.size()
y = self.avgpool(x).view(b, c)
y = self.l1(y)
y = self.relu(y)
y = self.l2(y)
y = self.sig(y)
y = y.view(b, c, 1, 1)
return x * y.expand_as(x)
这里放上我自己做实验的截图,我就是把SE层加到了第
9
9
9 层的位置;粉红色线条代表添加了SE注意力机制。

2. CBAM 注意力模块🌟
论文题目:《CBAM: Convolutional Block Attention Module》
论文地址:https://arxiv.org/pdf/1807.06521.pdf
2.1 原理
CBAM (Convolutional Block Attention Module)结合了特征通道和特征空间两个维度的注意力机制。

CBAM通过学习的方式自动获取每个特征通道的重要程度,和SEnet类似。此外还通过类似的学习方式自动获取每个特征空间的重要程度。并且利用得到的重要程度来提升特征并抑制对当前任务不重要的特征。

CBAM提取特征通道注意力的方式基本和SEnet类似,如下Channel Attention中的代码所示,其在SEnet的基础上增加了max_pool的特征提取方式,其余步骤是一样的。将通道注意力提取厚的特征作为空间注意力模块的输入。

CBAM提取特征空间注意力的方式:经过ChannelAttention后,最终将经过通道重要性选择后的特征图送入特征空间注意力模块,和通道注意力模块类似,空间注意力是以通道为单位进行最大池化和平均池化,并将两者的结果进行concat,之后再一个卷积降成
1
∗
w
∗
h
1*w*h
1∗w∗h 的特征图空间权重,再将该权重和输入特征进行点积,从而实现空间注意力机制。
2.2 代码
import torch
import torch.nn as nn
class ChannelAttention(nn.Module):
def __init__(self, in_planes, ratio=16):
super(ChannelAttention, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.max_pool = nn.AdaptiveMaxPool2d(1)
self.f1 = nn.Conv2d(in_planes, in_planes // ratio, 1, bias=False)
self.relu = nn.ReLU()
self.f2 = nn.Conv2d(in_planes // ratio, in_planes, 1, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = self.f2(self.relu(self.f1(self.avg_pool(x))))
max_out = self.f2(self.relu(self.f1(self.max_pool(x))))
out = self.sigmoid(avg_out + max_out)
return out
class SpatialAttention(nn.Module):
def __init__(self, kernel_size=7):
super(SpatialAttention, self).__init__()
assert kernel_size in (3, 7), "kernel size must be 3 or 7"
padding = 3 if kernel_size == 7 else 1
self.conv = nn.Conv2d(2, 1, kernel_size, padding=padding, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
# 1*h*w
avg_out = torch.mean(x, dim=1, keepdim=True)
max_out, _ = torch.max(x, dim=1, keepdim=True)
x = torch.cat([avg_out, max_out], dim=1)
# 2*h*w
x = self.conv(x)
# 1*h*w
return self.sigmoid(x)
class CBAM(nn.Module):
def __init__(self, c1, c2, ratio=16, kernel_size=7):
super(CBAM, self).__init__()
self.channel_attention = ChannelAttention(c1, ratio)
self.spatial_attention = SpatialAttention(kernel_size)
def forward(self, x):
out = self.channel_attention(x) * x
# c*h*w
# c*h*w * 1*h*w
out = self.spatial_attention(out) * out
return out
3. ECA 注意力模块🌟
论文名称:《ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks》
论文地址:https://arxiv.org/abs/1910.03151
代码地址:https://github.com/BangguWu/ECANet
3.1 原理
先前的方法大多致力于开发更复杂的注意力模块,以实现更好的性能,这不可避免地增加了模型的复杂性。为了克服性能和复杂性之间的矛盾,作者提出了一种有效的通道关注(ECA)模块,该模块只增加了少量的参数,却能获得明显的性能增益。

3.2 代码
import torch
import torch.nn as nn
class ECA(nn.Module):
def __init__(self, c1, c2, k_size=3):
super(ECA, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.conv = nn.Conv1d(
1, 1, kernel_size=k_size, padding=(k_size - 1) // 2, bias=False
)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
y = self.avg_pool(x)
y = self.conv(y.squeeze(-1).transpose(-1, -2)).transpose(-1, -2).unsqueeze(-1)
y = self.sigmoid(y)
return x * y.expand_as(x)
4. CA 注意力模块🌟
论文名称:《Coordinate Attention for Efficient Mobile Network Design》
论文地址:https://arxiv.org/abs/2103.02907
4.1 原理
先前的轻量级网络的注意力机制大都采用SE模块,仅考虑了通道间的信息,忽略了位置信息。尽管后来的BAM和CBAM尝试在降低通道数后通过卷积来提取位置注意力信息,但卷积只能提取局部关系,缺乏长距离关系提取的能力。为此,论文提出了新的高效注意力机制coordinate attention (CA),能够将横向和纵向的位置信息编码到channel attention中,使得移动网络能够关注大范围的位置信息又不会带来过多的计算量。
coordinate attention的优势主要有以下几点:
- 不仅获取了通道间信息,还考虑了方向相关的位置信息,有助于模型更好地定位和识别目标;
- 足够灵活和轻量,能够简单地插入移动网络的核心结构中;
- 可以作为预训练模型用于多种任务中,如检测和分割,均有不错的性能提升。

