







论文:Deep High-Resolution Representation Learning for Human Pose Estimation(CVPR 2019)
论文:High-Resolution Representations for Labeling Pixels and Regions(CVPR 2019)
代码:open-mmlab/mmdetection/blob/master/mmdet/models/backbones/hrnet.py
代码:HRNet
HRNet相关实验
论文中给出的实验效果不错,想用HRNet做目标检测

|

|

高分辨率模块搭建
HRNet高度模块化,首先构建其高分辨率模块
基本单元
基本采用ResNet网络中的基本模块进行搭建

左图BasicBlock:
- 两个3×3卷积,均含BN层;
- 后者不使用Relu(避免与shortcut特征相加全为正);
- 跳跃连接两种情况:输入特征通道数与输出一致时,直接相加,否则需要1×1卷积匹配维度
右图Bottleneck:
- 1×1卷积降维,3×3卷积,1×1卷积再升维,均含BN层;
- 最后一个1×1卷积后不使用Relu,Element Wise Add操作后使用;
- 跳跃连接两种情况:输入特征通道数与输出一致时,直接相加,否则需要1×1卷积匹配维度
BN_MOMENTUM = 0.1
def conv3x3(in_planes, out_planes, stride=1):
"""3x3 convolution with padding"""
return nn.Conv2d(in_planes, out_planes, kernel_size=3, stride=stride,
padding=1, bias=False)
class BasicBlock(nn.Module):
expansion = 1
def __init__(self, inplanes, planes, stride=1, downsample=None):
super(BasicBlock, self).__init__()
self.conv1 = conv3x3(inplanes, planes, stride)
self.bn1 = nn.BatchNorm2d(planes, momentum=BN_MOMENTUM)
self.relu = nn.ReLU(inplace=True)
self.conv2 = conv3x3(planes, planes)
self.bn2 = nn.BatchNorm2d(planes, momentum=BN_MOMENTUM)
self.downsample = downsample
self.stride = stride
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
if self.downsample is not None:
residual = self.downsample(x)
out += residual
out = self.relu(out)
return out
class Bottleneck(nn.Module):
expansion = 4
def __init__(self, inplanes, planes, stride=1, downsample=None):
super(Bottleneck, self).__init__()
self.conv1 = nn.Conv2d(inplanes, planes, kernel_size=1, bias=False)
self.bn1 = nn.BatchNorm2d(planes, momentum=BN_MOMENTUM)
self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=stride,
padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(planes, momentum=BN_MOMENTUM)
self.conv3 = nn.Conv2d(planes, planes * self.expansion, kernel_size=1,
bias=False)
self.bn3 = nn.BatchNorm2d(planes * self.expansion,
momentum=BN_MOMENTUM)
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
self.stride = stride
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
if self.downsample is not None:
residual = self.downsample(x)
out += residual
out = self.relu(out)
return out
高分辨率模块
HRNet可划为几个stage,stage高分辨率模块构成,若每个stage由一个高分辨率模块构成,则每个高分辨率模块代表一个stage,每stage的高分辨率模块含有不同的分支数,每个分支分辨率不同,高分辨率分支一直保持高分辨率,低分辨率分支一直保持低分辨率,结构的关键在于分支间的特征融合方式。示意图不够准确,具体结构还需看代码

创建分支
_make_one_branch : 单个分支内部辨率通道数保持不变,由 num_blocks[branch_index] 个block(ResNet基础模块)组成
- 创建分支时需要判断是否升/降维(经过 transition layer(跳转至 _make_transition_layer 代码处) 各分支维度和分辨率已匹配,一般无需处理),输入输出通道(
num_inchannels[branch_index]和num_channels[branch_index] * block.expansion(通道扩张率) )是否一致,用1×1卷积匹配维度,后接BN,不使用ReLU; - 顺序搭建
num_blocks[branch_index]个block,第一个block需考虑维度问题,需单独构建,[ 1 : num_blocks[branch_index]]直接使用循环搭建即可。
注意:第一个block后将num_inchannels[branch_index]重新赋值为num_channels[branch_index] * block.expansion,因为后面几个block保持维度和分辨率不变
一个模块的多个分支用_make_one_branch循环创建即可
特征融合
_make_fuse_layers:将一个模块多个分支间的特征相互融合(类似神经网络层间的连接)
-
如果分支数大于1时,需要进行特征融合
for i in range(num_branches if self.multi_scale_output else 1): -
高分辨率特征通过步长为2的3×3卷积降低分辨率与低分辨率特征融合(相加吗通道匹配),而低分辨率特征也要通过上采样(插值)匹配分辨率+1×1卷积调匹配通道与高分辨率特征融合,因此还需内嵌一层循环
