






1. 数据集视频准备
本次训练以实验为目的,了解该框架的训练步骤,选取了1段30秒以上的关于打电话的视频。
2. 视频抽帧
目的:
(1)1秒抽1帧图片,目的是用来标注,ava数据集就是1秒1帧
(2)1秒抽30帧图片,目的是用来训练,据说因为slowfast在slow通道里1秒会采集到15帧,在fast通道里1秒会采集到2帧。
以下是运行代码:
video2img.py
import os
import shutil
from tqdm import tqdm
start = 0
seconds = 30
video_path = './ava/videos'
labelframes_path = './ava/labelframes'
rawframes_path = './ava/rawframes'
cut_videos_sh_path = './cut_videos.sh'
if os.path.exists(labelframes_path):
#递归删除文件夹下的所有子文件夹和子文件
shutil.rmtree(labelframes_path)
if os.path.exists(rawframes_path):
shutil.rmtree(rawframes_path)
fps = 30
raw_frames = seconds * fps
with open(cut_videos_sh_path, 'r') as f:
sh = f.read()
sh = sh.replace(sh[sh.find(' ffmpeg'):],
f' ffmpeg -ss {start} -t {seconds} -i "${{video}}" -r 30 -strict experimental "${{out_name}}"\n fi\ndone\n')
with open(cut_videos_sh_path, 'w') as f:
f.write(sh)
# 902打到1798
os.system('bash cut_videos.sh') #调用 bash cut_videos.sh该命令
os.system('bash extract_rgb_frames_ffmpeg.sh')
os.makedirs(labelframes_path, exist_ok=True)
video_ids = [video_id[:-4] for video_id in os.listdir(video_path)]
for video_id in tqdm(video_ids):
for img_id in range(2 * fps + 1, (seconds - 2) * 30, fps):
shutil.copyfile(os.path.join(rawframes_path, video_id, '08093_' + format(img_id, '05d') + '.jpg'),
os.path.join(labelframes_path, video_id + '_' + format(start + img_id // 30, '05d') + '.jpg'))
#shutil.rmtree(): 递归删除文件夹下的所有子文件夹和子文件
#os.path.join(): 连接两个或更多的路径名组件
#shutil.copyfile(file1,file2): 将文件file1复制到file2extract_rgb_frames_ffmpeg.sh (抽帧)
IN_DATA_DIR="./ava/videos_cut"
OUT_DATA_DIR="./ava/rawframes"
if [[ ! -d "${OUT_DATA_DIR}" ]]; then
echo "${OUT_DATA_DIR} doesn't exist. Creating it.";
mkdir -p ${OUT_DATA_DIR}
fi
for video in $(ls -A1 -U ${IN_DATA_DIR}/*)
do
video_name=${video##*/}
if [[ $video_name = *".webm" ]]; then
video_name=${video_name::-5}
else
video_name=${video_name::-4}
fi
out_video_dir=${OUT_DATA_DIR}/${video_name}
mkdir -p "${out_video_dir}"
out_name="${out_video_dir}/${out_video_dir}_%05d.jpg"
ffmpeg -i "${video}" -r 30 -q:v 1 "${out_name}"
donecut_videos.sh(裁剪视频)
IN_DATA_DIR="./ava/videos"
OUT_DATA_DIR="./ava/videos_cut"
if [[ ! -d "${OUT_DATA_DIR}" ]]; then
echo "${OUT_DATA_DIR} doesn't exist. Creating it.";
mkdir -p ${OUT_DATA_DIR}
fi
for video in $(ls -A1 -U ${IN_DATA_DIR}/*)
do
out_name="${OUT_DATA_DIR}/${video##*/}"
if [ ! -f "${out_name}" ]; then
ffmpeg -ss 0 -t 30 -i "${video}" -r 30 -strict experimental "${out_name}"
fi
done注意:.sh脚本是在linux中运行的,在windows下打开后,需转成unix格式,不然在linux下运行会报错。
以上3个脚本放在同一目录下,并在目录下创建ava/videos文件夹,将准备的1个视频放在videos文件夹下,由于视频的时长都在30秒以上,所以修改video2img.py中的seconds为30(这里要注意,seconds为视频结束时间,所以准备的视频文件时长都必须超过30秒)。
然后执行:python video2img.py
执行完成后,会在ava文件夹下生成三个文件夹,labelframes里存放的是需要标注的图片(1秒抽1帧的图片),rawframes里放的是每个视频文件每秒30帧的图片(用于slowfast训练),videos_cut文件夹里放的时裁剪后的视频文件(视频时长是1-30秒),videos里放的就是原视频文件。实际在以后的训练过程中,videos_cut和videos里的文件就已经没啥用处了,直接删掉就行。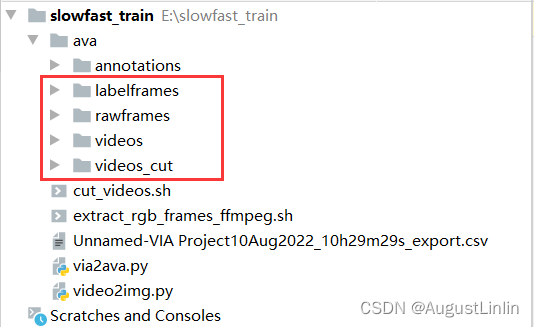