4.2 代码
import torch
import torch.nn as nn
class h_sigmoid(nn.Module):
def __init__(self, inplace=True):
super(h_sigmoid, self).__init__()
self.relu = nn.ReLU6(inplace=inplace)
def forward(self, x):
return self.relu(x + 3) / 6
class h_swish(nn.Module):
def __init__(self, inplace=True):
super(h_swish, self).__init__()
self.sigmoid = h_sigmoid(inplace=inplace)
def forward(self, x):
return x * self.sigmoid(x)
class CoordAtt(nn.Module):
def __init__(self, inp, oup, reduction=32):
super(CoordAtt, self).__init__()
self.pool_h = nn.AdaptiveAvgPool2d((None, 1))
self.pool_w = nn.AdaptiveAvgPool2d((1, None))
mip = max(8, inp // reduction)
self.conv1 = nn.Conv2d(inp, mip, kernel_size=1, stride=1, padding=0)
self.bn1 = nn.BatchNorm2d(mip)
self.act = h_swish()
self.conv_h = nn.Conv2d(mip, oup, kernel_size=1, stride=1, padding=0)
self.conv_w = nn.Conv2d(mip, oup, kernel_size=1, stride=1, padding=0)
def forward(self, x):
identity = x
n, c, h, w = x.size()
# c*1*W
x_h = self.pool_h(x)
# c*H*1
# C*1*h
x_w = self.pool_w(x).permute(0, 1, 3, 2)
y = torch.cat([x_h, x_w], dim=2)
# C*1*(h+w)
y = self.conv1(y)
y = self.bn1(y)
y = self.act(y)
x_h, x_w = torch.split(y, [h, w], dim=2)
x_w = x_w.permute(0, 1, 3, 2)
a_h = self.conv_h(x_h).sigmoid()
a_w = self.conv_w(x_w).sigmoid()
out = identity * a_w * a_h
return out
5. 添加方式💡
大致的修改方式如下:
在
Y
O
L
O
v
5
YOLOv5
YOLOv5 或
Y
O
L
O
v
7
YOLOv7
YOLOv7 中添加注意力机制可分为如下
5
5
5 步,以在 yolov5s 中添加 SE 注意力机制为例子:
- 在
yolov5/models文件夹下新建一个yolov5s_SE.yaml; - 将本文上面提供的
SE注意力代码添加到common.py文件末尾或新建一个文件放进去; - 将
SE这个类的名字加入到yolov5/models/yolo.py中; - 修改
yolov5s_SE.yaml,将SE注意力加到你想添加的位置; - 修改
train.py文件的'--cfg'默认参数,随后就可以开始训练了。
详细的修改方式如下:
- 第
1
1
1 步:在
yolov5/models文件夹下新建一个yolov5_SE.yaml,将yolov5s.yaml文件内容拷贝粘贴到我们新建的yolov5s_SE.yaml文件中等待第 4 4 4 步使用; - 第
2
2
2 步:将本文上面提供的
SE注意力代码添加到yolov5/models/common.py文件末尾或新建一个文件放进去;
import torch
import torch.nn as nn
class SE(nn.Module):
def __init__(self, c1, c2, ratio=16):
super(SE, self).__init__()
# c*1*1
self.avgpool = nn.AdaptiveAvgPool2d(1)
self.l1 = nn.Linear(c1, c1 // ratio, bias=False)
self.relu = nn.ReLU(inplace=True)
self.l2 = nn.Linear(c1 // ratio, c1, bias=False)
self.sig = nn.Sigmoid()
def forward(self, x):
b, c, _, _ = x.size()
y = self.avgpool(x).view(b, c)
y = self.l1(y)
y = self.relu(y)
y = self.l2(y)
y = self.sig(y)
y = y.view(b, c, 1, 1)
return x * y.expand_as(x)
- 第
3
3
3 步:将
SE这个类的名字加入到yolov5/models/yolo.py如下位置;

- 第
4
4
4 步:修改
yolov5s_SE.yaml,将SE注意力加到你想添加的位置;常见的位置有 C 3 C3 C3 模块后面, N e c k Neck Neck 中,也可以在主干的 S P P F SPPF SPPF 前添加一层;我这里演示添加到 S P P F SPPF SPPF 上一层:
将[-1, 1, SE,[1024]],添加到SPPF的上一层,即下图中所示位置:

加到这里还没完,还有两个细节需要注意!🌟
当在网络中添加了新的层之后,那么该层网络后续的层的编号都会发生改变,看下图,原本Detect 指定的是
[
17
,
20
,
23
]
[17,20,23]
[17,20,23] 层,所以在我们添加了 SE 注意力层之后也要对 Detect 的参数进行修改,即原来的
17
17
17 层变成了
18
18
18 层;原来的
20
20
20 层变成了
21
21
21 层;原来的
23
23
23 层变成了
24
24
24 层;所以 Detecet 的 from 系数要改为
[
18
,
21
,
24
]
[18,21,24]
[18,21,24]

同样的,Concat 的 from 系数也要修改,这样才能保持原网络结构不发生特别大的改变,我们刚才把 SE 层加到了第
9
9
9 层,所以第
9
9
9 层之后的编号都会加
1
1
1 ,这里我们要把后面两个 Concat 的 from 系数分别由
[
−
1
,
14
]
,
[
−
1
,
10
]
[-1,14],[-1,10]
[−1,14],[−1,10] 改为
[
−
1
,
15
]
,
[
−
1
,
11
]
[-1,15],[-1,11]
[−1,15],[−1,11]