for j in range(num_branches):if j > i,用1x1卷积将 j 分支特征通道数与 i 分支匹配,经过BN层后,将所有分支上采样(最近邻插值)到 i 分支相同分辨率进行融合if j = i,同分支无需融合if j < i,用步长为 2 的3×3卷积将 j 分支特征下采样(下采样i - j次)到与 i 分支相同分辨率,并匹配通道数,for k in range(i-j):if k == i - j - 1:下采次数为i - j >= 1,本来一个循环即可完成,但是最后一次下采样不使用ReLU,所以需要区别对待if k != i - j - 1:将 j 分支特征使用3x3的步长为2的卷积(不使用bias)下采样i - j -1次(i - j -1个卷积层),每个卷积层后接BN和ReLU,最后一次下采样跳转到上一个条件执行最后一次下采样
例:如上图j=0,i=2时,需要下采样i-j=2-0=2次,for k in range(i-j):⟹ \Longrightarrow ⟹k=0,1,i-j-1 = 2-0-1=1,k=0!=1先正常下采样,k=1==1跳转到上一个条件执行最后一次下采样
Jump:具体还可以跳转到后面例子中的stage3 fuse_layers
向前传播
def forward(self, x)
- 得到各分支特征图
x[i](分支数为1则无需融合特征,直接返回) - 每条分支都需要融合特征
for i in range(len(self.fuse_layers)):,融合方式 add- 融合的方式类似神经网络层,是相互的,所以还需要内嵌一个循环
for j in range(self.num_branches):i == j直接传递,无需融合i != j经过fuse_layers匹配维度及分辨率后进行融合
- 返回该分支融合的特征
- 融合的方式类似神经网络层,是相互的,所以还需要内嵌一个循环
- 返回所有分支的融合特征
高分辨率模块Pytorch代码
class HighResolutionModule(nn.Module):
def __init__(self, num_branches, blocks, num_blocks, num_inchannels,
num_channels, fuse_method, multi_scale_output=True):
super(HighResolutionModule, self).__init__()
self._check_branches(
num_branches, blocks, num_blocks, num_inchannels, num_channels)
self.num_inchannels = num_inchannels
self.fuse_method = fuse_method
self.num_branches = num_branches
self.multi_scale_output = multi_scale_output
self.branches = self._make_branches(
num_branches, blocks, num_blocks, num_channels)
self.fuse_layers = self._make_fuse_layers()
self.relu = nn.ReLU(True)
def _check_branches(self, num_branches, blocks, num_blocks,
num_inchannels, num_channels):
if num_branches != len(num_blocks):
error_msg = 'NUM_BRANCHES({}) <> NUM_BLOCKS({})'.format(
num_branches, len(num_blocks))
logger.error(error_msg)
raise ValueError(error_msg)
if num_branches != len(num_channels):
error_msg = 'NUM_BRANCHES({}) <> NUM_CHANNELS({})'.format(
num_branches, len(num_channels))
logger.error(error_msg)
raise ValueError(error_msg)
if num_branches != len(num_inchannels):
error_msg = 'NUM_BRANCHES({}) <> NUM_INCHANNELS({})'.format(
num_branches, len(num_inchannels))
logger.error(error_msg)
raise ValueError(error_msg)
def _make_one_branch(self, branch_index, block, num_blocks, num_channels,
stride=1):
downsample = None
if stride != 1 or \
self.num_inchannels[branch_index] != num_channels[branch_index] * block.expansion:
downsample = nn.Sequential(
nn.Conv2d(
self.num_inchannels[branch_index],
num_channels[branch_index] * block.expansion,
kernel_size=1, stride=stride, bias=False
),
nn.BatchNorm2d(
num_channels[branch_index] * block.expansion,
momentum=BN_MOMENTUM
),
)
layers = []
layers.append(
block(
self.num_inchannels[branch_index],
num_channels[branch_index],
stride,
downsample
)
)
self.num_inchannels[branch_index] = \
num_channels[branch_index] * block.expansion
for i in range(1, num_blocks[branch_index]):
layers.append(
block(
self.num_inchannels[branch_index],
num_channels[branch_index]
)
)
return nn.Sequential(*layers)
def _make_branches(self, num_branches, block, num_blocks, num_channels):
branches = []
for i in range(num_branches):
branches.append(
self._make_one_branch(i, block, num_blocks, num_channels)