3. 图片标注说明
实际上图片标注分为两种方式,1是自动标注,2是手动标注。
自动标注:使用faster rcnn自动把图片中的人框出来,然后我们再标注人的行为,如果待标注的图片数据量比较大,这种方式无疑是很好的,手动画框框是很累人的。
手动标注:也就是我们手动画框框,然后再标注人的行为,这种方式比较适合图片数据量比较小的情况。
本次训练的数据集较少,采用的是手动标注。
4. 图片标注
slowfast需要ava格式的数据集,先使用via工具标注图片中的行为,然后再使用脚本将导出的csv文件转为slowfast需要的ava格式即可。我使用的via版本为via-3.0.11。
下载完成后,双击via_image_annotator.html打开。
(1)点击加号图标,将labelframes文件夹下全部图片导入

(2)点击如下图所示图标,创建一个attribute
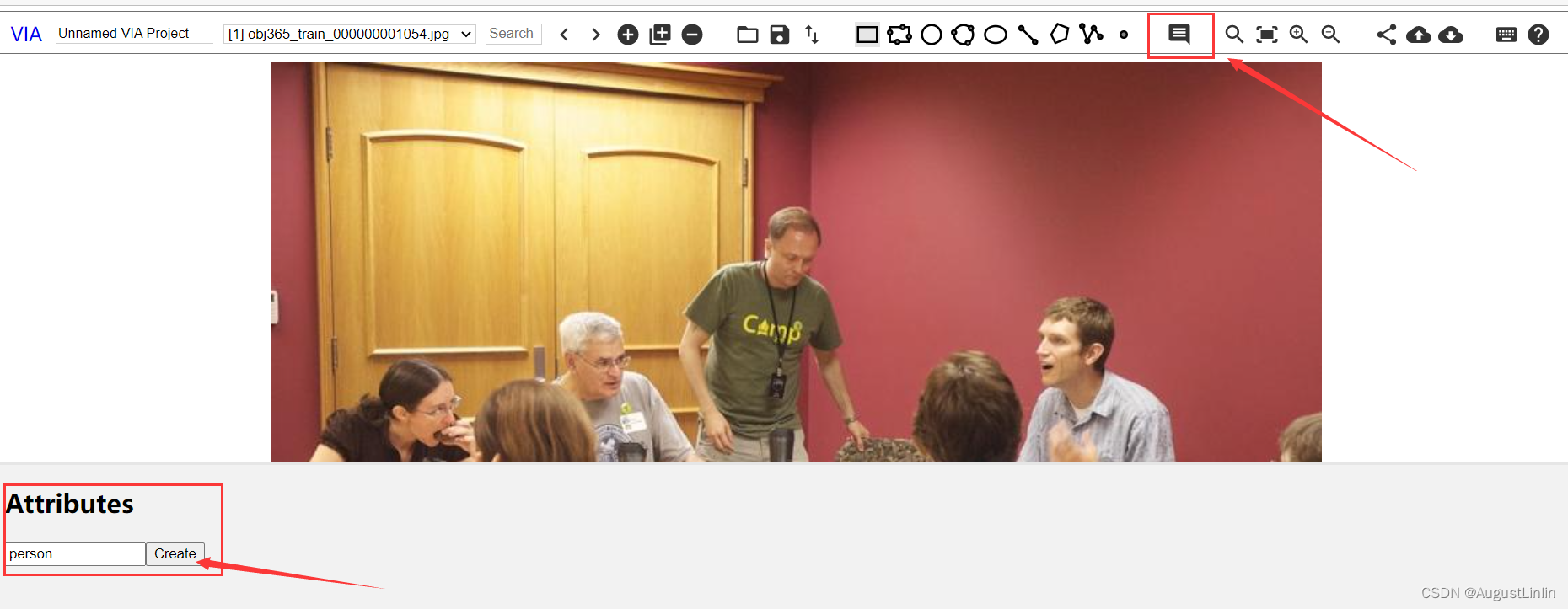
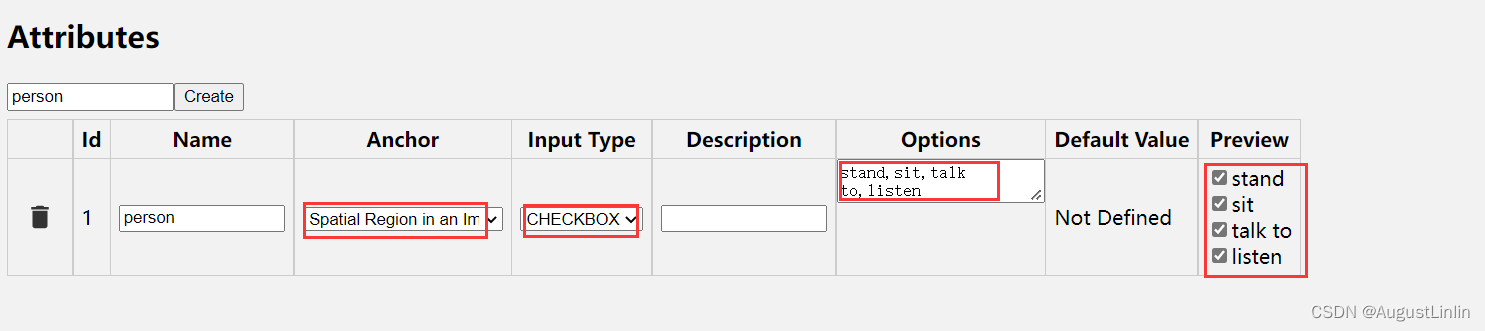
(3)anchor选择第二项,input type选择checkbox,在options中定义人的四个行为:stand,sit,talk to,listen,用英文状态下的逗号分割开,然后preview中勾选四个行为。
(4)开始标注图片,框选图片中的人,然后点击矩形框,勾选你认为人出现的行为,如下图所示:

(5)全部标注完成后,点击如下图所示图标:
 保持默认选项,点击“Export”导出csv文件,注意,该csv文件最好不要用Excel打开进行编辑!!!
保持默认选项,点击“Export”导出csv文件,注意,该csv文件最好不要用Excel打开进行编辑!!!
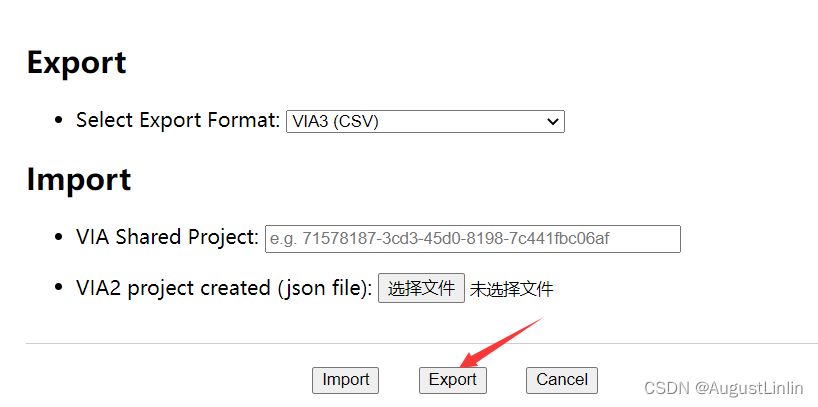
此时会得到一个csv文件
![]()
5. via数据集转为slowfast格式
slowfast数据集要求ava格式,同时需要提供pkl文件,使用以下python脚本可一键生成全部所需配置文件!
via2ava.py
"""
Theme:ava format data transformer
author:Hongbo Jiang
time:2022/3/14/1:51:51
description:
这是一个数据格式转换器,根据mmaction2的ava数据格式转换规则将来自网站:
https://www.robots.ox.ac.uk/~vgg/software/via/app/via_video_annotator.html
的、标注好的、视频理解类型的csv文件转换为mmaction2指定的数据格式。
转换规则:
# AVA Annotation Explained
In this section, we explain the annotation format of AVA in details:
```
mmaction2
├── data
│ ├── ava
│ │ ├── annotations
│ │ | ├── ava_dense_proposals_train.FAIR.recall_93.9.pkl
│ │ | ├── ava_dense_proposals_val.FAIR.recall_93.9.pkl
│ │ | ├── ava_dense_proposals_test.FAIR.recall_93.9.pkl
│ │ | ├── ava_train_v2.1.csv
│ │ | ├── ava_val_v2.1.csv
│ │ | ├── ava_train_excluded_timestamps_v2.1.csv
│ │ | ├── ava_val_excluded_timestamps_v2.1.csv
│ │ | ├── ava_action_list_v2.1.pbtxt
```
## The proposals generated by human detectors
In the annotation folder, `ava_dense_proposals_[train/val/test].FAIR.recall_93.9.pkl` are human proposals generated by a human detector. They are used in training, validation and testing respectively. Take `ava_dense_proposals_train.FAIR.recall_93.9.pkl` as an example. It is a dictionary of size 203626. The key consists of the `videoID` and the `timestamp`. For example, the key `-5KQ66BBWC4,0902` means the values are the detection results for the frame at the $$902_{nd}$$ second in the video `-5KQ66BBWC4`. The values in the dictionary are numpy arrays with shape $$N \times 5$$ , $$N$$ is the number of detected human bounding boxes in the corresponding frame. The format of bounding box is $$[x_1, y_1, x_2, y_2, score], 0 \le x_1, y_1, x_2, w_2, score \le 1$$. $$(x_1, y_1)$$ indicates the top-left corner of the bounding box, $$(x_2, y_2)$$ indicates the bottom-right corner of the bounding box; $$(0, 0)$$ indicates the top-left corner of the image, while $$(1, 1)$$ indicates the bottom-right corner of the image.
