







1、前景引入
最近在看机器学习的西瓜书,对书中公式2.27甚是不解…
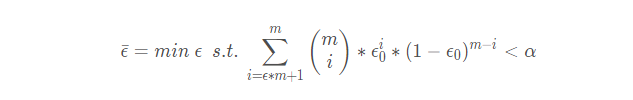
在网上搜了很多资料,看了很多大佬的博客,问了同学和老师。但可能由于我数学比较差吧,对于涉及很多数学符号的逻辑推理过程,总有那么一个环节我会因为对其中一个细节的不解而感到疑惑…从而最终基本上还是有种懵里懵懂的感觉。
于是我有了个不成熟的想法…我在想能不能通过一个生活中的例子来解释一通…
2、符号解析
当然,纵使是使用生活中的例子来类比公式的潜在含义,对于这个公式涉及的基本符号的含义我们还是需要提前了解一下的。
ϵ \epsilon ϵ:泛化错误率。泛化错误率为 ϵ \epsilon ϵ的学习器在一个样本上犯错的概率为 ϵ \epsilon ϵ。
ϵ ^ \hat\epsilon ϵ^:测试错误率。测试错误率为 ϵ ^ \hat\epsilon ϵ^意味着m个测试样本中恰有 ϵ ^ \hat\epsilon ϵ^×m个被误分类。
ϵ 0 \epsilon_0 ϵ0:假设的泛化错误率。
ϵ ˉ \bar\epsilon ϵˉ:临界错误率。
3、类比推理
上面对于符号的解释可能比较抽象,因此请允许我用如下不太严谨的生活例子再来解释一通:
我们假设小明每次投篮的命中率为h=70%,那么小明每次投篮的丢失率即为 ϵ \epsilon ϵ = ϵ 0 \epsilon_0 ϵ0 = 1-70%=30%。可我们的假设究竟对不对呢,小明每次投篮的丢失率真的是30%吗?我们不得而知。
为了验证我们的假设,我们打算采用重复实验的方法来检测。每次实验中我们让小明连投10次篮,然后记录小明在10次投篮中的丢失次数m’。从而得到小明在每次测试中的投篮丢失率为 ϵ ^ \hat\epsilon ϵ^=m’/10。
在第一波实验中,小明非常给力,10个投篮中仅丢了1个球,丢失率为1/10=10%
在第二波实验中,小明非常拉跨,10个投篮中竟丢了5个球,丢失率为高达5/10=50%
在第三波实验中,小明发挥正常,10个投篮中丢了3个球,丢失率为3/10=30%
在第四波实验中,小明发挥正常,10个投篮中丢了3个球,丢失率为3/10=30%
在第五波实验中,小明较为超神,10个投篮中丢了2个球,丢失率为2/10=20%
在第六波实验中,小明较为打铁,10个投篮中丢了4个球,丢失率为4/10=40%
…
在每次实验中,小明的丢失率看上去是不稳定的,有时为10%,有时为20%,有时为30%, 有时为40%,甚至有时还为50%…小明的投篮丢失率真的就无法预测吗?