)
return nn.ModuleList(branches)
def _make_fuse_layers(self):
if self.num_branches == 1:
return None
num_branches = self.num_branches
num_inchannels = self.num_inchannels
fuse_layers = []
for i in range(num_branches if self.multi_scale_output else 1):
fuse_layer = []
for j in range(num_branches):
if j > i:
fuse_layer.append(
nn.Sequential(
nn.Conv2d(
num_inchannels[j],
num_inchannels[i],
1, 1, 0, bias=False
),
nn.BatchNorm2d(num_inchannels[i]),
nn.Upsample(scale_factor=2**(j-i), mode='nearest')
)
)
elif j == i:
fuse_layer.append(None)
else:
conv3x3s = []
for k in range(i-j):
if k == i - j - 1:
num_outchannels_conv3x3 = num_inchannels[i] # 最后一次下采样匹配通道
conv3x3s.append(
nn.Sequential(
nn.Conv2d(
num_inchannels[j],
num_outchannels_conv3x3,
3, 2, 1, bias=False
),
nn.BatchNorm2d(num_outchannels_conv3x3)
)
)
else:
num_outchannels_conv3x3 = num_inchannels[j]
conv3x3s.append(
nn.Sequential(
nn.Conv2d(
num_inchannels[j],
num_outchannels_conv3x3, # 先不匹配通道
3, 2, 1, bias=False
),
nn.BatchNorm2d(num_outchannels_conv3x3),
nn.ReLU(True)
)
)
fuse_layer.append(nn.Sequential(*conv3x3s))
fuse_layers.append(nn.ModuleList(fuse_layer))
return nn.ModuleList(fuse_layers)
def get_num_inchannels(self):
return self.num_inchannels
def forward(self, x):
if self.num_branches == 1:
return [self.branches[0](x[0])]
for i in range(self.num_branches):
x[i] = self.branches[i](x[i])
x_fuse = []
for i in range(len(self.fuse_layers)):
y = 0
for j in range(self.num_branches):
if i == j:
y += x[j]
else:
y += self.fuse_layers[i][j](x[j])
x_fuse.append(self.relu(y))
return x_fuse
特征融合之后需要 _make_transition_layer 过度到下一个模块,因为可能需要匹配维度和分辨率等
def _make_transition_layer(
self, num_channels_pre_layer, num_channels_cur_layer):
num_branches_cur = len(num_channels_cur_layer)
num_branches_pre = len(num_channels_pre_layer)
transition_layers = []
for i in range(num_branches_cur):
if i < num_branches_pre:
if num_channels_cur_layer[i] != num_channels_pre_layer[i]:
transition_layers.append(nn.Sequential(
nn.Conv2d(num_channels_pre_layer[i],
num_channels_cur_layer[i],
3,
1,
1,
bias=False),
BatchNorm2d(
num_channels_cur_layer[i], momentum=BN_MOMENTUM),
nn.ReLU(inplace=True)))
else:
transition_layers.append(None) # 一般为None,同分支分辨率通道保持不变
else:
conv3x3s = []
for j in range(i + 1 - num_branches_pre):
inchannels = num_channels_pre_layer[-1]
outchannels = num_channels_cur_layer[i] \
if j == i - num_branches_pre else inchannels
conv3x3s.append(nn.Sequential(
nn.Conv2d(
inchannels, outchannels, 3, 2, 1, bias=False),
BatchNorm2d(outchannels, momentum=BN_MOMENTUM),
nn.ReLU(inplace=True)))
transition_layers.append(nn.Sequential(*conv3x3s))
return nn.ModuleList(transition_layers)
HRNet BackBone
HRNet BackBone 高度模块化,其大致示意如下:
→ stage n branches → fuse ⏟ HRModule ⏞ × num_modules → transition → stage N branches → fuse ⏟ HRModule ⏞ × num_modules → transition → \to \boxed{ \begin{aligned}&\qquad\qquad\qquad\color{blue}\text{stage n}\\ &\overbrace{\underbrace{\color{skyblue}{\text{branches}\to \text{fuse}}}_{\color{skyblue}\text{HRModule}}}^{\times \text{num\_modules}}\to \text{transition} \end{aligned}} \to \boxed{ \begin{aligned}&\qquad\qquad\qquad\color{blue}\text{stage N}\\ &\overbrace{\underbrace{\color{skyblue}{\text{branches}\to \text{fuse}}}_{\color{skyblue}\text{HRModule}}}^{\times \text{num\_modules}}\to \text{transition} \end{aligned}} \to →stage nHRModule branches→fuse ×num_modules→transition→stage NHRModule branches→fuse ×num_modules→transition→