## The ground-truth labels for spatio-temporal action detection
In the annotation folder, `ava_[train/val]_v[2.1/2.2].csv` are ground-truth labels for spatio-temporal action detection, which are used during training & validation. Take `ava_train_v2.1.csv` as an example, it is a csv file with 837318 lines, each line is the annotation for a human instance in one frame. For example, the first line in `ava_train_v2.1.csv` is `'-5KQ66BBWC4,0902,0.077,0.151,0.283,0.811,80,1'`: the first two items `-5KQ66BBWC4` and `0902` indicate that it corresponds to the $$902_{nd}$$ second in the video `-5KQ66BBWC4`. The next four items ($$[0.077(x_1), 0.151(y_1), 0.283(x_2), 0.811(y_2)]$$) indicates the location of the bounding box, the bbox format is the same as human proposals. The next item `80` is the action label. The last item `1` is the ID of this bounding box.
## Excluded timestamps
`ava_[train/val]_excludes_timestamps_v[2.1/2.2].csv` contains excluded timestamps which are not used during training or validation. The format is `video_id, second_idx` .
## Label map
`ava_action_list_v[2.1/2.2]_for_activitynet_[2018/2019].pbtxt` contains the label map of the AVA dataset, which maps the action name to the label index.
"""
import csv
import os
from distutils.log import info
import pickle
from matplotlib.pyplot import contour, show
import numpy as np
import cv2
from sklearn.utils import shuffle
def transformer(origin_csv_path, frame_image_dir,
train_output_pkl_path, train_output_csv_path,
valid_output_pkl_path, valid_output_csv_path,
exclude_train_output_csv_path, exclude_valid_output_csv_path,
out_action_list, out_labelmap_path, dataset_percent=0.9):
"""
输入:
origin_csv_path:从网站导出的csv文件路径。
frame_image_dir:以"视频名_第n秒.jpg"格式命名的图片,这些图片是通过逐秒读取的。
output_pkl_path:输出pkl文件路径
output_csv_path:输出csv文件路径
out_labelmap_path:输出labelmap.txt文件路径
dataset_percent:训练集和测试集分割
输出:无
"""
# -----------------------------------------------------------------------------------------------
get_label_map(origin_csv_path, out_action_list, out_labelmap_path)
# -----------------------------------------------------------------------------------------------
information_array = [[], [], []]
# 读取输入csv文件的位置信息段落
with open(origin_csv_path, 'r') as csvfile:
count = 0
content = csv.reader(csvfile)
for line in content:
# print(line)
if count >= 10:
frame_image_name = eval(line[1])[0] # str
# print(line[-2])
location_info = eval(line[4])[1:] # list
action_list = list(eval(line[5]).values())[0].split(',')
action_list = [int(x) for x in action_list] # list
information_array[0].append(frame_image_name)
information_array[1].append(location_info)
information_array[2].append(action_list)
count += 1
# 将:对应帧图片名字、物体位置信息、动作种类信息汇总为一个信息数组
information_array = np.array(information_array, dtype=object).transpose()
# information_array = np.array(information_array)
# -----------------------------------------------------------------------------------------------
num_train = int(dataset_percent * len(information_array))
train_info_array = information_array[:num_train]
valid_info_array = information_array[num_train:]
get_pkl_csv(train_info_array, train_output_pkl_path, train_output_csv_path, exclude_train_output_csv_path, frame_image_dir)
get_pkl_csv(valid_info_array, valid_output_pkl_path, valid_output_csv_path, exclude_valid_output_csv_path, frame_image_dir)
def get_label_map(origin_csv_path, out_action_list, out_labelmap_path):
classes_list = 0
classes_content = ""
labelmap_strings = ""
# 提取出csv中的第9行的行为下标
with open(origin_csv_path, 'r') as csvfile:
count = 0
content = csv.reader(csvfile)
for line in content:
if count == 8:
classes_list = line
break
count += 1
# 截取种类字典段落
st = 0
ed = 0
for i in range(len(classes_list)):
if classes_list[i].startswith('options'):
st = i
if classes_list[i].startswith('default_option_id'):
ed = i
for i in range(st, ed):
if i == st:
classes_content = classes_content + classes_list[i][len('options:'):] + ','
else:
classes_content = classes_content + classes_list[i] + ','
classes_dict = eval(classes_content)[0]
# 写入labelmap.txt文件
with open(out_action_list, 'w') as f: # 写入action_list文件
for v, k in classes_dict.items():
labelmap_strings = labelmap_strings + "label {{\n name: \"{}\"\n label_id: {}\n label_type: PERSON_MOVEMENT\n}}\n".format(k, int(v)+1)
f.write(labelmap_strings)
labelmap_strings = ""
with open(out_labelmap_path, 'w') as f: # 写入label_map文件
for v, k in classes_dict.items():
labelmap_strings = labelmap_strings + "{}: {}\n".format(int(v)+1, k)
f.write(labelmap_strings)
def get_pkl_csv(information_array, output_pkl_path, output_csv_path, exclude_output_csv_path, frame_image_dir):
# 在遍历之前需要对我们的字典进行初始化
pkl_data = dict() # 存储pkl键值对信的字典(其值为普通list)
csv_data = [] # 存储导出csv文件的2d数组
read_data = {} # 存储pkl键值对的字典(方便字典的值化为numpy数组)
for i in range(len(information_array)):
img_name = information_array[i][0]
# -------------------------------------------------------------------------------------------
video_name, frame_name = '_'.join(img_name.split('_')[:-1]), format(int(img_name.split('_')[-1][:-4]), '04d') # 我的格式是"视频名称_帧名称",格式不同可自行更改
# -------------------------------------------------------------------------------------------
pkl_key = video_name + ',' + frame_name
pkl_data[pkl_key] = []
# 遍历所有的图片进行信息读取并写入pkl数据
for i in range(len(information_array)):
img_name = information_array[i][0]