不过好在我们学过二项分布,如果我们的假设是成立的,则10次投篮中丢失次数为m’的概率为:
P { x = m ′ } P\lbrace\ x = m' \rbrace P{ x=m′} = C 10 m ′ C_{10}^{m'} C10m′ ϵ 0 m ′ \epsilon_0^{m'} ϵ0m′ ( 1 − ϵ 0 ) 10 − m ′ (1-\epsilon_0)^{10-m'} (1−ϵ0)10−m′
从而我们依次计算出m’=0,1,2,3…,9,10时的概率,作出如下的图像
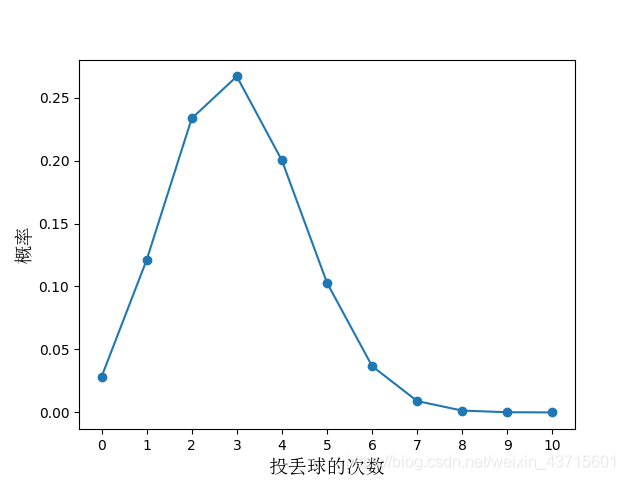
从图中我们可以看出,10次投球中,投丢3个球的概率最大,投丢10个球的概率最小。且投丢6个球及以上的概率很少,加起来都可能少于10%。
在统计学中,有一个概念叫做小概率事件。若一个事件是小概率事件,则可以认为在一次试验中该事件几乎不会发生。小概率事件中的小概率一般用α表示,α一般取0.1或0.05。
若取α=0.1。则在这个图中,投丢6个球及以上的概率仅有10%左右,说明"投丢6个球及以上"是一个小概率事件,可以认定在某次试验中基本上是不可能发生的。
换言之,可以这么理解:小明说自己投篮命中率为70%,但是他在好几次实验中的10次投篮都投丢了整整6个球,这个时候你还愿意相信他吗?一般来说,我们都会认为小明只是在吹牛皮…认为他的真实命中率并不是70%。
通过上面的概率分布图,我们可以进一步说明:如果"小明的投篮丢失率为30%"这个假设是成立的,那么"10次投篮投丢了6个球及以上"仅是一个小概率事件,在一次试验中认定了基本上不会发生的。但是这个小概率事件在该次试验中却发生了,说明我们的原假设应该是不成立的。
总的来说,可以这么概括,你说自己投篮命中率有70%,那我让你投10次篮,你丢0、1、2、3、4、5次我都能接受,暂且能够相信你,但你竟然能投丢6、7、8、9、10次,你这不就是在扯犊子吗…
推理到这里,我们貌似终于找到了证明原假设成立的方法。也就是去求一个错误率临界值
ϵ
ˉ
\bar\epsilon
ϵˉ,将其余测试错误率
ϵ
^
\hat\epsilon
ϵ^与进行比较:
1)如果
ϵ
^
\hat\epsilon
ϵ^ <
ϵ
ˉ
\bar\epsilon
ϵˉ,那么我们就以大概率认定原假设是成立的。
2)如果
ϵ
^
\hat\epsilon
ϵ^ >=
ϵ
ˉ
\bar\epsilon
ϵˉ,那么我们就以大概率认定原假设是不成立的。
在上文的例子中,临界错误率值 ϵ ˉ \bar\epsilon ϵˉ即为6/10=0.6。若测试中小明投10次篮丢的次数小于6次,我们都是可以接受的,从而说明原假设大概率成立;若测试中小明投10次篮丢的次数大于等于6次,我们是不可以接受的,从而说明原假设大概率不成立。
那么到现在我们唯一的问题就是,如何去求得这个临界错误率 ϵ ˉ \bar\epsilon ϵˉ?
其实这个问题很简单,想想我刚才是怎么得到临界错误值=6这个关键数字的?实际上我是从我们的概率峰值错误次数=3出发,不断地"向后看",确保临界错误次数及以上的概率总和仍小于我们所规定的小概率事件发生的概率α。
那为什么要从3往后看而不是从10往前看呢?因为我们希望临界错误率能够成为一个较合理的衡量标准啊!比如临界错误率为0.9,那么根据上面的结论我们可以说10个球里投丢8个也是正常的。因为假设投篮丢失率为0.3,10个球里投丢9个是个小概率事件,在此次测试中该小概率事件并没有发生,所以我的原假设是成立的。
上述推理过程看似没有毛病,但你觉得这合理吗?