如果这一步的原理大家没看懂的话,可以看看我的哔哩哔哩视频,我讲解了yaml文件的原理:点击跳转
- 第
5
5
5 步:修改
train.py文件的'--cfg'默认参数,在'--cfg'后的default=后面加上yolov5s_SE.yaml的路径,随后就可以开始训练了。

在训练时会打印模型的结构,当出现下面的结构时,就代表我们添加成功了:

最后放上我加入 SE 注意力层后完整的配置文件 yolov5s_SE.yaml
# Parameters
nc: 80 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 v6.0 backbone+SE
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3, [1024]],
[-1, 1, SE, [1024]], #SE
[-1, 1, SPPF, [1024, 5]], # 10
]
# YOLOv5+SE v6.0 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 14
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 18 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 15], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 21 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 11], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 24 (P5/32-large)
[[18, 21, 24], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
6. 添加方式的补充说明💡
可能到这里大家有一个误区,错误的认为只要是注意力模块就把模块名加 yolo.py 的如下位置就行了,其实并不是这样!
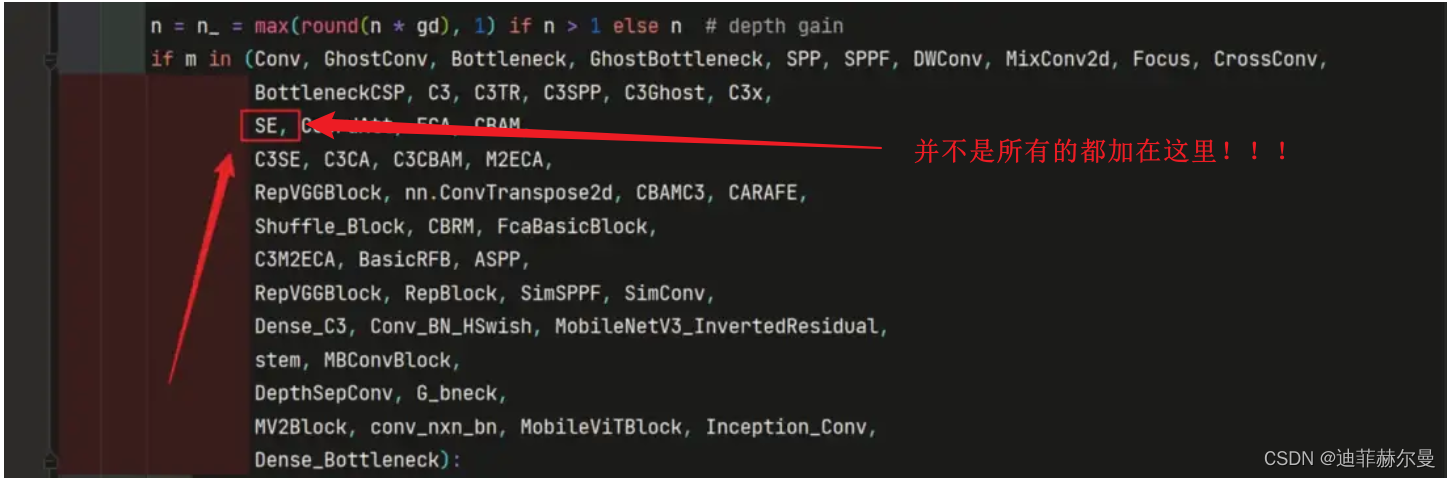
加到哪里?怎么加?这取决于你模块的写法。
下面我介绍另一种添加方式,这种添加方式并不需要在上图位置添加模块名,需要我们另外写一条elif语句,在 python 语言中,缩进是很重要的,有很多同学会忽略这一点,这里我推荐大家加到nn.BatchNorm2d这句下面,和这条代码保持缩进一致。
比如我想添加 SimAM 模块,我可以这样添加:

另外 yaml 文件中 模块的 args 参数的写法也是取决于你 yolo.py 这部分怎么写的,二者是需要配套的。
同样是 SimAM 模块 ,这次的 yaml 可以这样写,不管你添加什么位置,args 的参数始终是 1e-4 。
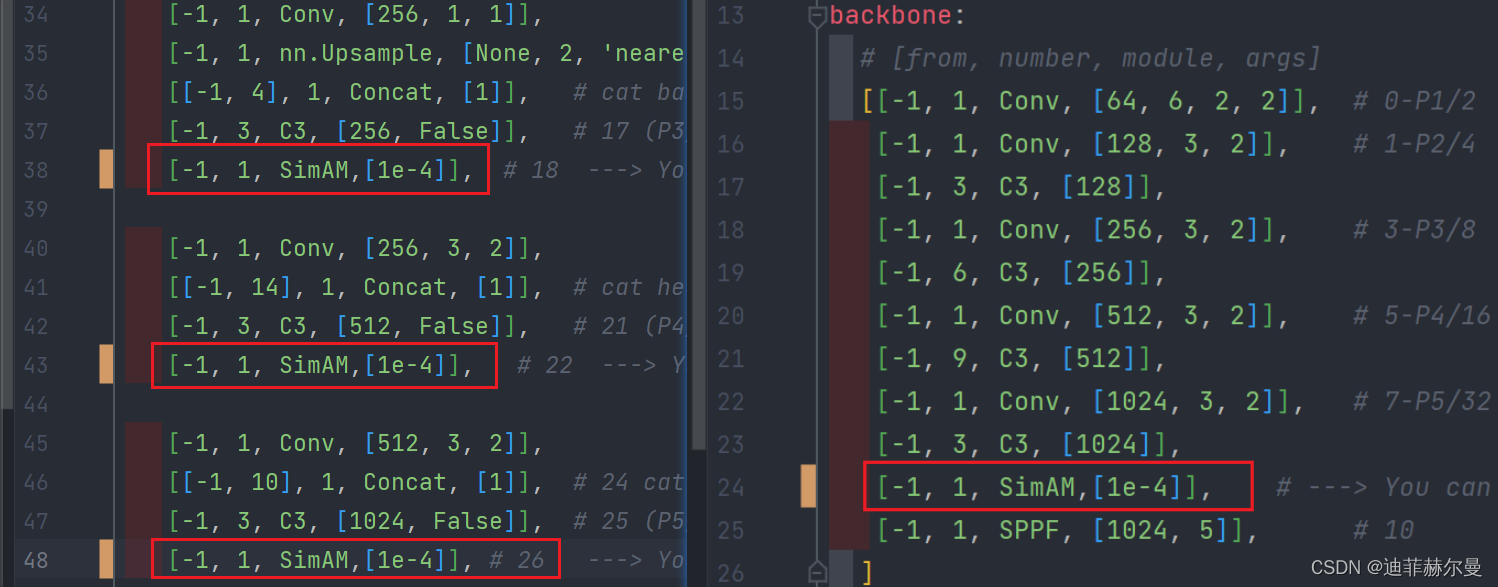
7. SimAM 注意力模块 🍀
论文名称:《SimAM: A Simple, Parameter-Free Attention Module for Convolutional Neural Networks》
论文地址:http://proceedings.mlr.press/v139/yang21o/yang21o.pdf
代码地址:https://github.com/ZjjConan/SimAM
7.1 原理
在这篇论文中,我们提出了一个概念上简单但非常有效的注意力模块,用于卷积神经网络。与现有的基于通道和空间的注意力模块不同,我们的模块通过推断特征图中的三维注意力权重来工作,而无需向原始网络添加参数。具体而言,我们基于一些著名的神经科学理论,并提出了优化能量函数以找到每个神经元重要性的方法。我们进一步推导了能量函数的快速闭合形式解,并展示了该解可以用不到十行代码实现。该模块的另一个优点是,大多数运算符是基于定义的能量函数解的选择,避免了过多的结构调整的工作。对各种视觉任务的定量评估表明,所提出的模块具有灵活性和有效性,可以提高许多ConvNets的表征能力。

7.2 代码
import torch
import torch.nn as nn
class SimAM(torch.nn.Module):
def __init__(self, e_lambda=1e-4):
super(SimAM, self).__init__()
self.activaton = nn.Sigmoid()
self.e_lambda = e_lambda
def forward(self, x):
b, c, h, w = x.size()
n = w * h - 1
x_minus_mu_square = (x - x.mean(dim=[2, 3], keepdim=True)).pow(2)
y = (
x_minus_mu_square
/ (
4
* (x_minus_mu_square.sum(dim=[2, 3], keepdim=True) / n + self.e_lambda)
)
+ 0.5
)
return x * self.activaton(y)
elif m in [SimAM]:
args = [*args[:]]
[-1, 1, SimAM, [1e-4]], # args 不需要改变
8. S2-MLPv2 注意力模块🍀
论文名称:《S^2-MLPV2: IMPROVED SPATIAL-SHIFT MLP ARCHITECTURE FOR VISION》
论文地址:https://arxiv.org/pdf/2108.01072.pdf
4.1 原理
最近,基于多层感知机(MLP)的视觉骨干网络开始出现。相比于CNN和视觉Transformer,具有较少归纳偏差的基于MLP的视觉架构在图像识别中取得了有竞争力的性能。其中,采用直接的空间位移操作的空间位移MLP (S2-MLP)在性能上优于包括MLP-mixer和ResMLP在内的开创性工作。最近,使用具有金字塔结构的较小补丁,Vision Permutator (ViP)和Global Filter Network (GFNet)在性能上优于S2-MLP。在本文中,我们改进了S2-MLP视觉骨干网络。我们沿通道维度扩展特征图,并将扩展后的特征图分成几个部分。我们对这些分割部分进行不同的空间位移操作。同时,我们利用分割注意力操作来融合这些分割部分。此外,与之前的方法类似,我们采用较小规模的补丁,并使用金字塔结构来提高图像识别准确性。我们将改进后的空间位移MLP视觉骨干网络称为S2-MLPv2。使用5500万个参数,我们的中等规模模型S2-MLPv2-Medium在ImageNet-1K基准测试中,使用224×224的图像,在没有自注意力和外部训练数据的情况下,实现了83.6%的top-1准确率。