# -------------------------------------------------------------------------------------------
video_name, frame_name = '_'.join(img_name.split('_')[:-1]), str(int(img_name.split('_')[-1][:-4])) # 我的格式是"视频名称_帧名称",格式不同可自行更改
# -------------------------------------------------------------------------------------------
imgpath = frame_image_dir + '/' + img_name
location_list = information_array[i][1]
action_info = information_array[i][2]
image_array = cv2.imread(imgpath)
h, w = image_array.shape[:2]
# 进行归一化
location_list[0] /= w
location_list[1] /= h
location_list[2] /= w
location_list[3] /= h
location_list[2] = location_list[2]+location_list[0]
location_list[3] = location_list[3]+location_list[1]
# 置信度置为1
# 组装pkl数据
for kind_idx in action_info:
csv_info = [video_name, frame_name, *location_list, kind_idx+1, 1]
csv_data.append(csv_info)
location_list = location_list + [1]
pkl_key = video_name + ',' + format(int(frame_name), '04d')
pkl_value = location_list
pkl_data[pkl_key].append(pkl_value)
for k, v in pkl_data.items():
read_data[k] = np.array(v)
with open(output_pkl_path, 'wb') as f: # 写入pkl文件
pickle.dump(read_data, f)
with open(output_csv_path, 'w', newline='') as f: # 写入csv文件, 设定参数newline=''可以不换行。
f_csv = csv.writer(f)
f_csv.writerows(csv_data)
with open(exclude_output_csv_path, 'w', newline='') as f: # 写入csv文件, 设定参数newline=''可以不换行。
f_csv = csv.writer(f)
f_csv.writerows([])
def showpkl(pkl_path):
with open(pkl_path, 'rb') as f:
content = pickle.load(f)
return content
def showcsv(csv_path):
output = []
with open(csv_path, 'r') as f:
content = csv.reader(f)
for line in content:
output.append(line)
return output
def showlabelmap(labelmap_path):
classes_dict = dict()
with open(labelmap_path, 'r') as f:
content = (f.read().split('\n'))[:-1]
for item in content:
mid_idx = -1
for i in range(len(item)):
if item[i] == ":":
mid_idx = i
classes_dict[item[:mid_idx]] = item[mid_idx + 1:]
return classes_dict
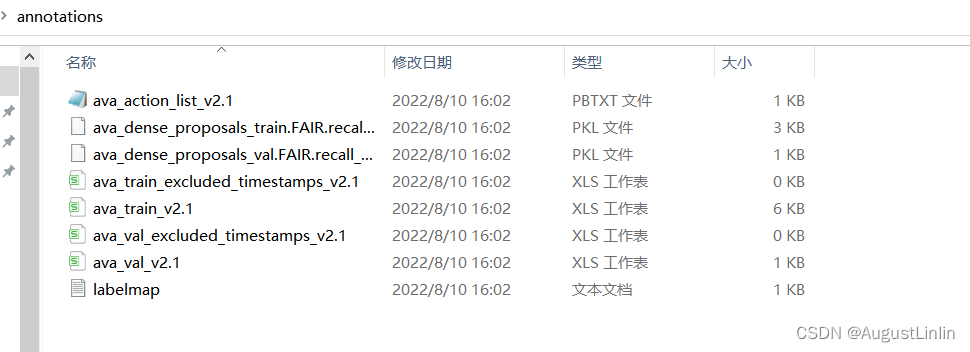
os.makedirs('./ava/annotations', exist_ok=True)
transformer("./Unnamed-VIA Project13Jul2022_16h01m30s_export.csv", './ava/labelframes',
'./ava/annotations/ava_dense_proposals_train.FAIR.recall_93.9.pkl', './ava/annotations/ava_train_v2.1.csv',
'./ava/annotations/ava_dense_proposals_val.FAIR.recall_93.9.pkl', './ava/annotations/ava_val_v2.1.csv',
'./ava/annotations/ava_train_excluded_timestamps_v2.1.csv', './ava/annotations/ava_val_excluded_timestamps_v2.1.csv',
'./ava/annotations/ava_action_list_v2.1.pbtxt', './ava/annotations/labelmap.txt', 0.9)
print(showpkl('./ava/annotations/ava_dense_proposals_train.FAIR.recall_93.9.pkl'))
print(showcsv('././ava/annotations/ava_train_v2.1.csv'))
print(showlabelmap('././ava/annotations/labelmap.txt'))将via2ava.py和你的csv文件放在与ava同级目录下,如下图所示:
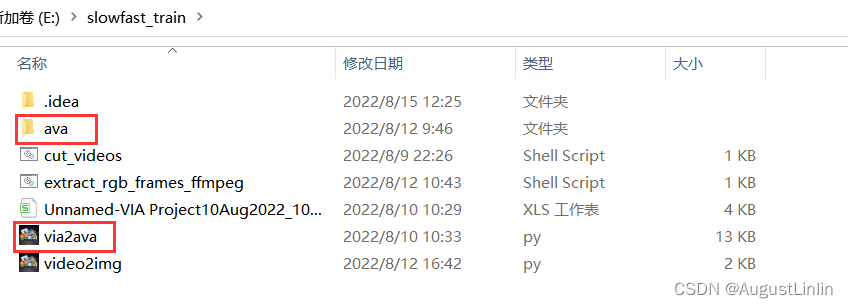
重点将代码中的“Unnamed-VIA Project13Jul2022_16h01m30s_export.csv”替换为你的csv文件名,然后执行python via2ava.py,此时会在ava/annotations目录下生成slowfast训练时所需的全部文件。
6. slowfast环境部署
MMAction2是一个视频理解工具箱,里面集成了各种动作识别算法,其中就有slowfast。自己实现各种算法不管是环境搭建还是数据集整理都太麻烦,所以mmaction2做了二次封装,统一了环境,简化了整理数据集难度。
conda create -n open-mmlab python=3.8
conda activate open-mmlab
conda install pytorch==1.8.0 torchvision==0.9.0 torchaudio==0.8.0 cudatoolkit=11.1 -c pytorch -c conda-forge
pip3 install mmcv-full -f https://download.openmmlab.com/mmcv/dist/cu111/torch1.8.0/index.html
git clone https://github.com/open-mmlab/mmaction2.git
cd mmaction2
pip3 install -e .
环境部署成功后,在mmaction2目录下创建data文件夹,然后将与via2ava.py脚本同目录下的ava文件夹放在data下。
7. 调整配置文件
进入mmaction2/configs/detection/ava目录,复制slowfast_kinetics_pretrained_r50_4x16x1_20e_ava_rgb.py文件改名为slowfast_kinetics_pretrained_demo_r50_4x16x1_20e_ava_rgb.py,配置文件内容如下:
# model setting
model = dict(
type='FastRCNN',
backbone=dict(
type='ResNet3dSlowFast',
pretrained=None,
resample_rate=8,
speed_ratio=8,
channel_ratio=8,
slow_pathway=dict(
type='resnet3d',
depth=50,
pretrained=None,
lateral=True,
conv1_kernel=(1, 7, 7),
dilations=(1, 1, 1, 1),
conv1_stride_t=1,
pool1_stride_t=1,
inflate=(0, 0, 1, 1),
spatial_strides=(1, 2, 2, 1)),
fast_pathway=dict(
type='resnet3d',
depth=50,
pretrained=None,
lateral=False,
base_channels=8,
conv1_kernel=(5, 7, 7),
conv1_stride_t=1,
pool1_stride_t=1,
spatial_strides=(1, 2, 2, 1))),
roi_head=dict(
type='AVARoIHead',
bbox_roi_extractor=dict(
type='SingleRoIExtractor3D',
roi_layer_type='RoIAlign',
output_size=8,
with_temporal_pool=True),
bbox_head=dict(
type='BBoxHeadAVA',
in_channels=2304,
num_classes=8,
topk=(1, 7),
multilabel=True,
dropout_ratio=0.5)),
train_cfg=dict(
rcnn=dict(
assigner=dict(
type='MaxIoUAssignerAVA',
pos_iou_thr=0.9,
neg_iou_thr=0.9,
min_pos_iou=0.9),
sampler=dict(
type='RandomSampler',
num=32,
pos_fraction=1,
neg_pos_ub=-1,
add_gt_as_proposals=True),
pos_weight=1.0,
debug=False)),
test_cfg=dict(rcnn=dict(action_thr=0.002)))
dataset_type = 'AVADataset'
data_root = '/home/wzhou/way/llwang/mmaction2-master/input/ava/rawframes'
anno_root = '/home/wzhou/way/llwang/mmaction2-master/input/ava/annotations'
ann_file_train = f'{anno_root}/ava_train_v2.1.csv'
ann_file_val = f'{anno_root}/ava_val_v2.1.csv'
exclude_file_train = f'{anno_root}/ava_train_excluded_timestamps_v2.1.csv'
exclude_file_val = f'{anno_root}/ava_val_excluded_timestamps_v2.1.csv'
label_file = f'{anno_root}/ava_action_list_v2.1.pbtxt'
proposal_file_train = (f'{anno_root}/ava_dense_proposals_train.FAIR.'
