






概述
问题:locating-then-editing方法中,同时优化更新错误与知识保留错误(e0,e1,努力平衡),但往往带来对更新的过拟合,
导致LLM中隐藏表示的分布偏移(参数修改导致中间结果分布的变化),在多轮顺序编辑后,甚至会带来模型的遗忘与崩溃
方法:将参数扰动投影到保留知识矩阵 K0 的零空间(避免参数扰动带来的干扰,同时可以从原本的优化目标中删去e0)
评价标准:从知识更新与保留、生成能力、隐藏表示分析、多次编辑后的稳定性、通用性(不同模型)等角度设计实现了详细全面的实验,使用了此方法后的效果显著高于基线
零空间投影
修改模型参数 W为 W+Δ,使得:
-
(W+Δ)K1≈V1(满足知识更新)
-
(W+Δ)K0=WK0=V0(同时保留旧知识)
K0,K1分别对应保留知识和待更新知识的键矩阵(每列对应一个知识的输入表示)
约束条件:ΔK0=0(确保扰动不会影响保留知识)
实现:将参数扰动投影到K0的(左)零空间
(零空间就是所有使得 Ax=0成立的 x向量的集合)
构造投影矩阵
奇异值分解(SVD):
奇异值分解(SVD,Singular Value Decomposition)是线性代数里非常重要的一种矩阵分解方法。简单来说,它是把一个任意的矩阵,拆成三个有良好部分的乘积,而且这三个部分有很好的数学性质:

例如:
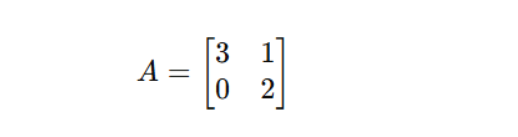
可以分解为:

这个 A矩阵其实就是:
-
不需要旋转,
-
然后分别在第一个方向上拉伸3倍,在第二个方向上拉伸2倍,
-
就得到了最终的 A
(具体的分解方法对本文不是重点,这里只做简单介绍)
具体计算步骤:
-
计算 ATA(转置后乘自己)和 AAT。
这两个矩阵都是对称矩阵,所以它们可以被对角化,能找到特征值和特征向量
-
ATA 的特征值都是非负的,把这些特征值开平方(取正数部分),就得到 Σ矩阵上的奇异值(按大小排序,通常是从大到小)
-
V 是 ATA的特征向量组成的正交矩阵
也就是说,解 ATAv=λv,得到的单位特征向量 v 就组成了 V矩阵
-
U 是用公式算的:
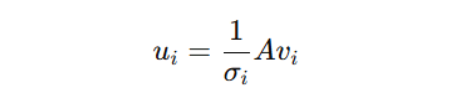
也就是:
用 A乘 V 的每一个特征向量 vi,再除以对应的奇异值 σi得到的向量就是 U 的列向量
按此方法对K0进行奇异值分解即可:

分离零空间基构造投影矩阵:
假设 K0 的秩为 r,将 U分为两部分:

P即为K0所需的左零空间投影矩阵
约束优化转化
使用投影矩阵P,改变优化目标:
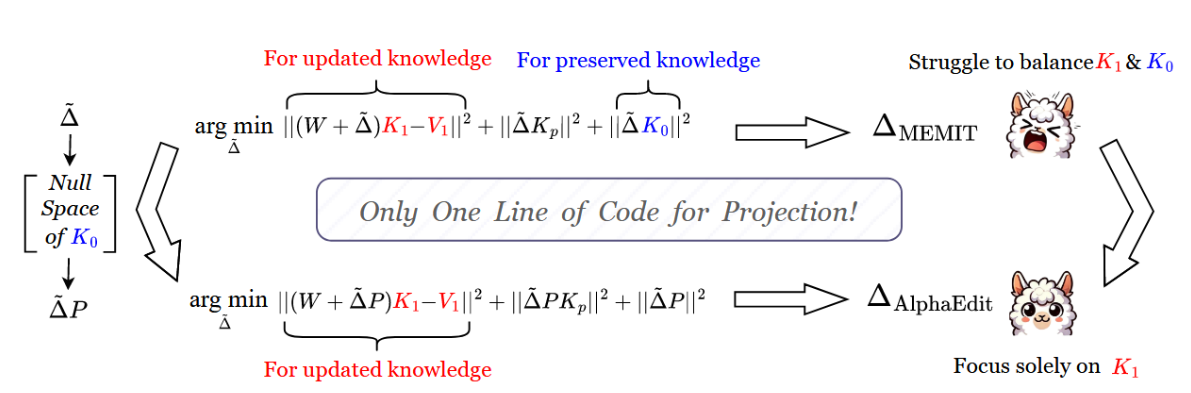
求解Δ

首先定义:R=V1-WK1并代入,求目标J关于Δ~的偏导,得到式(32);根据正交投影矩阵P的性质(对称性)可以进一步化简得到(33);等式两侧同乘矩阵的逆,得到Δ的表达式
应用
在实际使用中,于预处理阶段,根据保留知识矩阵K0计算投影矩阵P,随后将代码中的Δ修改为Δ乘上P即可实现零空间投影;此论文设计了全面详实的实验,从多个角度证明了此方法能显著提升模型的表现,解决参数编辑带来的模型遗忘与崩溃问题。

















 3831
3831

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