图:S2-MLP和提出的S2-MLPv2之间的空间位移操作的比较。在S2-MLP中,通道被平均分成四个部分,每个部分沿不同的方向进行位移。在位移后的通道上进行MLP操作。相比之下,在S2-MLPv2中,
c
c
c 通道特征图被扩展为
3
c
3c
3c 通道特征图。然后,扩展的特征图沿通道维度被平均分成三个部分。对于每个部分,我们进行不同的空间位移操作。然后,通过分割注意力操作,将位移后的部分合并以生成
c
c
c 通道特征图。
8.2 代码
import numpy as np
import torch
from torch import nn
from torch.nn import init
def spatial_shift1(x):
b, w, h, c = x.size()
x[:, 1:, :, : c // 4] = x[:, : w - 1, :, : c // 4]
x[:, : w - 1, :, c // 4 : c // 2] = x[:, 1:, :, c // 4 : c // 2]
x[:, :, 1:, c // 2 : c * 3 // 4] = x[:, :, : h - 1, c // 2 : c * 3 // 4]
x[:, :, : h - 1, 3 * c // 4 :] = x[:, :, 1:, 3 * c // 4 :]
return x
def spatial_shift2(x):
b, w, h, c = x.size()
x[:, :, 1:, : c // 4] = x[:, :, : h - 1, : c // 4]
x[:, :, : h - 1, c // 4 : c // 2] = x[:, :, 1:, c // 4 : c // 2]
x[:, 1:, :, c // 2 : c * 3 // 4] = x[:, : w - 1, :, c // 2 : c * 3 // 4]
x[:, : w - 1, :, 3 * c // 4 :] = x[:, 1:, :, 3 * c // 4 :]
return x
class SplitAttention(nn.Module):
def __init__(self, channel=512, k=3):
super().__init__()
self.channel = channel
self.k = k
self.mlp1 = nn.Linear(channel, channel, bias=False)
self.gelu = nn.GELU()
self.mlp2 = nn.Linear(channel, channel * k, bias=False)
self.softmax = nn.Softmax(1)
def forward(self, x_all):
b, k, h, w, c = x_all.shape
x_all = x_all.reshape(b, k, -1, c)
a = torch.sum(torch.sum(x_all, 1), 1)
hat_a = self.mlp2(self.gelu(self.mlp1(a)))
hat_a = hat_a.reshape(b, self.k, c)
bar_a = self.softmax(hat_a)
attention = bar_a.unsqueeze(-2)
out = attention * x_all
out = torch.sum(out, 1).reshape(b, h, w, c)
return out
class S2Attention(nn.Module):
def __init__(self, channels=512):
super().__init__()
self.mlp1 = nn.Linear(channels, channels * 3)
self.mlp2 = nn.Linear(channels, channels)
self.split_attention = SplitAttention()
def forward(self, x):
b, c, w, h = x.size()
x = x.permute(0, 2, 3, 1)
x = self.mlp1(x)
x1 = spatial_shift1(x[:, :, :, :c])
x2 = spatial_shift2(x[:, :, :, c : c * 2])
x3 = x[:, :, :, c * 2 :]
x_all = torch.stack([x1, x2, x3], 1)
a = self.split_attention(x_all)
x = self.mlp2(a)
x = x.permute(0, 3, 1, 2)
return x
elif m in [S2Attention]:
c1 = ch[f]
args = [c1]
[-1, 1, S2Attention, [1024]], # 1024 代表通道数
9. NAMAttention 注意力模块🍀
论文名称:《NAM: Normalization-based Attention Module》
论文地址:https://arxiv.org/pdf/2111.12419.pdf
代码地址:https://github.com/Christian-lyc/NAM
9.1 原理
识别较不显著的特征对于模型压缩至关重要。然而,在革命性的注意力机制中,这一点尚未得到研究。在本研究中,我们提出了一种新颖的基于规范化的注意力模块(NAM),它抑制了较不显著的权重。它对注意力模块应用权重稀疏惩罚,从而使其在保持类似性能的同时更加计算高效。在Resnet和Mobilenet上与其他三种注意力机制进行比较表明,我们的方法具有更高的准确性。

9.2 代码
import torch.nn as nn
import torch
from torch.nn import functional as F
class Channel_Att(nn.Module):
def __init__(self, channels):
super(Channel_Att, self).__init__()
self.channels = channels
self.bn2 = nn.BatchNorm2d(self.channels, affine=True)
def forward(self, x):
residual = x
x = self.bn2(x)
weight_bn = self.bn2.weight.data.abs() / torch.sum(self.bn2.weight.data.abs())
x = x.permute(0, 2, 3, 1).contiguous()
x = torch.mul(weight_bn, x)
x = x.permute(0, 3, 1, 2).contiguous()
x = torch.sigmoid(x) * residual #
return x
class NAMAttention(nn.Module):
def __init__(self, channels):
super(NAMAttention, self).__init__()
self.Channel_Att = Channel_Att(channels)
def forward(self, x):
x_out1 = self.Channel_Att(x)
return x_out1
elif m in [NAMAttention]:
c1 = ch[f]
args = [c1]
[-1, 1, NAMAttention, [1024]], # 1024 代表通道数
10. Criss-CrossAttention 注意力模块🍀
论文名称:《CCNet: Criss-Cross Attention for Semantic Segmentation》
论文地址:https://arxiv.org/pdf/1811.11721.pdf
代码地址:https://github.com/speedinghzl/CCNet
10.1 原理