'recall_93.9.pkl')
proposal_file_val = f'{anno_root}/ava_dense_proposals_val.FAIR.recall_93.9.pkl'
img_norm_cfg = dict(
mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_bgr=False)
train_pipeline = [
dict(type='SampleAVAFrames', clip_len=32, frame_interval=2),
dict(type='RawFrameDecode'),
dict(type='RandomRescale', scale_range=(256, 320)),
dict(type='RandomCrop', size=256),
dict(type='Flip', flip_ratio=0.5),
dict(type='Normalize', **img_norm_cfg),
dict(type='FormatShape', input_format='NCTHW', collapse=True),
# Rename is needed to use mmdet detectors
dict(type='Rename', mapping=dict(imgs='img')),
dict(type='ToTensor', keys=['img', 'proposals', 'gt_bboxes', 'gt_labels']),
dict(
type='ToDataContainer',
fields=[
dict(key=['proposals', 'gt_bboxes', 'gt_labels'], stack=False)
]),
dict(
type='Collect',
keys=['img', 'proposals', 'gt_bboxes', 'gt_labels'],
meta_keys=['scores', 'entity_ids'])
]
# The testing is w/o. any cropping / flipping
val_pipeline = [
dict(
type='SampleAVAFrames', clip_len=32, frame_interval=2, test_mode=True),
dict(type='RawFrameDecode'),
dict(type='Resize', scale=(-1, 256)),
dict(type='Normalize', **img_norm_cfg),
dict(type='FormatShape', input_format='NCTHW', collapse=True),
# Rename is needed to use mmdet detectors
dict(type='Rename', mapping=dict(imgs='img')),
dict(type='ToTensor', keys=['img', 'proposals']),
dict(type='ToDataContainer', fields=[dict(key='proposals', stack=False)]),
dict(
type='Collect',
keys=['img', 'proposals'],
meta_keys=['scores', 'img_shape'],
nested=True)
]
data = dict(
videos_per_gpu=5,
workers_per_gpu=2,
val_dataloader=dict(videos_per_gpu=1),
test_dataloader=dict(videos_per_gpu=1),
train=dict(
type=dataset_type,
ann_file=ann_file_train,
exclude_file=exclude_file_train,
pipeline=train_pipeline,
label_file=label_file,
proposal_file=proposal_file_train,
person_det_score_thr=0.9,
num_classes=8,
start_index=1,
data_prefix=data_root),
val=dict(
type=dataset_type,
ann_file=ann_file_val,
exclude_file=exclude_file_val,
pipeline=val_pipeline,
label_file=label_file,
proposal_file=proposal_file_val,
person_det_score_thr=0.9,
num_classes=8,
start_index=1,
data_prefix=data_root))
data['test'] = data['val']
optimizer = dict(type='SGD', lr=0.1125, momentum=0.9, weight_decay=0.00001)
# this lr is used for 8 gpus
optimizer_config = dict(grad_clip=dict(max_norm=40, norm_type=2))
# learning policy
lr_config = dict(
policy='step',
step=[10, 15],
warmup='linear',
warmup_by_epoch=True,
warmup_iters=5,
warmup_ratio=0.1)
total_epochs = 200
checkpoint_config = dict(interval=1)
workflow = [('train', 1)]
evaluation = dict(interval=1, save_best='mAP@0.5IOU')
log_config = dict(
interval=20, hooks=[
dict(type='TextLoggerHook'),
])
dist_params = dict(backend='nccl')
log_level = 'INFO'
work_dir = ('./work_dirs/ava/'
'slowfast_kinetics_pretrained_r50_4x16x1_20e_ava_rgb')
load_from = ('https://download.openmmlab.com/mmaction/recognition/slowfast/'
'slowfast_r50_4x16x1_256e_kinetics400_rgb/'
'slowfast_r50_4x16x1_256e_kinetics400_rgb_20200704-bcde7ed7.pth')
resume_from = None
find_unused_parameters = False注意:
1、替换全部num_classes,我定义了7种行为,所以num_classes=8,要考虑__background__;
2、第42行topk=(1,7),1保持默认,7为行为的数量;
3、62-64行注意训练数据集的路径;
4、若训练过程中显存不够,修改第122行videos_per_gpu的数量;
5、第135、146行要加上start_index=1;
6、163行修改训练次数;
7、第175行load_from可使用预训练模型。
8. 开始训练
训练脚本在tools目录下,如果只有1个gpu,那么看一看train.py需要哪些参数,配置好以后python tools/train.py即可。
由于我有4张GPU训练,就使用了tools目录下的dist_train.sh脚本,进入mmaction2目录:
bash tools/dist_train.sh configs/detection/ava/slowfast_kinetics_pretrained_dog_r50_4x16x1_20e_ava_rgb.py 49. 训练效果
由于slowfast行为识别的前提,是先使用目标识别算法将物体框出来,所以想看训练结果,还需下载mmdetection进行目标识别。
进入mmaction2/demo目录,编辑webcam_demo_spatiotemporal_det.py,查看需要传入哪些参数。
# Copyright (c) OpenMMLab. All rights reserved.
"""Webcam Spatio-Temporal Action Detection Demo.
Some codes are based on https://github.com/facebookresearch/SlowFast
"""
import argparse
import atexit
import copy
import logging
import queue
import threading
import time
from abc import ABCMeta, abstractmethod
import cv2
import mmcv
import numpy as np
import torch
from mmcv import Config, DictAction
from mmcv.runner import load_checkpoint
from mmaction.models import build_detector
try:
from mmdet.apis import inference_detector, init_detector
except (ImportError, ModuleNotFoundError):
raise ImportError('Failed to import `inference_detector` and '
'`init_detector` form `mmdet.apis`. These apis are '
'required in this demo! ')
logging.basicConfig(level=logging.DEBUG)
logger = logging.getLogger(__name__)
def parse_args():
parser = argparse.ArgumentParser(
description='MMAction2 webcam spatio-temporal detection demo')
parser.add_argument(
'--config',
default=('/home/wzhou/way/llwang/mmaction2-master/configs/detection/ava/'
'slowfast_kinetics_pretrained_demo_r50_4x16x1_20e_ava_rgb.py'),
help='spatio temporal detection config file path')
parser.add_argument(
'--checkpoint',
default=('/home/wzhou/way/llwang/mmaction2-master/work_dirs/ava/slowfast_kinetics_pretrained_r50_4x16x1_20e_ava_rgb/'
'latest.pth'),
help='spatio temporal detection checkpoint file/url')
parser.add_argument(
'--action-score-thr',
type=float,
default=0.4,
help='the threshold of human action score')
parser.add_argument(
'--det-config',
default='/home/wzhou/way/llwang/mmaction2-master/demo/faster_rcnn_r50_fpn_2x_coco.py',
help='human detection config file path (from mmdet)')
parser.add_argument(
'--det-checkpoint',
default=('/home/wzhou/way/llwang/mmaction2-master/weights/'
'faster_rcnn_r50_fpn_2x_coco_bbox_mAP-0.384_20200504_210434-a5d8aa15.pth'),
help='human detection checkpoint file/url')
parser.add_argument(
'--det-score-thr',
type=float,
default=0.9,
help='the threshold of human detection score')
parser.add_argument(
'--input-video',
default='/home/wzhou/way/llwang/mmaction2-master/input/08093.mp4',
type=str,
help='webcam id or input video file/url')
parser.add_argument(
'--label-map',
default='/home/wzhou/way/llwang/mmaction2-master/tools/data/ava/label_map_demo.txt',
help='label map file')
parser.add_argument(
'--device', type=str, default='cuda:0', help='CPU/CUDA device option')
parser.add_argument(
'--output-fps',
default=15,
type=int,
help='the fps of demo video output')
parser.add_argument(
'--out-filename',
default='/home/wzhou/way/llwang/mmaction2-master/output/08093.mp4',
type=str,
help='the filename of output video')
parser.add_argument(
'--show',
action='store_true',
help='Whether to show results with cv2.imshow')
parser.add_argument(
'--display-height',
type=int,
default=0,
help='Image height for human detector and draw frames.')
parser.add_argument(
'--display-width',
type=int,
default=0,
help='Image width for human detector and draw frames.')
parser.add_argument(
'--predict-stepsize',
default=8,
type=int,
help='give out a prediction per n frames')
parser.add_argument(
'--clip-vis-length',
default=8,
type=int,
help='Number of draw frames per clip.')
parser.add_argument(
'--cfg-options',
nargs='+',
action=DictAction,
default={},
help='override some settings in the used config, the key-value pair '
'in xxx=yyy format will be merged into config file. For example, '
"'--cfg-options model.backbone.depth=18 model.backbone.with_cp=True'")
args = parser.parse_args()
return args
class TaskInfo:
"""Wapper for a clip.
