







 博主在使用随机森林进行泰坦尼克数据集分类时遇到困惑,经过处理'Embarked', 'Sex'列后,模型预测精确度显示为100%,认为这一结果不正常并寻求帮助,附带了代码和数据集信息。"
77435292,6883869,使用PHP GD库创建位图,"['PHP', 'GD库', 'Apache', '服务器配置', '图像处理']
博主在使用随机森林进行泰坦尼克数据集分类时遇到困惑,经过处理'Embarked', 'Sex'列后,模型预测精确度显示为100%,认为这一结果不正常并寻求帮助,附带了代码和数据集信息。"
77435292,6883869,使用PHP GD库创建位图,"['PHP', 'GD库', 'Apache', '服务器配置', '图像处理']
呃,一定是哪里错了。各位大侠有空帮忙看看,这是不太可能的结果啊。我把码贴下面了啊。
data_test_target = pd.read_csv(r"C:\Database\Titanic_Machine Learning from Disaster\gender_submission.csv")
data_test_m = pd.merge(data_test, data_test_target, how = 'left')
data_test_m.head(10)
out:
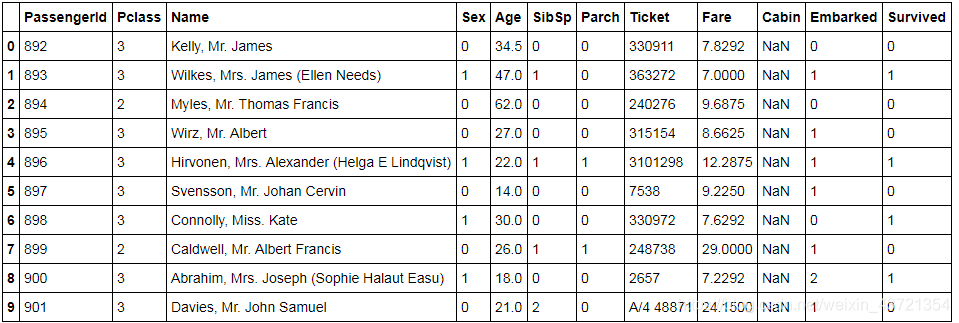
就是泰坦尼克那个数据集,对‘Embarked’, 'Sex’列的数据做了处理。数据集总样本数 = 418
predictors_test = ['Sex', 'Age', 'SibSp','Parch', 'Fare', 'Embarked','Pclass']
alg_R = RandomForestClassifier(n_estimators = 50, min_samples_split=4, min_samples_leaf=2, random_state=1)
kf = KFold(n_splits=8, random_state=1)
scores_Test = cross_val_score(alg_R, data_test_m[predictors_test], data_test_m['Survived'], cv=kf)
print(scores_Test)
print('-----------------')
print(scores_Test.mean())

图片为证啊,怎么跑,的出来的精确度结果都是100%。大神帮我看看。哪里出问题啦??
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