在语义分割和物体检测等视觉理解问题中,上下文信息至关重要。我们提出了一种名为Criss-Cross Network (CCNet) 的方法,以非常有效和高效的方式获取完整的图像上下文信息。具体来说,对于每个像素,一个新颖的交叉注意力模块收集其交叉路径上所有像素的上下文信息。通过进一步的循环操作,每个像素最终可以捕获完整的图像依赖关系。此外,我们提出了一种类别一致的损失,用于强制交叉注意力模块产生更具辨别力的特征。总体而言,CCNet 具有以下优点:1) 对GPU内存友好。与非局部块相比,提出的循环交叉注意力模块使用的GPU内存减少了11倍。2) 高计算效率。循环交叉注意力显著减少了非局部块的FLOPs,约为其85%。3) 具备最先进的性能。我们在包括Cityscapes、ADE20K、LIP以及COCO等语义分割基准数据集上进行了大量实验。特别是,在Cityscapes测试集、ADE20K验证集和LIP验证集上,我们的CCNet分别实现了81.9%、45.76%和55.47%的mIoU得分,这些是最新的最先进结果。
10.2 代码
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.nn import Softmax
def INF(B, H, W, device):
# Create an infinite diagonal tensor on the specified device
return (
-torch.diag(torch.tensor(float("inf"), device=device).repeat(H), 0)
.unsqueeze(0)
.repeat(B * W, 1, 1)
)
class CrissCrossAttention(nn.Module):
"""Criss-Cross Attention Module"""
def __init__(self, in_dim):
super(CrissCrossAttention, self).__init__()
self.query_conv = nn.Conv2d(
in_channels=in_dim, out_channels=in_dim // 8, kernel_size=1
)
self.key_conv = nn.Conv2d(
in_channels=in_dim, out_channels=in_dim // 8, kernel_size=1
)
self.value_conv = nn.Conv2d(
in_channels=in_dim, out_channels=in_dim, kernel_size=1
)
self.softmax = Softmax(dim=3)
self.INF = INF
self.gamma = nn.Parameter(torch.zeros(1))
def forward(self, x):
device = x.device
self.to(device)
m_batchsize, _, height, width = x.size()
proj_query = self.query_conv(x)
proj_query_H = (
proj_query.permute(0, 3, 1, 2)
.contiguous()
.view(m_batchsize * width, -1, height)
.permute(0, 2, 1)
)
proj_query_W = (
proj_query.permute(0, 2, 1, 3)
.contiguous()
.view(m_batchsize * height, -1, width)
.permute(0, 2, 1)
)
proj_key = self.key_conv(x)
proj_key_H = (
proj_key.permute(0, 3, 1, 2)
.contiguous()
.view(m_batchsize * width, -1, height)
)
proj_key_W = (
proj_key.permute(0, 2, 1, 3)
.contiguous()
.view(m_batchsize * height, -1, width)
)
proj_value = self.value_conv(x)
proj_value_H = (
proj_value.permute(0, 3, 1, 2)
.contiguous()
.view(m_batchsize * width, -1, height)
)
proj_value_W = (
proj_value.permute(0, 2, 1, 3)
.contiguous()
.view(m_batchsize * height, -1, width)
)
energy_H = (
(
torch.bmm(proj_query_H, proj_key_H)
+ self.INF(m_batchsize, height, width, device)
)
.view(m_batchsize, width, height, height)
.permute(0, 2, 1, 3)
)
energy_W = torch.bmm(proj_query_W, proj_key_W).view(
m_batchsize, height, width, width
)
concate = self.softmax(torch.cat([energy_H, energy_W], 3))
att_H = (
concate[:, :, :, 0:height]
.permute(0, 2, 1, 3)
.contiguous()
.view(m_batchsize * width, height, height)
)
# print(concate)
# print(att_H)
att_W = (
concate[:, :, :, height : height + width]
.contiguous()
.view(m_batchsize * height, width, width)
)
out_H = (
torch.bmm(proj_value_H, att_H.permute(0, 2, 1))
.view(m_batchsize, width, -1, height)
.permute(0, 2, 3, 1)
)
out_W = (
torch.bmm(proj_value_W, att_W.permute(0, 2, 1))
.view(m_batchsize, height, -1, width)
.permute(0, 2, 1, 3)
)
# print(out_H.size(),out_W.size())
return self.gamma * (out_H + out_W) + x
elif m in [CrissCrossAttention]:
c1 = ch[f]
args = [c1]
[-1, 1, CrissCrossAttention, [1024]], # 1024 代表通道数
11. GAMAttention 注意力模块🍀
论文名称:《Global Attention Mechanism: Retain Information to Enhance Channel-Spatial Interactions》
论文地址:https://arxiv.org/pdf/2112.05561v1.pdf
11.1 原理
各种注意机制已经被研究用于改善各种计算机视觉任务的性能。然而,先前的方法忽视了在通道和空间方面保留信息以增强跨维度交互的重要性。因此,我们提出了一种全局注意机制,通过减少信息损失和放大全局交互表示来提升深度神经网络的性能。我们引入了3D排列和多层感知机用于通道注意,同时还引入了卷积空间注意的子模块。对于在CIFAR-100和ImageNet-1K上进行的图像分类任务的评估表明,我们的方法在ResNet和轻量级MobileNet上稳定地优于几种最近的注意机制。