Transmit input around three threads.
1) Read Thread: Create task and put task into read queue. Init `frames`,
`processed_frames`, `img_shape`, `ratio`, `clip_vis_length`.
2) Main Thread: Get input from read queue, predict human bboxes and stdet
action labels, draw predictions and put task into display queue. Init
`display_bboxes`, `stdet_bboxes` and `action_preds`, update `frames`.
3) Display Thread: Get input from display queue, show/write frames and
delete task.
"""
def __init__(self):
self.id = -1
# raw frames, used as human detector input, draw predictions input
# and output, display input
self.frames = None
# stdet params
self.processed_frames = None # model inputs
self.frames_inds = None # select frames from processed frames
self.img_shape = None # model inputs, processed frame shape
# `action_preds` is `list[list[tuple]]`. The outer brackets indicate
# different bboxes and the intter brackets indicate different action
# results for the same bbox. tuple contains `class_name` and `score`.
self.action_preds = None # stdet results
# human bboxes with the format (xmin, ymin, xmax, ymax)
self.display_bboxes = None # bboxes coords for self.frames
self.stdet_bboxes = None # bboxes coords for self.processed_frames
self.ratio = None # processed_frames.shape[1::-1]/frames.shape[1::-1]
# for each clip, draw predictions on clip_vis_length frames
self.clip_vis_length = -1
def add_frames(self, idx, frames, processed_frames):
"""Add the clip and corresponding id.
Args:
idx (int): the current index of the clip.
frames (list[ndarray]): list of images in "BGR" format.
processed_frames (list[ndarray]): list of resize and normed images
in "BGR" format.
"""
self.frames = frames
self.processed_frames = processed_frames
self.id = idx
self.img_shape = processed_frames[0].shape[:2]
def add_bboxes(self, display_bboxes):
"""Add correspondding bounding boxes."""
self.display_bboxes = display_bboxes
self.stdet_bboxes = display_bboxes.clone()
self.stdet_bboxes[:, ::2] = self.stdet_bboxes[:, ::2] * self.ratio[0]
self.stdet_bboxes[:, 1::2] = self.stdet_bboxes[:, 1::2] * self.ratio[1]
def add_action_preds(self, preds):
"""Add the corresponding action predictions."""
self.action_preds = preds
def get_model_inputs(self, device):
"""Convert preprocessed images to MMAction2 STDet model inputs."""
cur_frames = [self.processed_frames[idx] for idx in self.frames_inds]
input_array = np.stack(cur_frames).transpose((3, 0, 1, 2))[np.newaxis]
input_tensor = torch.from_numpy(input_array).to(device)
return dict(
return_loss=False,
img=[input_tensor],
proposals=[[self.stdet_bboxes]],
img_metas=[[dict(img_shape=self.img_shape)]])
class BaseHumanDetector(metaclass=ABCMeta):
"""Base class for Human Dector.
Args:
device (str): CPU/CUDA device option.
"""
def __init__(self, device):
self.device = torch.device(device)
@abstractmethod
def _do_detect(self, image):
"""Get human bboxes with shape [n, 4].
The format of bboxes is (xmin, ymin, xmax, ymax) in pixels.
"""
def predict(self, task):
"""Add keyframe bboxes to task."""
# keyframe idx == (clip_len * frame_interval) // 2
keyframe = task.frames[len(task.frames) // 2]
# call detector
bboxes = self._do_detect(keyframe)
# convert bboxes to torch.Tensor and move to target device
if isinstance(bboxes, np.ndarray):
bboxes = torch.from_numpy(bboxes).to(self.device)
elif isinstance(bboxes, torch.Tensor) and bboxes.device != self.device:
bboxes = bboxes.to(self.device)
# update task
task.add_bboxes(bboxes)
return task
class MmdetHumanDetector(BaseHumanDetector):
"""Wrapper for mmdetection human detector.
Args:
config (str): Path to mmdetection config.
ckpt (str): Path to mmdetection checkpoint.
device (str): CPU/CUDA device option.
score_thr (float): The threshold of human detection score.
person_classid (int): Choose class from detection results.
Default: 0. Suitable for COCO pretrained models.
"""
def __init__(self, config, ckpt, device, score_thr, person_classid=0):
super().__init__(device)
self.model = init_detector(config, ckpt, device)
self.person_classid = person_classid
self.score_thr = score_thr
def _do_detect(self, image):
"""Get bboxes in shape [n, 4] and values in pixels."""
result = inference_detector(self.model, image)[self.person_classid]
result = result[result[:, 4] >= self.score_thr][:, :4]
return result
class StdetPredictor:
"""Wrapper for MMAction2 spatio-temporal action models.
Args:
config (str): Path to stdet config.
ckpt (str): Path to stdet checkpoint.
device (str): CPU/CUDA device option.
score_thr (float): The threshold of human action score.
label_map_path (str): Path to label map file. The format for each line
is `{class_id}: {class_name}`.
"""
def __init__(self, config, checkpoint, device, score_thr, label_map_path):
self.score_thr = score_thr
# load model
config.model.backbone.pretrained = None
model = build_detector(config.model, test_cfg=config.get('test_cfg'))
load_checkpoint(model, checkpoint, map_location='cpu')
model.to(device)
model.eval()
self.model = model
self.device = device
# init label map, aka class_id to class_name dict
with open(label_map_path) as f:
lines = f.readlines()
lines = [x.strip().split(': ') for x in lines]
self.label_map = {int(x[0]): x[1] for x in lines}
try:
if config['input']['train']['custom_classes'] is not None:
self.label_map = {
id + 1: self.label_map[cls]
for id, cls in enumerate(config['input']['train']
['custom_classes'])
}
except KeyError:
pass
def predict(self, task):
"""Spatio-temporval Action Detection model inference."""
# No need to do inference if no one in keyframe
if len(task.stdet_bboxes) == 0:
return task
with torch.no_grad():
result = self.model(**task.get_model_inputs(self.device))[0]
# pack results of human detector and stdet
preds = []
for _ in range(task.stdet_bboxes.shape[0]):
preds.append([])
for class_id in range(len(result)):
if class_id + 1 not in self.label_map:
continue
for bbox_id in range(task.stdet_bboxes.shape[0]):
if result[class_id][bbox_id, 4] > self.score_thr:
preds[bbox_id].append((self.label_map[class_id + 1],
result[class_id][bbox_id, 4]))
# update task
# `preds` is `list[list[tuple]]`. The outer brackets indicate
# different bboxes and the intter brackets indicate different action
# results for the same bbox. tuple contains `class_name` and `score`.
task.add_action_preds(preds)
return task
class ClipHelper:
"""Multithrading utils to manage the lifecycle of task."""
