






数据集介绍
https://github.com/facebookresearch/SlowFast/blob/main/projects/pytorchvideo/README.md
PyTorchVideo数据集包括
Kinetics
Kinetics数据集下载 https://www.deepmind.com/open-source/kinetics
Charades
Something-something v2
三个数据集
1.首先安装完环境
2.然后准备数据集
https://github.com/facebookresearch/SlowFast/blob/main/slowfast/datasets/DATASET.md
然后运行
python tools/run_net.py --cfg configs/Kinetics/C2D_8x8_R50.yaml DATA.PATH_TO_DATA_DIR /ActivityNet/Crawler/Kinetics/data/kinetics-400_train.csv NUM_GPUS 1 TRAIN.BATCH_SIZE 16
这里我们尝试AVA数据集进行训练
首先要准备数据集
https://github.com/facebookresearch/SlowFast/blob/main/slowfast/datasets/DATASET.md
2.1然后运行脚本下载
(数据在./data/ava/videos下)
DATA_DIR="./data/ava/videos"
if [[ ! -d "${DATA_DIR}" ]]; then
echo "${DATA_DIR} doesn't exist. Creating it.";
mkdir -p ${DATA_DIR}
fi
wget https://s3.amazonaws.com/ava-dataset/annotations/ava_file_names_trainval_v2.1.txt
for line in $(cat ava_file_names_trainval_v2.1.txt)
do
wget https://s3.amazonaws.com/ava-dataset/trainval/$line -P ${DATA_DIR}
done
如果运行过程中报错
[[: not found
是因为sh命令无法识别"[[]]"表达式。改为用./ 来替代sh执行
2.2裁剪每个视频的第15分钟到30分钟
IN_DATA_DIR="./data/ava/videos"
OUT_DATA_DIR="./data/ava/videos_15min"
if [[ ! -d "${OUT_DATA_DIR}" ]]; then
echo "${OUT_DATA_DIR} doesn't exist. Creating it.";
mkdir -p ${OUT_DATA_DIR}
fi
for video in $(ls -A1 -U ${IN_DATA_DIR}/*)
do
out_name="${OUT_DATA_DIR}/${video##*/}"
if [ ! -f "${out_name}" ]; then
ffmpeg -ss 900 -t 901 -i "${video}" "${out_name}"
fi
done
2.3将视频提取为图片帧
IN_DATA_DIR="./data/ava/videos_15min"
OUT_DATA_DIR="./data/ava/frames"
if [[ ! -d "${OUT_DATA_DIR}" ]]; then
echo "${OUT_DATA_DIR} doesn't exist. Creating it.";
mkdir -p ${OUT_DATA_DIR}
fi
for video in $(ls -A1 -U ${IN_DATA_DIR}/*)
do
video_name=${video##*/}
if [[ $video_name = *".webm" ]]; then
video_name=${video_name::-5}
else
video_name=${video_name::-4}
fi
out_video_dir=${OUT_DATA_DIR}/${video_name}/
mkdir -p "${out_video_dir}"
out_name="${out_video_dir}/${video_name}_%06d.jpg"
ffmpeg -i "${video}" -r 30 -q:v 1 "${out_name}"
done
2.4下载annotations
DATA_DIR="./data/ava/annotations"
if [[ ! -d "${DATA_DIR}" ]]; then
echo "${DATA_DIR} doesn't exist. Creating it.";
mkdir -p ${DATA_DIR}
fi
wget https://research.google.com/ava/download/ava_train_v2.1.csv -P ${DATA_DIR}
wget https://research.google.com/ava/download/ava_val_v2.1.csv -P ${DATA_DIR}
wget https://research.google.com/ava/download/ava_action_list_v2.1_for_activitynet_2018.pbtxt -P ${DATA_DIR}
wget https://research.google.com/ava/download/ava_train_excluded_timestamps_v2.1.csv -P ${DATA_DIR}
wget https://research.google.com/ava/download/ava_val_excluded_timestamps_v2.1.csv -P ${DATA_DIR}
2.5新建frame_lits目录下载train.csv和val.csv
wget https://dl.fbaipublicfiles.com/video-long-term-feature-banks/data/ava/frame_lists/train.csv
wget https://dl.fbaipublicfiles.com/video-long-term-feature-banks/data/ava/frame_lists/val.csv
准备完数据之后运行
预训练模型记得下载
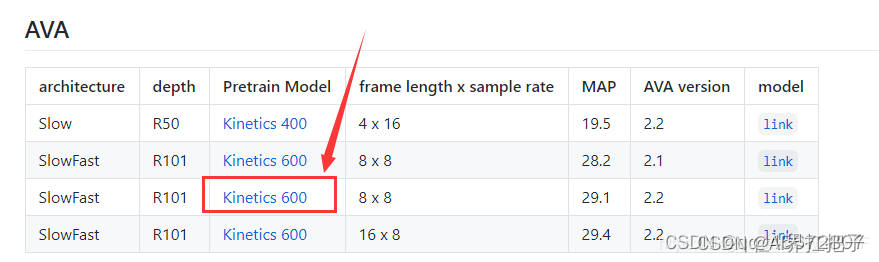
python tool/run_net.py --cfg configs/AVA/SLOWFAST_32x2_R50_SHORT5.yaml
如果报错
RuntimeError: CUDA error: invalid device ordinal
CUDA kernel errors might be asynchronously reported at some other API call,so the stacktrace below might be incorrect.
For debugging consider passing CUDA_LAUNCH_BLOCKING=1.
将yaml修改为
NUM_GPUS: 1 #8
参考文献
https://mp.weixin.qq.com/s?__biz=MzI4MDYzNzg4Mw==&mid=2247553678&idx=5&sn=d556f7c9be6b48c3f3ab199b0c855c5b&chksm=ebb72a5adcc0a34c0ed14e9366055ce455ef9560f4b4ec9f1460d414be1c44ab1231534199bb&scene=27















 3016
3016











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