通道注意子模块使用3D排列来跨三个维度保留信息。然后,它使用两层MLP(多层感知机)放大跨维度的通道-空间依赖关系。(MLP是一个编码器-解码器结构,具有与BAM相同的减少比例r)。通道注意子模块如图2所示。
在空间注意子模块中,为了关注空间信息,我们使用两个卷积层进行空间信息融合。我们还使用与通道注意子模块相同的减少比例r,与BAM相同。同时,最大池化会减少信息并对结果产生负面影响。为了进一步保留特征图,我们去除了池化操作。结果是,空间注意模块有时会显著增加参数的数量。为了防止参数数量显著增加,我们在ResNet50中采用了具有通道随机洗牌的组卷积。不带组卷积的空间注意子模块如图3所示。
11.2 代码
import numpy as np
import torch
from torch import nn
from torch.nn import init
def channel_shuffle(x, groups=2):
B, C, H, W = x.size()
out = x.view(B, groups, C // groups, H, W).permute(0, 2, 1, 3, 4).contiguous()
out = out.view(B, C, H, W)
return out
class GAMAttention(nn.Module):
def __init__(self, c1, c2, group=True, rate=4):
super(GAMAttention, self).__init__()
self.channel_attention = nn.Sequential(
nn.Linear(c1, int(c1 / rate)),
nn.ReLU(inplace=True),
nn.Linear(int(c1 / rate), c1),
)
self.spatial_attention = nn.Sequential(
(
nn.Conv2d(c1, c1 // rate, kernel_size=7, padding=3, groups=rate)
if group
else nn.Conv2d(c1, int(c1 / rate), kernel_size=7, padding=3)
),
nn.BatchNorm2d(int(c1 / rate)),
nn.ReLU(inplace=True),
(
nn.Conv2d(c1 // rate, c2, kernel_size=7, padding=3, groups=rate)
if group
else nn.Conv2d(int(c1 / rate), c2, kernel_size=7, padding=3)
),
nn.BatchNorm2d(c2),
)
def forward(self, x):
b, c, h, w = x.shape
x_permute = x.permute(0, 2, 3, 1).view(b, -1, c)
x_att_permute = self.channel_attention(x_permute).view(b, h, w, c)
x_channel_att = x_att_permute.permute(0, 3, 1, 2)
x = x * x_channel_att
x_spatial_att = self.spatial_attention(x).sigmoid()
x_spatial_att = channel_shuffle(x_spatial_att, 4)
out = x * x_spatial_att
return out
elif m in [GAMAttention]:
c1, c2 = ch[f], args[0]
if c2 != no:
c2 = make_divisible(c2 * gw, ch_mul)
args = [c1, c2, *args[1:]]
[-1, 1, GAMAttention, [1024, True, 4]], # 1024 代表通道数
12. Selective Kernel Attention 注意力模块🍀
论文名称:《Selective Kernel Networks》
论文地址:https://arxiv.org/pdf/1903.06586.pdf
代码地址:https://github.com/implus/SKNet
12.1 原理
在标准的卷积神经网络中,每层人工神经元的感受野被设计为具有相同的大小。神经科学界已经广泛认识到,视觉皮层神经元的感受野大小会受到刺激的调节,然而在构建CNN时很少考虑这一点。我们提出了一种动态选择机制,使得CNN中的每个神经元可以根据多个输入信息的尺度自适应地调整其感受野大小。我们设计了一个称为Selective Kernel (SK)单元的构建块,其中使用softmax注意力将具有不同核大小的多个分支进行融合,这种注意力受到这些分支中的信息的指导。对这些分支的不同注意力产生了融合层中神经元的有效感受野的不同大小。多个SK单元堆叠成一个深度网络,称为Selective Kernel Networks (SKNets)。在 ImageNet 和 CIFAR 基准测试中,我们经验证明SKNet 在模型复杂度较低的情况下胜过了现有的最先进架构。详细分析表明,SKNet中的神经元能够捕捉具有不同尺度的目标对象,从而验证了神经元根据输入自适应调整感受野大小的能力。

12.2 代码
from collections import OrderedDict
import numpy as np
import torch
from torch import nn
from torch.nn import init
class SKAttention(nn.Module):
def __init__(self, channel=512, kernels=[1, 3, 5, 7], reduction=16, group=1, L=32):
super().__init__()
self.d = max(L, channel // reduction)
self.convs = nn.ModuleList([])
for k in kernels:
self.convs.append(
nn.Sequential(
OrderedDict(
[
(
"conv",
nn.Conv2d(
channel,
channel,
kernel_size=k,
padding=k // 2,
groups=group,
),
),
("bn", nn.BatchNorm2d(channel)),
("relu", nn.ReLU()),
]
)
)
)
self.fc = nn.Linear(channel, self.d)
self.fcs = nn.ModuleList([])
for i in range(len(kernels)):
self.fcs.append(nn.Linear(self.d, channel))
self.softmax = nn.Softmax(dim=0)
def forward(self, x):
bs, c, _, _ = x.size()
conv_outs = []
### split
for conv in self.convs:
conv_outs.append(conv(x))
feats = torch.stack(conv_outs, 0) # k,bs,channel,h,w
### fuse
U = sum(conv_outs) # bs,c,h,w
### reduction channel
S = U.mean(-1).mean(-1) # bs,c
Z = self.fc(S) # bs,d
### calculate attention weight
weights = []
for fc in self.fcs:
weight = fc(Z)
weights.append(weight.view(bs, c, 1, 1)) # bs,channel
attention_weughts = torch.stack(weights, 0) # k,bs,channel,1,1
attention_weughts = self.softmax(attention_weughts) # k,bs,channel,1,1
### fuse
V = (attention_weughts * feats).sum(0)
return V
elif m in [SKAttention]: # channels args
c2 = ch[f]
args = [c2, *args[0:]]
[-1, 1, SKAttention, [[1, 3, 5, 7], 16, 1, 32]], # args 都不需要改变
14. A2-Net 注意力模块🍀
论文名称:《A2-Nets: Double Attention Networks》
论文地址:https://arxiv.org/pdf/1810.11579.pdf
14.1 原理
学习捕捉远距离关系对于图像/视频识别是基础性的。现有的CNN模型通常依靠增加深度来建模这些关系,这在很大程度上效率低下。在这项工作中,我们提出了“双重注意力块”,这是一种新颖的组件,它可以从输入图像/视频的整个时空空间聚合和传播有信息的全局特征,使得后续的卷积层可以高效地访问整个空间的特征。该组件设计了一个双重注意力机制的两个步骤,第一步通过二阶注意力池将整个空间的特征聚集到一个紧凑的集合中,第二步通过另一个注意力机制自适应地选择和分配特征到每个位置。所提出的双重注意力块易于采用,并可以方便地插入到现有的深度神经网络中。我们进行了大量的消融研究和实验证明其性能。在图像识别任务中,使用我们的双重注意力块装备的ResNet-50在ImageNet-1k数据集上胜过了更大的ResNet-152架构,参数数量减少了40%以上,FLOPs也减少了。在动作识别任务中,我们提出的模型在Kinetics和UCF-101数据集上取得了最先进的结果,并具有比最近的研究工作更高的效率。

