







kNN算法伪代码
对未知类别属性的数据集中的每个点依次执行以下操作:
- 计算已知类别数据中的每个点与当前点之间的距离;
- 按照距离递增次序排序;
- 选取与当前点距离最小的k个点;
- 确定前k个点所在类别的出现频率;
- 返回前k个点出现频率最高的类别作为当前点的预测分类。
from numpy import *
from os import listdir
import operator
# knn算法
def classify0(inX, dataSet, labels, k):
dataSetSize = dataSet.shape[0]
# 计算距离
diffMat = tile(inX, (dataSetSize, 1)) - dataSet
sqDiffMat = pow(diffMat, 2)
sqDistance = sqDiffMat.sum(axis=1)
distances = pow(sqDistance, 0.5)
# 选择距离最小的k个点
sortedDistance = distances.argsort() # 对距离进行排序,返回排序后的元素下标
class_count = {}
for i in range(k):
vote_ilabels = labels[sortedDistance[i]]
# 返回键“vote_ilabels”的值,不存在返回0
class_count[vote_ilabels] = class_count.get(vote_ilabels, 0) + 1 # 专门对列表计数
# 排序
sorted_classcount = sorted(class_count.items(),
key = operator.itemgetter(1) , reverse = True) # 按照值排序,降序
return sorted_classcount[0][0]
# 2-2文本转化为numpy解析
def file2matrix(filename):
fr = open(filename)
array_olines = fr.readlines() # 所有行读成列表
# 获得文件行数
lines_counts = len(array_olines)
# 创建一个全为0的矩阵
return_mat = zeros((lines_counts, 3))
class_lable_vector = []
index = 0
# 解析文件数据到列表
for line in array_olines:
line = line.strip()
list_from_line = line.split('\t')
return_mat[index, : ] = list_from_line[0:3]
class_lable_vector.append((int(list_from_line[-1])))
index += 1
return return_mat, class_lable_vector
# 2-3准备数据,归一化数值
def auto_norm(dataSet):
minVals = dataSet.min(0) # 每一列的最小值
maxVals = dataSet.max(0) # 每一列的最大值
ranges = maxVals - minVals #每一列中最小最大值的差值
normDataSet = zeros(shape(dataSet)) #创建一个和dataset维度一样的全为0矩阵
m = dataSet.shape[0] # dataSet的行数
normDataSet = dataSet - tile(minVals, (m, 1)) # oldValue-min
normDataSet = normDataSet / tile(ranges, (m, 1)) # (oldValue-min)/ (max -min)
return normDataSet, ranges, minVals
# 2-4 测试算法
def datingClassTest():
hoRatio = 0.1
datingDataMat,datingLables = file2matrix('data_test_set2.txt')
normMat,ranges, minVals = auto_norm(datingDataMat)
m = normMat.shape[0]
numTsetVecs = int(m * hoRatio)
errorCount = 0.0
for i in range (numTsetVecs):
classifierResult = classify0(normMat[i, :],
normMat[numTsetVecs:m, :],
datingLables[numTsetVecs:m],
4)
print("The classifier come back with: %d, The real answer is: %d" \
%(classifierResult, datingLables[i]))
if classifierResult != datingLables[i]:
errorCount += 1.0
print("The total error rate is :%.4f" %(errorCount / float(numTsetVecs)))
datingClassTest()
print(file2matrix('data_test_set2.txt')[0].shape)
# 2-5 约会网站预测函数
def classifyPerson():
resultList = ['not at al', 'in small doses', 'in large doses']
# input函数允许用户自己输入数值
percentTats = float(input("percentage of time spent playing video games?"))
ffMiles = float(input("frequent flier miles earned per year?"))
iceCream = float(input("liters of ice cream consumed per year?"))
datingDataMat, datingLabels = file2matrix('data_test_set2.txt')
normMat, ranges, minVals = auto_norm(datingDataMat)
inArr = array([ffMiles, percentTats, iceCream])
classifyResult = classify0((inArr - minVals)/ ranges,
normMat,
datingLabels,
3)
print("You will probably like this person: ", resultList[classifyResult - 1])
#classifyPerson()
# 2.3 手写识别系统
def img2vect(filename):
returnVect = zeros((1, 1024))
fr = open(filename)
for i in range(32):
lineStr = fr.readline() # 读取一行
for j in range(32):
returnVect[0, 32 * i + j] = int(lineStr[j])
return returnVect
# print(img2vect('trainingDigits/0_2.txt')[0, 0:32])
# 2-6 手写数字识别系统测试算法
def handwriteingClassTest():
# 获取目录内容
hwLables = []
trainFileList = listdir('trainingDigits') # 目录下所有文件名生产一个列表
m = len(trainFileList)
trainMat = zeros((m, 1024))
# 从文件名中解析分类数字
for i in range(m):
fileNameStr = trainFileList[i]
fileStr = fileNameStr.split('.')[0]
classNumstr = int(fileStr.split('_')[0])
hwLables.append(classNumstr)
trainMat[i, :] = img2vect('trainingDigits/%s' % fileNameStr)
listFileList = listdir('testDigits')
errorCount = 0.0
mTest = len(listFileList)
for i in range(mTest):
fileNameStr = listFileList[i]
fileStr = fileNameStr.split(',')[0]
classNumstr = int(fileStr.split('_')[0])
vectorUnderTest = img2vect('testDigits/%s' % fileNameStr)
classifierResult = classify0(vectorUnderTest,
trainMat,
hwLables,
3)
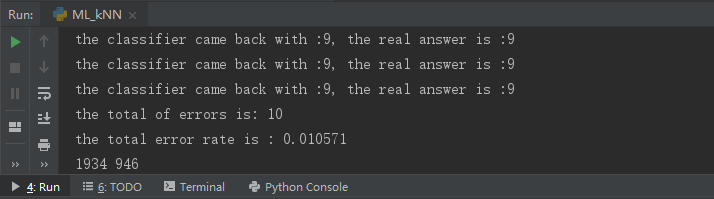
print('the classifier came back with :%d, the real answer is :%d'\
%(classifierResult, classNumstr))
if classifierResult != classNumstr:
errorCount += 1.0
print('the total of errors is: %d' %(errorCount))
print('the total error rate is : %f' %(errorCount / mTest) )
print(m,mTest)
handwriteingClassTest()
代码运行结果如下















 4802
4802











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