HRNet结构作为BackBone可以用于多种任务,不同的任务可以用不同的检测头,如下图
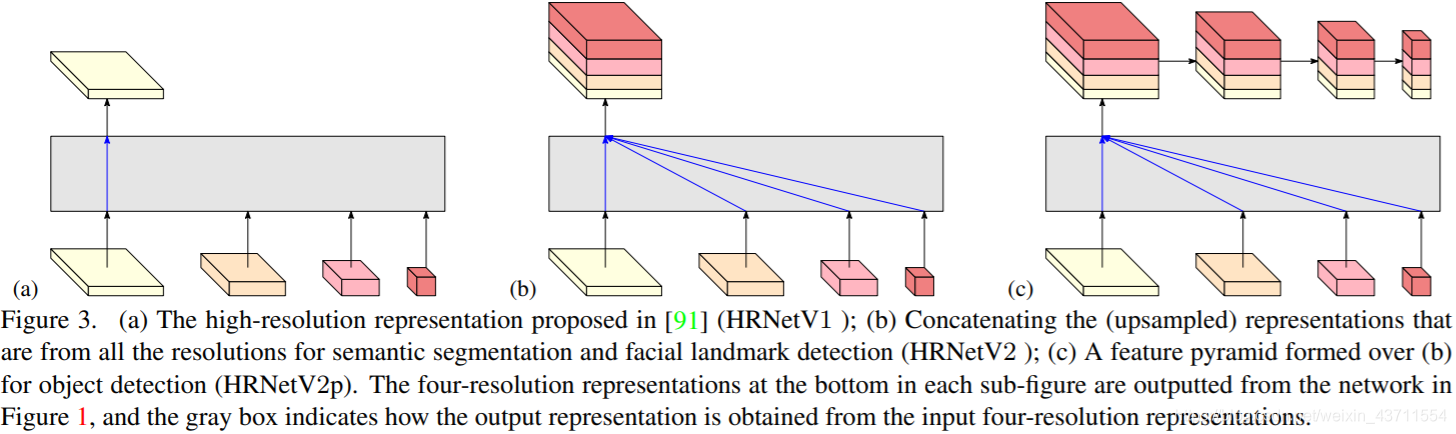
通过例子了解结构
from mmdet.models import HRNet
import torch
# 各阶段模块参数
extra = dict(
stage1=dict(
num_modules=1,
num_branches=1,
block='BOTTLENECK',
num_blocks=(4, ),
num_channels=(64, )),
stage2=dict(
num_modules=1,
num_branches=2,
block='BASIC',
num_blocks=(4, 4),
num_channels=(32, 64)),
stage3=dict(
num_modules=4, # 一个stage可以有多个模块构成,transition layer跟在最后一个模块之后,以便过渡到下一个stage
num_branches=3,
block='BASIC',
num_blocks=(4, 4, 4),
num_channels=(32, 64, 128)),
stage4=dict(
num_modules=3,
num_branches=4,
block='BASIC',
num_blocks=(4, 4, 4, 4),
num_channels=(32, 64, 128, 256)))
self = HRNet(extra, in_channels=1)
self.eval()
inputs = torch.rand(1, 1, 32, 32)
level_outputs = self.forward(inputs)
for level_out in level_outputs:
print(tuple(level_out.shape))
print(self)
对输出中完全相同的同级结构进行了简化表示
(1, 32, 8, 8)
(1, 64, 4, 4)
(1, 128, 2, 2)
(1, 256, 1, 1)
HRNet(
(conv1): Conv2d(1, 64, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(layer1): Sequential(
(0): Bottleneck(
(conv1): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(downsample): Sequential(
(0): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): Bottleneck(
(conv1): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
)
(2): Bottleneck()
(3): Bottleneck()
)
(transition1): ModuleList(
(0): Sequential(
(0): Conv2d(256, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace)
)
(1): Sequential(
(0): Sequential(
(0): Conv2d(256, 64, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace)
)
)
)
(stage2): Sequential(
(0): HRModule(
(branches): ModuleList(
(0): Sequential(
(0): BasicBlock(
(conv1): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
)
(1): BasicBlock()
(2): BasicBlock()
(3): BasicBlock()
)
(1): Sequential(
(0): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
)
(1): BasicBlock()
(2): BasicBlock()
(3): BasicBlock()
)
)
(fuse_layers): ModuleList(
(0): ModuleList(
(0): None
(1): Sequential(
(0): Conv2d(64, 32, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): Upsample(scale_factor=2.0, mode=nearest)
)
)
(1): ModuleList(
(0): Sequential(
(0): Sequential(
(0): Conv2d(32, 64, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): None
)
)
(relu): ReLU()
)
)
(transition2): ModuleList(
(0): None
(1): None
(2): Sequential(
(0): Sequential(
(0): Conv2d(64, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace)
)
)
)
(stage3): Sequential(
(0): HRModule(
(branches): ModuleList(
(0): Sequential(
(0): BasicBlock(
(conv1): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
)
(1): BasicBlock()
(2): BasicBlock()
(3): BasicBlock()
)
(1): Sequential(
(0): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
)
(1): BasicBlock()
(2): BasicBlock()
(3): BasicBlock()
)
(2): Sequential(
(0): BasicBlock(
(conv1): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