14.2 代码
import numpy as np
import torch
from torch import nn
from torch.nn import init
import torch.nn.functional as F
class DoubleAttention(nn.Module):
def __init__(self, in_channels, c_m, c_n, reconstruct=True):
super().__init__()
self.in_channels = in_channels
self.reconstruct = reconstruct
self.c_m = c_m
self.c_n = c_n
self.convA = nn.Conv2d(in_channels, c_m, 1)
self.convB = nn.Conv2d(in_channels, c_n, 1)
self.convV = nn.Conv2d(in_channels, c_n, 1)
if self.reconstruct:
self.conv_reconstruct = nn.Conv2d(c_m, in_channels, kernel_size=1)
self.init_weights()
def init_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
init.kaiming_normal_(m.weight, mode="fan_out")
if m.bias is not None:
init.constant_(m.bias, 0)
elif isinstance(m, nn.BatchNorm2d):
init.constant_(m.weight, 1)
init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
init.normal_(m.weight, std=0.001)
if m.bias is not None:
init.constant_(m.bias, 0)
def forward(self, x):
b, c, h, w = x.shape
assert c == self.in_channels
A = self.convA(x) # b,c_m,h,w
B = self.convB(x) # b,c_n,h,w
V = self.convV(x) # b,c_n,h,w
tmpA = A.view(b, self.c_m, -1)
attention_maps = F.softmax(B.view(b, self.c_n, -1), dim=1)
attention_vectors = F.softmax(V.view(b, self.c_n, -1), dim=1)
# step 1: feature gating
global_descriptors = torch.bmm(
tmpA, attention_maps.permute(0, 2, 1)
) # b.c_m,c_n
# step 2: feature distribution
tmpZ = global_descriptors.matmul(attention_vectors) # b,c_m,h*w
tmpZ = tmpZ.view(b, self.c_m, h, w) # b,c_m,h,w
if self.reconstruct:
tmpZ = self.conv_reconstruct(tmpZ)
return tmpZ
elif m in [DoubleAttention]: # channels args
c2 = ch[f]
args = [c2, *args[0:]]
[-1, 1, DoubleAttention, [128, 128,True]], # args 都不需要改变
更多注意力代码欢迎关注我的《目标检测蓝皮书》💖
番外篇 | 20+ 种注意力机制及代码 适用于YOLOv5/v7/v8
15. DANPositional 注意力模块

16. DANChannel 注意力模块

17. RESNest 注意力模块

18. Harmonious 注意力模块

19. SpatialAttention 注意力模块

19. RANet 注意力模块

20. Co-excite 注意力模块

21. EfficientAttention 注意力模块

22. X-Linear 注意力模块

23. SlotAttention 注意力模块

24. Axial 注意力模块

25. RFA 注意力模块

26. Attention-BasedDropout 注意力模块

27. ReverseAttention 注意力模块

28. CrossAttention 注意力模块

29. Perceiver 注意力模块

30. Criss-CrossAttention 注意力模块


31. BoostedAttention 注意力模块

32. Prophet 注意力模块

33. S3TA 注意力模块

34. Self-CriticAttention 注意力模块

35. BayesianAttentionBeliefNetworks 注意力模块

36. Expectation-MaximizationAttention 注意力模块

37. GaussianAttention 注意力模块

代码持续更新中。。。
本人更多 YOLOv5/v7 实战内容导航🍀🌟🚀
-
手把手带你YOLOv5/v7 (v5.0-v7.0)添加注意力机制(一)(并附上30多种顶会Attention原理图)🌟强烈推荐🍀新增8种
-
空间金字塔池化改进 SPP / SPPF / SimSPPF / ASPP / RFB / SPPCSPC / SPPFCSPC🚀
2022/10/30更新日志:新增加 8种注意力机制源码6-13,可适配YOLO系列算法。
2023/01/07更新日志:修改了文章结构,对部分章节增加了更加详细的解释。
2023/02/011更新日志:增加了A2-Net注意力代码。
2023/5/17更新日志: 新增部分注意力理论及论文地址。
2023/6/15更新日志:新增了6说明,更改了 7-13 代码的添加方式。
2024/2/5更新日志:格式化源代码。
有问题欢迎大家指正,如果感觉有帮助的话请点赞支持下👍📖🌟
!!禁止转载!!



















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