def __init__(self,
config,
display_height=0,
display_width=0,
input_video=0,
predict_stepsize=40,
output_fps=25,
clip_vis_length=8,
out_filename=None,
show=True,
stdet_input_shortside=256):
# stdet sampling strategy
val_pipeline = config.data.val.pipeline
sampler = [x for x in val_pipeline
if x['type'] == 'SampleAVAFrames'][0]
clip_len, frame_interval = sampler['clip_len'], sampler[
'frame_interval']
self.window_size = clip_len * frame_interval
# asserts
assert (out_filename or show), \
'out_filename and show cannot both be None'
assert clip_len % 2 == 0, 'We would like to have an even clip_len'
assert clip_vis_length <= predict_stepsize
assert 0 < predict_stepsize <= self.window_size
# source params
try:
self.cap = cv2.VideoCapture(int(input_video))
self.webcam = True
except ValueError:
self.cap = cv2.VideoCapture(input_video)
self.webcam = False
assert self.cap.isOpened()
# stdet input preprocessing params
h = int(self.cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
w = int(self.cap.get(cv2.CAP_PROP_FRAME_WIDTH))
self.stdet_input_size = mmcv.rescale_size(
(w, h), (stdet_input_shortside, np.Inf))
img_norm_cfg = config['img_norm_cfg']
if 'to_rgb' not in img_norm_cfg and 'to_bgr' in img_norm_cfg:
to_bgr = img_norm_cfg.pop('to_bgr')
img_norm_cfg['to_rgb'] = to_bgr
img_norm_cfg['mean'] = np.array(img_norm_cfg['mean'])
img_norm_cfg['std'] = np.array(img_norm_cfg['std'])
self.img_norm_cfg = img_norm_cfg
# task init params
self.clip_vis_length = clip_vis_length
self.predict_stepsize = predict_stepsize
self.buffer_size = self.window_size - self.predict_stepsize
frame_start = self.window_size // 2 - (clip_len // 2) * frame_interval
self.frames_inds = [
frame_start + frame_interval * i for i in range(clip_len)
]
self.buffer = []
self.processed_buffer = []
# output/display params
if display_height > 0 and display_width > 0:
self.display_size = (display_width, display_height)
elif display_height > 0 or display_width > 0:
self.display_size = mmcv.rescale_size(
(w, h), (np.Inf, max(display_height, display_width)))
else:
self.display_size = (w, h)
self.ratio = tuple(
n / o for n, o in zip(self.stdet_input_size, self.display_size))
if output_fps <= 0:
self.output_fps = int(self.cap.get(cv2.CAP_PROP_FPS))
else:
self.output_fps = output_fps
self.show = show
self.video_writer = None
if out_filename is not None:
self.video_writer = self.get_output_video_writer(out_filename)
display_start_idx = self.window_size // 2 - self.predict_stepsize // 2
self.display_inds = [
display_start_idx + i for i in range(self.predict_stepsize)
]
# display multi-theading params
self.display_id = -1 # task.id for display queue
self.display_queue = {}
self.display_lock = threading.Lock()
self.output_lock = threading.Lock()
# read multi-theading params
self.read_id = -1 # task.id for read queue
self.read_id_lock = threading.Lock()
self.read_queue = queue.Queue()
self.read_lock = threading.Lock()
self.not_end = True # cap.read() flag
# program state
self.stopped = False
atexit.register(self.clean)
def read_fn(self):
"""Main function for read thread.
Contains three steps:
1) Read and preprocess (resize + norm) frames from source.
2) Create task by frames from previous step and buffer.
3) Put task into read queue.
"""
was_read = True
start_time = time.time()
while was_read and not self.stopped:
# init task
task = TaskInfo()
task.clip_vis_length = self.clip_vis_length
task.frames_inds = self.frames_inds
task.ratio = self.ratio
# read buffer
frames = []
processed_frames = []
if len(self.buffer) != 0:
frames = self.buffer
if len(self.processed_buffer) != 0:
processed_frames = self.processed_buffer
# read and preprocess frames from source and update task
with self.read_lock:
before_read = time.time()
read_frame_cnt = self.window_size - len(frames)
while was_read and len(frames) < self.window_size:
was_read, frame = self.cap.read()
if not self.webcam:
# Reading frames too fast may lead to unexpected
# performance degradation. If you have enough
# resource, this line could be commented.
time.sleep(1 / self.output_fps)
if was_read:
frames.append(mmcv.imresize(frame, self.display_size))
processed_frame = mmcv.imresize(
frame, self.stdet_input_size).astype(np.float32)
_ = mmcv.imnormalize_(processed_frame,
**self.img_norm_cfg)
processed_frames.append(processed_frame)
task.add_frames(self.read_id + 1, frames, processed_frames)
# update buffer
if was_read:
self.buffer = frames[-self.buffer_size:]
self.processed_buffer = processed_frames[-self.buffer_size:]
# update read state
with self.read_id_lock:
self.read_id += 1
self.not_end = was_read
self.read_queue.put((was_read, copy.deepcopy(task)))
cur_time = time.time()
logger.debug(
f'Read thread: {1000*(cur_time - start_time):.0f} ms, '
f'{read_frame_cnt / (cur_time - before_read):.0f} fps')
start_time = cur_time
def display_fn(self):
"""Main function for display thread.
Read input from display queue and display predictions.
"""
start_time = time.time()
while not self.stopped:
# get the state of the read thread
with self.read_id_lock:
read_id = self.read_id
not_end = self.not_end
with self.display_lock:
# If video ended and we have display all frames.
if not not_end and self.display_id == read_id:
break
# If the next task are not available, wait.
if (len(self.display_queue) == 0 or
self.display_queue.get(self.display_id + 1) is None):
time.sleep(0.02)
continue
# get display input and update state
self.display_id += 1
was_read, task = self.display_queue[self.display_id]
del self.display_queue[self.display_id]
display_id = self.display_id
# do display predictions
with self.output_lock:
if was_read and task.id == 0:
# the first task
cur_display_inds = range(self.display_inds[-1] + 1)
elif not was_read:
# the last task
cur_display_inds = range(self.display_inds[0],
len(task.frames))
else:
cur_display_inds = self.display_inds
for frame_id in cur_display_inds:
frame = task.frames[frame_id]
if self.show:
cv2.imshow('Demo', frame)
cv2.waitKey(int(1000 / self.output_fps))
if self.video_writer:
self.video_writer.write(frame)
cur_time = time.time()
logger.debug(
f'Display thread: {1000*(cur_time - start_time):.0f} ms, '
f'read id {read_id}, display id {display_id}')
start_time = cur_time
def __iter__(self):
return self
def __next__(self):
"""Get input from read queue.
This function is part of the main thread.
"""
if self.read_queue.qsize() == 0:
time.sleep(0.02)
return not self.stopped, None
was_read, task = self.read_queue.get()
if not was_read:
# If we reach the end of the video, there aren't enough frames
# in the task.processed_frames, so no need to model inference
# and draw predictions. Put task into display queue.
with self.read_id_lock:
read_id = self.read_id
with self.display_lock:
self.display_queue[read_id] = was_read, copy.deepcopy(task)
# main thread doesn't need to handle this task again
task = None
return was_read, task
def start(self):
"""Start read thread and display thread."""
self.read_thread = threading.Thread(
target=self.read_fn, args=(), name='VidRead-Thread', daemon=True)
self.read_thread.start()
self.display_thread = threading.Thread(
target=self.display_fn,
args=(),
name='VidDisplay-Thread',
daemon=True)
self.display_thread.start()
return self
def clean(self):
"""Close all threads and release all resources."""
self.stopped = True
self.read_lock.acquire()
self.cap.release()
self.read_lock.release()
self.output_lock.acquire()
cv2.destroyAllWindows()
if self.video_writer:
self.video_writer.release()
self.output_lock.release()
def join(self):
"""Waiting for the finalization of read and display thread."""
self.read_thread.join()
self.display_thread.join()
def display(self, task):
"""Add the visualized task to the display queue.