)
(1): BasicBlock()
(2): BasicBlock()
(3): BasicBlock()
)
)
(fuse_layers): ModuleList(
# --------------------------------i=0--------------------------------
(0): ModuleList(
(0): None ## ---j=0 同分支上无需融合
(1): Sequential( ## ---j=1 上采样×2通道×0.5
(0): Conv2d(64, 32, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): Upsample(scale_factor=2.0, mode=nearest)
)
(2): Sequential( ## ---j=2 上采样×4通道×0.25
(0): Conv2d(128, 32, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): Upsample(scale_factor=4.0, mode=nearest)
)
)
# --------------------------------i=1--------------------------------
(1): ModuleList(
(0): Sequential( ## ---j=0 下采样一次通道×2
(0): Sequential(
(0): Conv2d(32, 64, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): None ## ---j=1 同分支上无需融合
(2): Sequential( ## ---j=2 上采样×2通道×0.5
(0): Conv2d(128, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): Upsample(scale_factor=2.0, mode=nearest)
)
)
# --------------------------------i=2--------------------------------
(2): ModuleList(
(0): Sequential( ## ---j=0 下采样两次通道×4
(0): Sequential( #### 第1次下采样、通道数不变
(0): Conv2d(32, 32, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(1): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
)
(1): Sequential( #### 第2次下采样,匹配通道数,不使用Relu
(0): Conv2d(32, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): Sequential( ## ---j=1 下采样一次通道×2
(0): Sequential( #### 只有一次下采样,所以直接匹配通道数,不使用Relu
(0): Conv2d(64, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(2): None ## ---j=2 同分支上无需融合
)
)
(relu): ReLU()
)
(1): HRModule()
(2): HRModule()
(3): HRModule()
(transition3): ModuleList(
(0): None
(1): None
(2): None
(3): Sequential(
(0): Sequential(
(0): Conv2d(128, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace)
)
)
)
(stage4): Sequential(
(0): HRModule(
(branches): ModuleList(
(0): Sequential(
(0): BasicBlock(
(conv1): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
)
(1): BasicBlock()
(2): BasicBlock()
(3): BasicBlock()
)
(1): Sequential(
(0): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
)
(1): BasicBlock()
(2): BasicBlock()
(3): BasicBlock()
)
(2): Sequential(
(0): BasicBlock(
(conv1): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
)
(1): BasicBlock()
(2): BasicBlock()
(3): BasicBlock()
)
(3): Sequential(
(0): BasicBlock(
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
)
(1): BasicBlock()
(2): BasicBlock()
(3): BasicBlock()
)
)
(fuse_layers): ModuleList(
(0): ModuleList(
(0): None
(1): Sequential(
(0): Conv2d(64, 32, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): Upsample(scale_factor=2.0, mode=nearest)
)
(2): Sequential(
(0): Conv2d(128, 32, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): Upsample(scale_factor=4.0, mode=nearest)
)
(3): Sequential(
(0): Conv2d(256, 32, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): Upsample(scale_factor=8.0, mode=nearest)
)
)
(1): ModuleList(
(0): Sequential(
(0): Sequential(
(0): Conv2d(32, 64, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): None
(2): Sequential(
(0): Conv2d(128, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): Upsample(scale_factor=2.0, mode=nearest)