因此,至少根据我个人的理解,我是认为临界错误率应该是越小越好,越小越能以越大的概率说明原假设的成立的可能性。
从而最终才可得到西瓜书中计算临界错误率公式2.27:
ϵ ˉ = m i n \bar\epsilon=min ϵˉ=min ϵ \epsilon ϵ s . t . s.t. s.t. ∑ i = ϵ × m + 1 m \sum_{i=\epsilon×m+1}^m ∑i=ϵ×m+1m ( m i ) \begin{pmatrix}m\\i\end{pmatrix} (mi) ϵ 0 i ( 1 − ϵ 0 ) m − i < α \epsilon_0^i(1-\epsilon_0)^{m-i}<\alpha ϵ0i(1−ϵ0)m−i<α
这里面s.t.是"subject to"的简写,使左边的式子在右边的式子满足时成立。
在该公式中的含义是:右边的不等式成立时泛化错误率 ϵ \epsilon ϵ可取得的最小值。
那么到现在最后只有一个问题了,即为什么书中的假设是
ϵ
<
=
ϵ
0
\epsilon<=\epsilon_0
ϵ<=ϵ0,但仍可以用公式2.27来计算临界错误率
ϵ
ˉ
\bar\epsilon
ϵˉ?
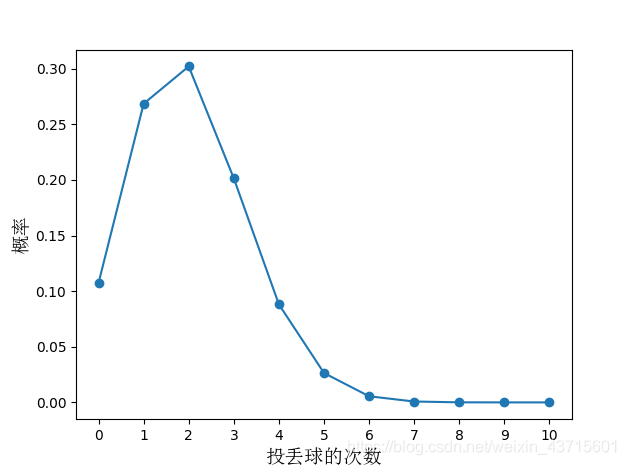
我们可以作两个图像,第一个图像是泛化错误率为0.2的图像:
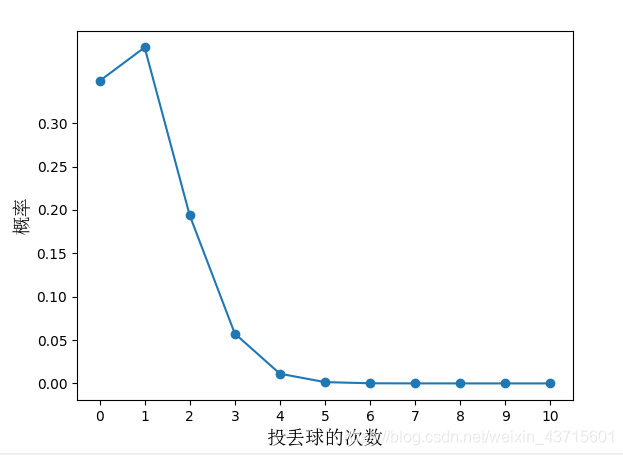
第二个图像是泛化错误率为0.1的图像:
通过这两个图像我们可以惊讶的发现:在
ϵ
=
ϵ
0
=
0.3
\epsilon=\epsilon_0 = 0.3
ϵ=ϵ0=0.3时,通过计算发现的{
ϵ
^
>
ϵ
ˉ
\hat\epsilon>\bar\epsilon
ϵ^>ϵˉ}是一个小概率事件,在
ϵ
<
0.3
\epsilon<0.3
ϵ<0.3时,发觉{
ϵ
^
>
ϵ
ˉ
\hat\epsilon>\bar\epsilon
ϵ^>ϵˉ}就更是一个小概率事件了。
比如上文我们说到了假设投篮丢失率为0.3的时候,10次里投丢6次及以上仅是一个小概率事件(投丢6次及以上的概率<α=0.1),是基本上不会发生的。
而在这两个图中,我们可以发现10次里投丢6次及以上也是一个小概率事件,而且几率更小,就基本上更不会发生了。

















 374
374

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