Args:
task (TaskInfo object): task object that contain the necessary
information for prediction visualization.
"""
with self.display_lock:
self.display_queue[task.id] = (True, task)
def get_output_video_writer(self, path):
"""Return a video writer object.
Args:
path (str): path to the output video file.
"""
return cv2.VideoWriter(
filename=path,
fourcc=cv2.VideoWriter_fourcc(*'mp4v'),
fps=float(self.output_fps),
frameSize=self.display_size,
isColor=True)
class BaseVisualizer(metaclass=ABCMeta):
"""Base class for visualization tools."""
def __init__(self, max_labels_per_bbox):
self.max_labels_per_bbox = max_labels_per_bbox
def draw_predictions(self, task):
"""Visualize stdet predictions on raw frames."""
# read bboxes from task
bboxes = task.display_bboxes.cpu().numpy()
# draw predictions and update task
keyframe_idx = len(task.frames) // 2
draw_range = [
keyframe_idx - task.clip_vis_length // 2,
keyframe_idx + (task.clip_vis_length - 1) // 2
]
assert draw_range[0] >= 0 and draw_range[1] < len(task.frames)
task.frames = self.draw_clip_range(task.frames, task.action_preds,
bboxes, draw_range)
return task
def draw_clip_range(self, frames, preds, bboxes, draw_range):
"""Draw a range of frames with the same bboxes and predictions."""
# no predictions to be draw
if bboxes is None or len(bboxes) == 0:
return frames
# draw frames in `draw_range`
left_frames = frames[:draw_range[0]]
right_frames = frames[draw_range[1] + 1:]
draw_frames = frames[draw_range[0]:draw_range[1] + 1]
# get labels(texts) and draw predictions
draw_frames = [
self.draw_one_image(frame, bboxes, preds) for frame in draw_frames
]
return list(left_frames) + draw_frames + list(right_frames)
@abstractmethod
def draw_one_image(self, frame, bboxes, preds):
"""Draw bboxes and corresponding texts on one frame."""
@staticmethod
def abbrev(name):
"""Get the abbreviation of label name:
'take (an object) from (a person)' -> 'take ... from ...'
"""
while name.find('(') != -1:
st, ed = name.find('('), name.find(')')
name = name[:st] + '...' + name[ed + 1:]
return name
class DefaultVisualizer(BaseVisualizer):
"""Tools to visualize predictions.
Args:
max_labels_per_bbox (int): Max number of labels to visualize for a
person box. Default: 5.
plate (str): The color plate used for visualization. Two recommended
plates are blue plate `03045e-023e8a-0077b6-0096c7-00b4d8-48cae4`
and green plate `004b23-006400-007200-008000-38b000-70e000`. These
plates are generated by https://coolors.co/.
Default: '03045e-023e8a-0077b6-0096c7-00b4d8-48cae4'.
text_fontface (int): Fontface from OpenCV for texts.
Default: cv2.FONT_HERSHEY_DUPLEX.
text_fontscale (float): Fontscale from OpenCV for texts.
Default: 0.5.
text_fontcolor (tuple): fontface from OpenCV for texts.
Default: (255, 255, 255).
text_thickness (int): Thickness from OpenCV for texts.
Default: 1.
text_linetype (int): LInetype from OpenCV for texts.
Default: 1.
"""
def __init__(
self,
max_labels_per_bbox=5,
plate='03045e-023e8a-0077b6-0096c7-00b4d8-48cae4',
text_fontface=cv2.FONT_HERSHEY_DUPLEX,
text_fontscale=0.5,
text_fontcolor=(255, 255, 255), # white
text_thickness=1,
text_linetype=1):
super().__init__(max_labels_per_bbox=max_labels_per_bbox)
self.text_fontface = text_fontface
self.text_fontscale = text_fontscale
self.text_fontcolor = text_fontcolor
self.text_thickness = text_thickness
self.text_linetype = text_linetype
def hex2color(h):
"""Convert the 6-digit hex string to tuple of 3 int value (RGB)"""
return (int(h[:2], 16), int(h[2:4], 16), int(h[4:], 16))
plate = plate.split('-')
self.plate = [hex2color(h) for h in plate]
def draw_one_image(self, frame, bboxes, preds):
"""Draw predictions on one image."""
for bbox, pred in zip(bboxes, preds):
# draw bbox
box = bbox.astype(np.int64)
st, ed = tuple(box[:2]), tuple(box[2:])
cv2.rectangle(frame, st, ed, (0, 0, 255), 2)
# draw texts
for k, (label, score) in enumerate(pred):
if k >= self.max_labels_per_bbox:
break
text = f'{self.abbrev(label)}: {score:.4f}'
location = (0 + st[0], 18 + k * 18 + st[1])
textsize = cv2.getTextSize(text, self.text_fontface,
self.text_fontscale,
self.text_thickness)[0]
textwidth = textsize[0]
diag0 = (location[0] + textwidth, location[1] - 14)
diag1 = (location[0], location[1] + 2)
cv2.rectangle(frame, diag0, diag1, self.plate[k + 1], -1)
cv2.putText(frame, text, location, self.text_fontface,
self.text_fontscale, self.text_fontcolor,
self.text_thickness, self.text_linetype)
return frame
def main(args):
# init human detector
human_detector = MmdetHumanDetector(args.det_config, args.det_checkpoint,
args.device, args.det_score_thr)
# init action detector
config = Config.fromfile(args.config)
config.merge_from_dict(args.cfg_options)
try:
# In our spatiotemporal detection demo, different actions should have
# the same number of bboxes.
config['model']['test_cfg']['rcnn']['action_thr'] = .0
except KeyError:
pass
stdet_predictor = StdetPredictor(
config=config,
checkpoint=args.checkpoint,
device=args.device,
score_thr=args.action_score_thr,
label_map_path=args.label_map)
# init clip helper
clip_helper = ClipHelper(
config=config,
display_height=args.display_height,
display_width=args.display_width,
input_video=args.input_video,
predict_stepsize=args.predict_stepsize,
output_fps=args.output_fps,
clip_vis_length=args.clip_vis_length,
out_filename=args.out_filename,
show=args.show)
# init visualizer
vis = DefaultVisualizer()
# start read and display thread
clip_helper.start()
try:
# Main thread main function contains:
# 1) get input from read queue
# 2) get human bboxes and stdet predictions
# 3) draw stdet predictions and update task
# 4) put task into display queue
for able_to_read, task in clip_helper:
# get input from read queue
if not able_to_read:
# read thread is dead and all tasks are processed
break
if task is None:
# when no input in read queue, wait
time.sleep(0.01)
continue
inference_start = time.time()
# get human bboxes
human_detector.predict(task)
# get stdet predictions
stdet_predictor.predict(task)
# draw stdet predictions in raw frames
vis.draw_predictions(task)
logger.info(f'Stdet Results: {task.action_preds}')
# add draw frames to display queue
clip_helper.display(task)
logger.debug('Main thread inference time '
f'{1000*(time.time() - inference_start):.0f} ms')
# wait for display thread
clip_helper.join()
except KeyboardInterrupt:
pass
finally:
# close read & display thread, release all resources
clip_helper.clean()
if __name__ == '__main__':
main(parse_args())
--config为slowfast训练狗的配置文件
--checkpoint为slowfast训练得到的权重
--det-config为mmdetection的配置文件
--det-checkpoint为mmdetection的权重文件
然后执行该脚本,查看识别结果。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