)
(3): Sequential(
(0): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): Upsample(scale_factor=4.0, mode=nearest)
)
)
(2): ModuleList(
(0): Sequential(
(0): Sequential(
(0): Conv2d(32, 32, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(1): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
)
(1): Sequential(
(0): Conv2d(32, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): Sequential(
(0): Sequential(
(0): Conv2d(64, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(2): None
(3): Sequential(
(0): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): Upsample(scale_factor=2.0, mode=nearest)
)
)
(3): ModuleList(
(0): Sequential(
(0): Sequential(
(0): Conv2d(32, 32, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(1): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
)
(1): Sequential(
(0): Conv2d(32, 32, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(1): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
)
(2): Sequential(
(0): Conv2d(32, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): Sequential(
(0): Sequential(
(0): Conv2d(64, 64, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
)
(1): Sequential(
(0): Conv2d(64, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(2): Sequential(
(0): Sequential(
(0): Conv2d(128, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(3): None
)
)
(relu): ReLU()
)
(1): HRModule()
(2): HRModule()
)
)
取出其中的 stage3 fuse_layers 如下:
(fuse_layers): ModuleList(
# --------------------------------i=0--------------------------------
(0): ModuleList(
(0): None ## ---j=0 同分支上无需融合
(1): Sequential( ## ---j=1 上采样×2通道×0.5
(0): Conv2d(64, 32, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): Upsample(scale_factor=2.0, mode=nearest)
)
(2): Sequential( ## ---j=2 上采样×4通道×0.25
(0): Conv2d(128, 32, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): Upsample(scale_factor=4.0, mode=nearest)
)
)
# --------------------------------i=1--------------------------------
(1): ModuleList(
(0): Sequential( ## ---j=0 下采样一次通道×2
(0): Sequential(
(0): Conv2d(32, 64, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): None ## ---j=1 同分支上无需融合
(2): Sequential( ## ---j=2 上采样×2通道×0.5
(0): Conv2d(128, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): Upsample(scale_factor=2.0, mode=nearest)
)
)
# --------------------------------i=2--------------------------------
(2): ModuleList(
(0): Sequential( ## ---j=0 下采样两次通道×4
(0): Sequential( #### 第1次下采样、通道数不变
(0): Conv2d(32, 32, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(1): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
)
(1): Sequential( #### 第2次下采样,匹配通道数,不使用Relu
(0): Conv2d(32, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): Sequential( ## ---j=1 下采样一次通道×2
(0): Sequential( #### 只有一次下采样,所以直接匹配通道数,不使用Relu
(0): Conv2d(64, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(2): None ## ---j=2 同分支上无需融合
)
)
(relu): ReLU()
)
参考文献
【1】HRNet网络结构及TensorFlow实现(图)
【2】HRNet–从代码来看论文
【3】HRNet V2
【4】HRNet阅读笔记及代码理解
【5】HRNet网络结构
【6】High-Resolution Representation Learning for Object Detection


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









